PROJET – Dream Nebula, VMWare KPI Partie 1 : Théorie
Expression du besoin
Des outils qui permettent de réaliser un suivie de la charge d’une infrastructure il en existe un certain nombre. J’ai donc ce besoin de suivre mon SI1 et de définir de manière simple pour l’instant un planning de capacité de mon environnement VMWare qu’il soit basé sur une architecture standalone ou distribuée.
Toutefois, ce qui est emmerdant encore et toujours c’est le cout lié à ces solutions. Logique, car cela demande un certain recul et analyse et d’être flexible aux diverses solutions des éditeurs de virtualisation. Coucou VEEAMOne 🙂 Il existe aussi des solutions gratuites mais cela nécessite de manipuler ensuite les données retournées. Oui je pense à toi mon bon vieux RVTools.
De mon expérience d’administrateur système et réseau, j’ai constaté (comme je me suis fait avoir d’ailleurs) un manque crucial des équipes à tenir comptes des ressources matériels de leurs infrastructures. Que ce soient des jeunes loups qui viennent d’entrer sur le marché du travail ou de certains vieux loups charlot qui opère encore dans le milieu… C’est ainsi que les problématiques de surallocation des ressources voient le jour :
- Memory Balloning
- Storage Overprovisionned
- Storage Latency
- CPU Exhausted
- etc
Dans la grande majorité des cas, un suivi fin de l’exploitation permet d’éviter ce genre de cas de figure et dans d’autres cas de prévenir sa direction ou son client d’une évolution d’infrastructure à budgéter. L’une de mes bonnes pratiques (surtout celle que mes mentors m’ont transmises) et de prendre le SI de production et de prendre 20% de plus pour se prémunir des potentiels changements à venir et garder de l’évolutivité.
L’extraction des indicateurs de performance du SI permettra ainsi sur le plan technique de s’assurer de la charge et allocation de chacune des ressources matérielles et de définir l’allocation des ressources par services au plus bas niveau. Sur le plan financier et administratif cela permet de prévoir les investissements du SI tout comme il permet de refacturer en interne différents services. Derniers points qui peut-être marque d’espièglerie, la DSI2 ou Direction peut se rendre compte des conseils et des compétences du RSI3.
Dans le contexte d’un petit fournisseur de service (je ne parle pas des OVH, AWS et autres mastodontes), il est difficile de facturer les ressources aux clients de la manière la plus juste possible sans tomber dans le cas de surfacturation ou sou facturation. Ces indicateurs permettent donc de justifier le cout et l’évolution des ressources mis à leurs dispositions sur leurs demandes.
Il est donc nécessaire de trouver une solution qui permet d’assurer un suivie de l’infrastructure sur une durée défini qui puisse être orienté MSP4 comme pour un client final. D’assurer une visibilité macroscopique jusqu’au plus bas niveau des ressources. Tout comme pour l’article précédent GreenRay, il est important de décorréler la partie métrique et son rendu. Le service qualité doit pouvoir exploiter et présenter les métriques dans la plus grande transparence et honnêteté qu’il soit. (Surtout c’est le boulot de la qualité de rendre sexy un truc qui de base ne l’est pas trop, sauf pour les AdminSys dans mon genre 🙂 ).
Cahier des Charges
Ok, on voit où l’on veut aller. Pensons maintenant à partir de ce qui est établi comment mettre en œuvre tout ça sans tomber dans l’éternelle piège de la dispersion et donc de ne voir aboutir ce projet. Encore une fois, mon esprit aura fait des siennes et le projet au final va comporter des fonctionnalités encore en cours de développement… Oui je suis comme ça et je ne compte pas changer dans le cadre de mes loisirs.
Nous resterons dans un premier temps sur le socle de virtualisation VMware (et ce même si BROADCOM est passé par là avec son chéquier) et les produits vSphere de base (comprendre VCSA et ESXi) et donc son API5. (Donnez moi le moyen de faire cela pour les socles de virtualisation PROXMOX, AHV et HyperV, JE VOUS SUIS !).
Je souhaite également utiliser la solution VEEAMOne pour bénéficier de la gestion des TAGS de manière automatique dans l’environnement VMware. L’aillant déjà déployé et configuré (cf le billet en question), autant en profité. Ce point est optionnel et nous pouvons nous passer de ce dernier. Il est tout à fait possible d’administrer les TAGS directement dans l’environnement vCenter.
Pourquoi tu parles de TAGS ?
Les TAGS ou marqueurs vont me permettre d’identifier les ressources virtuelles. Par exemple d’identifier les ressources virtuelles propres au bon fonctionnement de l’infrastructure et les ressources virtuelles propres à la production et donc au bon fonctionnement de l’organisation. Cela permet d’avoir un ratio Production/Infrastructure.
Il en va ainsi de même pour les services IaaS6, SaaS7 et pourquoi pas par environnement de service, réseau ou clients (dans le cas d’un MSP).
Les TAGs permettront d’apporter une finesse dans l’analytique.
Si nous faisons une petite synthèse, la solution doit pouvoir se connecter à l’API VCSA8 by VMware. De nouveau la question, quel langage utilisé ? JE TE CHOISIS ! Framework .Net avec powershell afin d’établir un mode manuel et un mode service. Certes pas esthétique mais avons-nous réellement besoin d’une interface GUI9 pour l’instant ? Naturellement, il est obligatoire que la solution laisse une trace de son exécution dans un fichier et ce à des fins de debug et de contrôle.
L’outil comportant un mode service, ce dernier doit être planifié de manière journalière pour traiter le point de suivi des métriques sur une durée donnée.
Les données seront stockées dans une base de données flexible et légère qui puisse être utilisé en dehors de la production et s’interfacer rapidement avec tous types de systèmes. Je propose d’utiliser SQLite3.
Concernant la partie exploitation et génération des métriques, j’ai pris parti d’utiliser PowerPI pour des raisons de praticité et de gain de temps. J’avais par le passé compiler les informations dans un fichier excel mais force est de constater que la solution n’est pas viable dans le temps en termes de gestion. L’avantage d’une BDD10 comme source de données et qu’elle reste interfaçable avec tous types de solutions (Web, Application lourde ou encore et toujours le terrible tableur Excel).
Pour la partie sécurité, nous resterons concernant la consultation des données VMware sur un compte restreint en lecture seul (pas besoin de plus et encore on peut affiner les droits de manière drastique). Quant à l’exécution de la tâche planifiée dédiée au mode service un compte gMSA11 répondra à toutes les problématiques (dans le cas d’un poste joint à un domaine), sinon cela un compte local restreint. J’oubliais également que les informations d’identification seront chiffrées nativement par le SE12 Windows dans le contexte d’exécution du poste et de la session.
En conclusion de notre liste de course, notre application utilisera :
- Connecteur API à l’Appliance VCSA VMware
- Orienté MSP et SI finaux
- Couvrir les architectures standalone et distribuée
- Suivre les ressources virtualisées
- Suivre les ressources matérielles
- Langage de développement & Fonctionnalités
- .NET Framwork à travers Powershell (v5 ou plus)
- Journalisation de l’exécution du code
- Export des données en CSV et HTLM
- Mode manuel et mode service
- Fichier de configuration
- Aide au déploiement
- Visualisation en mode CLI
- SGBD
- SQLite3
- Reporting
- Microsoft PowerBI
- Securité
- Si poste au domaine, création et utilisation d’un compte de service gMSA dédiéSi hors domaine, création d’un compte restreint au poste
- Chiffrement des données d’authentification par les algorithmes natives Windows
- Token API en lecture seule sur la VCSA
Il est temps de passer à la construction et définissions de nos différents niveaux de topographie d’architecture, applicative et logiciel.
Topographie – Infrastructure
La topographie a été pensé pour être la plus simple et standard (pour faciliter la gestion et l’évolution de l’application). J’ai fait le choix de tout embarqué dans l’application, mais il est toutefois possible de mettre en place une architecture 2 ou 3 tiers en dissociant les parties Engine, Reporting et BDD.
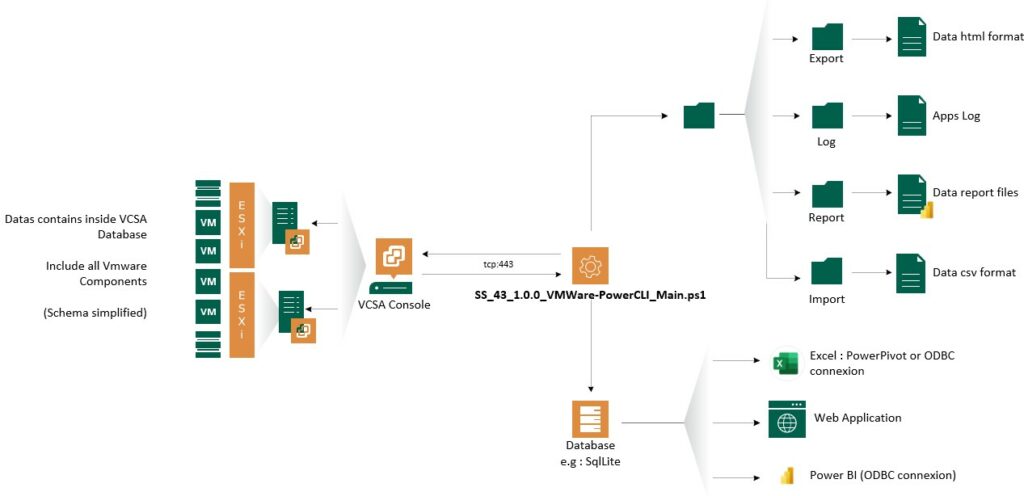
En d’autres termes, il est seulement nécessaire dans le cadre d’une architecture 1 tiers d’autoriser la communication des flux https/tcp entre l’appliance vCenter et notre application.
Topographie – Applicative
Depuis mon dernier gros projet, je suis désolé de vous apprendre que je ne suis toujours pas architecte applicatif. Renseignez vous, à l’agence des amants de Madame Müller, j’ai des restes !
A la racine du répertoire, nous retrouvons les deux fichiers exécutables :
- SS_43_1.0.0_VMWare-PowerCLI_Main.ps1 : Qui est le fichier d’instanciation de la solution est qui permet également de réaliser toutes les actions en mode manuel.
- SS_43_1.0.0_VMWAre-PowerCLI_Services.ps1 : Presque le même fichier que le fichier Main mais dédié au mode service avec un code adapté. Il ne peut être exécuté si et seulement si l’instanciation et initialisation à eu lieu.
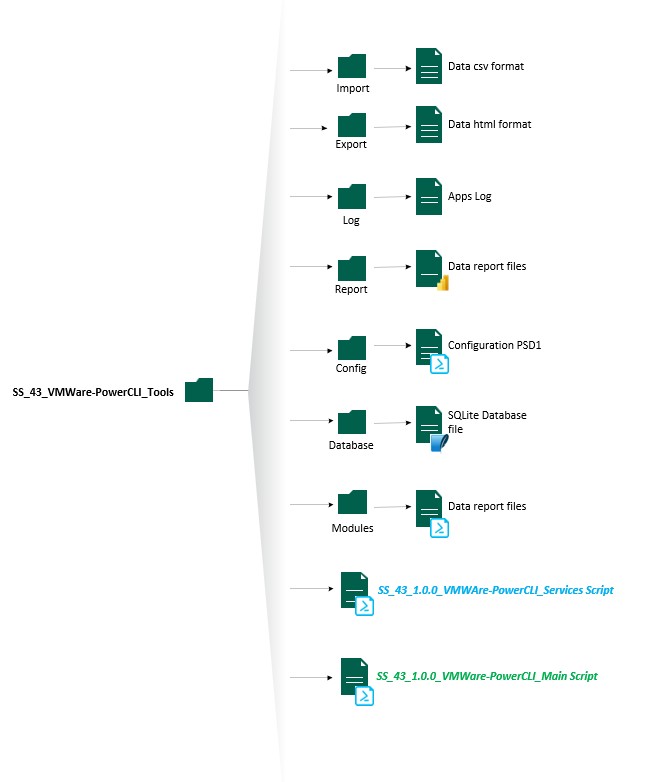
La suite se déroule en 6 répertoires distincts.
- Modules : Répertoire contenant les modules powershell développé pour l’application. Aujourd’hui au nombre de quatre dissociant la partie BDD, Windows, HTML et VMware.
- Database : Répertoire contenant la BDD qui va stocker les données. La SGBD étant sous SQLite il n’y a pas besoin de moteur SQLite. Seul le module SQLite pour powershell est nécessaire en termes de dépendance. La base de données est automatiquement générée si cette dernière n’est pas présente ou si cette dernière à un nom qui diffère du fichier de configuration. Uniquement lors de l’exécution du script en mode manuel.
- Config : Répertoire contenant le fichier de configuration powershell. Effectivement depuis des années je faisais ça directement dans le code… Je mourrai moins con ce soir comme dirait quelqu’un que je connais bien 🙂 Je reviendrai plus en détail sur la partie 2 sur le contenu de ce fichier. Afin de palier à toute suppression malencontreuse du fichier de configuration, j’ai développé une fonction pour regénérer ce dernier. Oui je suis adepte du Alt+Maj+Del et j’ai dû recommencer mon fichier. Maintenant plus de problème avec mon combo favori <3
- Report : Là où je stocke les fichiers Microsoft PowerBI. Je reviendrais sur ce point dans la partie 2.
- Log : Répertoire qui va contenir la ou les traces d’exécution du code si l’option est activée. Cela à son importance car il permet au petit gars qui à dev l’application dans sa baignoire de corriger les bugs. Le fichier ne prend pas de place et est réinitialiser à chaque lancement.
- Export : Répertoire qui va contenir les données extraites selon les tags dans des rapports HTMLs. Les rapports ont été pensé pour être navigable et donc faciliter la consultation des rapports dans un navigateur internet. Cette fonctionnalité a été abandonnée pour l’instant car retranscrit dans PBI13. Mais cette fonctionnalité à le droit d’être finalisé et elle le sera. 🙂
- Import : Répertoire qui va contenir les sources CSV avec les permissions à définir le plus finement possible sur l’environnement VMware.
Il est important de noter que le script manuel et le script de service peuvent être dissocier. Ce qui se traduit dans un sens par je peux utiliser un serveur en mode type console avec l’outil manuel et garder l’automatisation sur un serveur avec uniquement le strict nécessaire.
Topographie – Logiciel
Comme toujours le code peut être optimisé, factorisé. Néanmoins, je considère cette version béta comme stable. Bien que par moment quelques ajustements restent nécessaire et quelques fonctionnalités ont besoin d’être finalisées. De plus, je pense sincèrement que d’autres cerveaux et d’autres idées permettraient de pousser plus loin certaines fonctionnalités existantes et de voir d’autres fonctionnalités naitre.
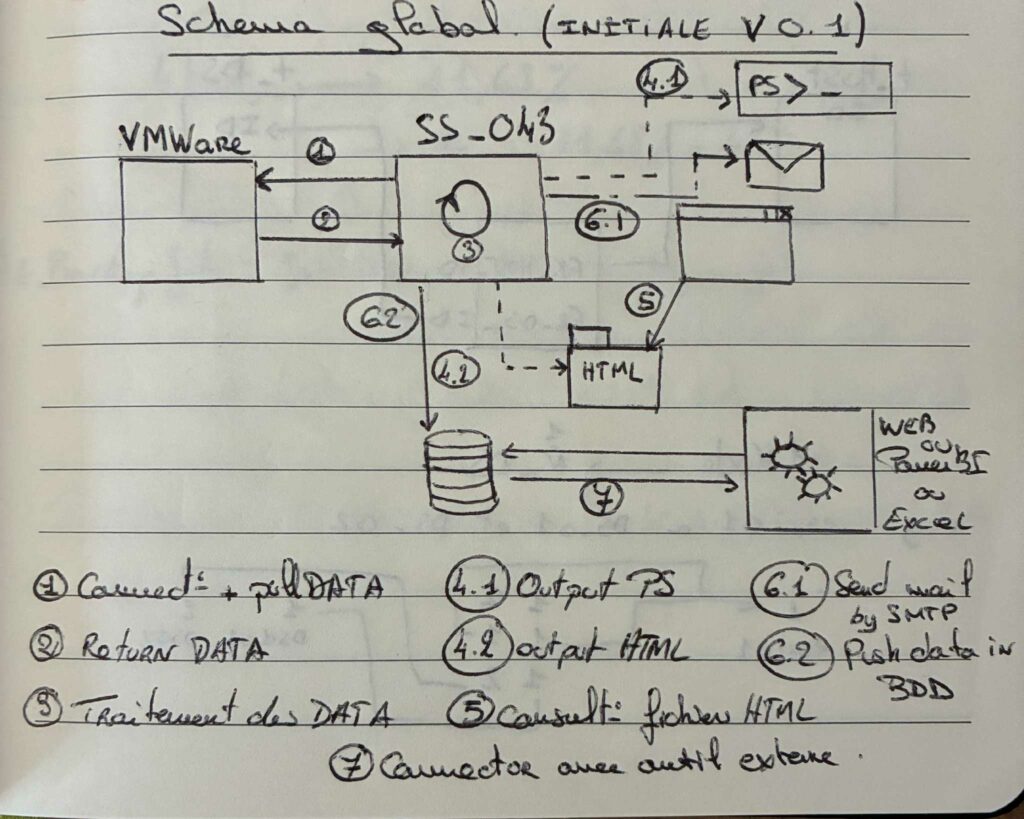
Oh ! La flemme du type qui ne veut pas se palucher un visio et montrer qu’il bosse encore à l’ancienne genre papier/crayon !
Dans son fonctionnement, nous pourrions voir le fonctionnement suivant :
- 0 : Contrôle et vérification des prérequis. Pour simplifier la chose, lecture du fichier de configuration vérification de la BDD et tout le toutim. Et dans une certaine mesure, création de la tâche planifiée
- 1 : Appel API vers l’appliance VMWare afin d’établir la connexion à l’appliance et réaliser les opérations de lecture nécessaire
- 2 : Traitement des données retournée par l’API VMWare afin de stocker ces dernières dans la SGBD, naturellement si l’option est activée l’ensemble des sorties consoles sont redirigées dans un fichier de log
- 3 : Laisser la possibilité d’exploitation des données
- 3.1 : PS Output (cli) pour un affichage rapide des données dans la console powershell avec un affichage user friendly des performances et ressources VMWare (sinon tu as quasi la même chose dans la partie Dashboard de VMWare tu sais ?)
- 3.2 : HTML Output pour générer une synthèse navigable par bulles et environnements virtuels
- 4 : Envoi d’une notification mail via le protocole SMTP pour informer du bon succès de la tâche.
- 5 : Possibilité d’exploitation dans Microsoft PowerBI.
- Une fois le modèle en place de reporting (PowerBI) configuré (comprendre faire les jointures dans l’application), rafraichir les données. Modification des filtres dans un objectif d’exploitation
Comme d’accoutumé, je ne présente pas pour l’instant les différents bouts de code. Les raisons ? Toujours les mêmes. Première ça serait indigeste ici (bien que pour ça il y a GitHub), la seconde étant que je ne souhaite pas que mes travaux s’évaporent dans la nature. Et j’ajoute une troisième raison. Vous savez ce que vous pouvez « potentiellement recruter » dans votre équipe interne. (Oui, j’ai toujours en travers mon dernier entretien professionnel où je n’étais pas assez technique… Mais ce de bonne guerre #coeuraveclesmains). Je me pose toutefois la question et laisse part à la réflexion de rendre mon projet communautaire.
Sécurité
A ce moment de la rédaction, je ne vois qu’un point négatif sur l’ensemble du projet qui nécessite d’être amélioré. Ce point concerne la partie SGBD.
SGBD
Comme pour le projet GreenRay, la problématique est la même. Tout reste à faire… Bien que la BDD ne contienne pas de données sensibles pouvant nuire à la sécurité du SI cette BDD reste conforme à la législation en vigueur avec la RGPD14.
Toutefois, le choix de SQLite et de son caractère singulier cross plateforme nécessite de sécuriser son contenu et intégrité. Hors, de ce côté là, pas de chiffrement de la BDD ni de côte d’accès. Alors comme dans le projet précédent il faudrait envisager de développer d’autres plugins pour d’autres SGBDs relationnels.
Une sécurité de base, serait de paramétrer les ACLs afin que le fichier de BDD ne soit accessible que du compte de service et des comptes utilisateurs habilités à lancer l’application en manuel.
Concernant le MCD… Toujours le même dilemme…
Toujours pareil ! Boum boum dans les oreilles ! Le MCD15 a été pensé sur papier puis construit sur les bases d’un modèle existant… Partager le MCD revient à publier mon code finalement. Avec un peu d’huile de coude et de reverse engineering vous me remiserez au placard.
Pis bon, je vois venir les SysDBAs16 me dire que c’est pas MERISE nanani nanana… La structure de la BDD n’était pas d’une complexité folle, cette dernière n’était composée que de 13 tables.
VMware
Concernant VMWare, j’ai pensé à deux approches. Une approche d’authentification à travers une jonction à un domaine et à l’authentification locale.
Dans les deux cas, j’ai choisi de limiter l’accès en lecture seul. L’objectif du projet étant rappelons le de suivre et d’interpréter dans le temps l’évolution des infrastructures et non d’interagir par une méthode tierce. Ce qui renforce la sécurité. Toutefois, il sera nécessaire d’attribuer les droits manuellement bien que cela pourrait s’automatiser.
Naturellement, le couple d’authentification ne doit pas apparaitre en clair. Si je permets la saisie manuelle des credentials, dans le cadre de l’automatisation de la tâche le mot de passe doit être chiffré.
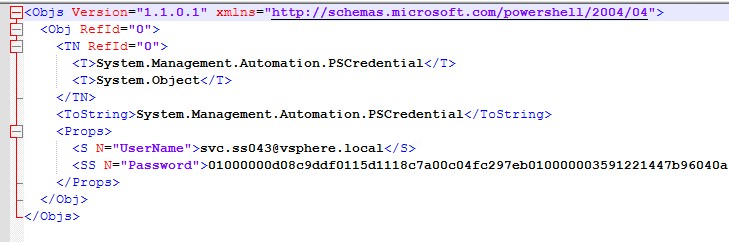
Comme d’hab (j’ai envie de dire), je préfère utiliser les fonctionnalités natives du système pour chiffrer le mot de passe avec les WAPI17 dans un fichier XML. Encore et toujours ce bon vieux CLIXML. Ainsi, l’accès à l’appliance est sécurisé et l’impact est maitrisé.
| Attention néanmoins au ACL sur le répertoire dans lequel va être stocké le fichier de credential. Ce dernier doit avoir des permissions stricts (même si cela me semble évident). |
Taches Planifiées
Là, toujours le même dilemme. Le serveur ou poste qui va exécuter le script est il au domaine ou non ?
Dans le cadre d’un environnement hors domaine, il conviendra de créer un compte utilisateur dédié avec les droits nécessaire pour assurer la sécurité. Néanmoins et lors de la création de la tâche, il conviendra de préciser le mot de passe ainsi que le compte local. Ce qui n’est pas ouf en termes de MCO. Mais c’est aujourd’hui l’une des méthodes que j’affectionne si le serveur est hors domaine.
A l’inverse, si l’environnement est lié à un domaine, l’approche est différente et j’ai pour le coup changer mon fusil d’épaule (va t’il passer l’arme à gauche ?). Je suis devenu un convaincu des groupes de compte de services administrés (gMSA) dans une certaine mesure. Après réflexion sur mon infrastructure ainsi que les 43 types de scripts développés, je me suis dit qu’il n’était pas déconnant de définir un serveur de script dédiée à des tâches planifiées.
De ce fait, je n’installe pas sur tous les serveurs les RSATs18 ActiveDirectory et la rotation de mes mots de passe est périodique sans avoir à repasser, modifier les taches à chaque fois. C’est cool non ?
Il subsiste toutefois une petite pirouette si nous venions à utiliser les fonctions de chiffrement windows pour encoder et décoder une information. La création de la tâche nécessitera une configuration manuelle pour assurer le chiffrement.
Dépendances
Oui, je m’appuie sur des dépendances tierces. Il me semble important de parler de ces derniers avant toutes choses. Premièrement pour rendre à Caesar ce qui appartient à Caesar et deuxièmement pour comprendre comment le projet est construit.
- Connecteur .Net VMware – VMWare PowerCLI : Pour communiquer directement avec l’appliance VMware, il suffit d’installer et d’utiliser le plugin VMware.PowerCLI depuis le repo de base powershell (PSGallery). Ainsi, nous disposons de l’interface de commande compatible pour interagir avec les produits vSphere, vSAN, NSX, VMware Cloud on AWS etc.
- Interface .Net Powershell – SQLite : Pour communiquer avec une base de données SQLite, j’ai installé le plugin powershell PSSQLite depuis le repo officiel.
- Connecteur MS PowerBI et SQLite : Il me manquait les drivers ODBC19, j’ai donc dû télécharger et installer ces derniers afin d’assurer la connexion entre l’application PowerBI et la BDD SQLite (lien).
Et c’est tout. Rien de plus, rien de moins.
Avec toute la théorie, je pense que nous pouvons maintenant aborder la seconde partie pratique qui n’est rien d’autre que le guide d’installation et de configuration de l’application développée.
- SI : Système d’Information ↩︎
- DSI : Directeur des Systèmes d’Informations ↩︎
- RSI : Responsable des Systèmes d’Informations ↩︎
- MSP : Managed Services Provider ↩︎
- API : Application Programing Interface ↩︎
- IaaS : Interface as a Service ↩︎
- SaaS : Software as a Service ↩︎
- VCSA : VMware System Appliance ↩︎
- GUI : Graphic User Interface ↩︎
- BDD : Base de données ↩︎
- gMSA : Groupe Managed Service Account ↩︎
- SE : Système d’Exploitation ↩︎
- PBI : Microsoft Power BI ↩︎
- RGPD : Règlement Général sur la Protection des Données ↩︎
- MCD : Modèle Conceptuel de Données ↩︎
- SysDBAs : Administrateur des systèmes de base de données ↩︎
- WAPI : Windows Application Programing Interface ↩︎
- RSATs : Remote System Administration Tools ↩︎
- ODBC : Open Database Connectivity ↩︎