
Apps – OLLAMA
Pour ce nouveau billet, je pense que commencer par une définition est une bonne chose.
Robot : nom masculin, du tchèque robota, travail forcé, mot créé en 1920 par K. Capek.
Dans les œuvres de science-fiction, machine à l’aspect humain, capable de se mouvoir, d’exécuter des opérations, de parler.
Appareil automatique capable de manipuler des objets ou d’exécuter des opérations selon un programme fixe, modifiable ou adaptable.
Définition Larousse
Au vu du titre de cet article et de la définition posée précédemment, difficile de ne pas deviner le sujet qui va être abordé.
Hé oui, moi le puriste, je vais parler d’IA1 et pire que cela l’utiliser de manière récurrente. Je me sens en ce moment comme le capitaine Haddock face au lama dans l’œuvre d’Hergé, Tintin et le temple du soleil.

Naturellement, au vu de mes précédents écrits, c’est vous lecteurs et l’ensemble des solutions IA qui me crachent dessus. C’est l’arroseur arrosé en somme, moi qui ne voulais pas entendre parler de ça…
Mais alors pourquoi un tel revirement de situation M’sieur GUILLEMARD ?
Je pense qu’il faut vivre avec son temps et ignorer cet outil technologique serait signer mon arrêt de mon mort d’ici quelques années et devenir un être never been à défaut d’has been…
Après tout Errare humanum est, perseverare diabolicum2 non ?
Avant-Propos
J’ai pris le parti d’être méfiant vis à vis des outils d’IA en ligne gratuit ou du moins libre d’utilisation.
- ChatGPT
- Gemini
- Copilot
- Claude
- …
Je ne me mouille pas trop dans les moteurs d’IA…
Dire que je n’ai jamais utilisé l’un de ces moteurs serait me parjurer et il faut reconnaitre qu’il y a un côté pratique. Difficile une fois avoir gouter à la simplicité pour ne pas l’utiliser à tout va pour tout et rien. C’est là pour moi le piège de la pauvreté intellectuelle. Comme toutes les bonnes choses il faut savoir ne pas en abuser.
En dehors de l’aspect social et sociétal qui me préoccupe tant, se pose la question des données saisies dans le moteur de recherche ou plutôt de prompt.
- Que deviennent les données saisies ?
- Que deviennent les données retournées ?
- Combien de temps sont conservés ces données ?
- A qui profitent ces données ?
- Qui sur surveillent les données ?
Cela fait un bon nombre de question non ? Surtout qu’un grand nombre des acteurs de l’IA sont aux US, Chine etc avec une législation bien singulière. Qui de nos jours lis encore les CGUs3 (et qui les a déjà lus) ?
C’est ainsi que grâce à mon directeur j’ai découvert la solution OLLAMA. Solution open-source qui exécute des modèles d’intelligence artificielle (aussi appelé LLM4) localement. Tout de suite, le projet m’a séduit et je me suis demandé
Et pourquoi pas ?
Dans le pire des cas, je mourrai moins c*n ce soir comme dirait un philosophe du cercle familial.
Naturellement, j’ai choisi d’user de OLLAMA sur ma distribution favorite RockyLinux. L’environnement a été préalablement durci.
On se lance dans la théorie puis dans la pratique mes petits Lamas ?
Prérequis
- SE :
- Rocky Linux 9.x et version ultérieures (pour ma part ça sera du 10.x)
- macOS
- Windows
- Apps :
- Ollama
- Autres :
Théorie
Je vais essayer d’être le moins rassoir possible. Toutefois et encore il est nécessaire d’où nous partons pour en être là maintenant avec l’IA.
Un peu d’histoire
La notion d’intelligence artificielle vient de loin dans notre histoire, puisque l’homme depuis l’antiquité rêve d’objets animés intelligents qui pourraient répondre à ces besoins.
Ce qui est fascinant ce trouve dans les différentes cultures à travers les âges. Que ce soit :
- Les automates d’Héphaïstos dans la mythologie grecque
- La tentation de créé l’Homme servi par l’alchimie aux moyen âge comme la science Talkim du grand savant islamique Jabir ibn Hayyan (Geber en latin), des homoculus par le médecin suisse de conviction chrétienne Paracelse qui s’inspirera des travaux de Zosime de Panopolis sans oublier l’un des plus connue de tous ces automates, le Golem d’argile présent dans le Talmud du judaïsme, créé par le rabbin Maharal pour protéger la communauté juive de Prague face aux multiples pogroms (j’ai d’ailleurs eu la possibilité de visiter le cimetière juif de Prague et de comprendre tout cela).
- Plus tard, nous retrouverons des œuvres telles que
- Les Aventures de Pinocchio de Carlo Collodi avant d’être adapté en dessin animé par Disney
- Frankenstein de Mary Shelley
- Ou encore Deep Blue qui viendra à bout de Garry Kasparov aux échecs.
| Bref, tout cela pour dire que depuis l’origine de l’humanité, nous Homme recherchons à créer des objets autonomes et intelligents à notre services. Pour de multiples raisons, défensives, assistanat etc. Le plus troublant, cette pensée de création pourtant contre religieuse et présente dans toutes les cultures et religions portées par ces savants et lettrés (et ça, voyez-vous je trouve ça beau, très beau). |  |
Enfin, il faudra attendre le XXème siècle et l’arrivée des premiers ordinateur programmable pour que l’IA se développe pleinement.
C’est le pionnier et j’oserai dire le père de l’IA John McCarthy qui ouvre la voie, notamment par cette citation :
C’est la science et l’ingénierie de la fabrication de machines intelligentes, en particulier de programmes informatiques intelligents. Elle est liée à la tâche similaire qui consiste à utiliser des ordinateurs pour comprendre l’intelligence humaine, mais l’IA ne doit pas se limiter aux méthodes qui sont biologiquement observables.
John McCarthy – Wikipédia
Le sujet étant réellement complexe, il est difficile de concrétiser et de répondre aux attentes des investissements privés et étatiques durant la période 70 à 80. Ce qui vaudra un ralentissement dans la rechercher et la montée en puissance de l’IA que nous connaissons ce jour en 2026. Et pourtant les théories et grands principes mathématiques et logiques sont établis et adopté par la DARPA8. C’est ainsi que s’affronte deux grands systèmes :
Le système logiciste VS Le système neuronale
C’est en 2010, que l’IA fait réellement son entrée dans nos vies du quotidien et dans les différents secteurs d’activités.
Pour entrer davantage dans le détail je vous invite à lire la page wikipédia (cf les sources). J’ai promis de faire court. 🙂
Les modèles d’IA
Les modèles d’IA, c’est un peu comme un oignon, il y plusieurs couches.
Déjà il est important de dissocier le Machine Learning du Deep Learning.
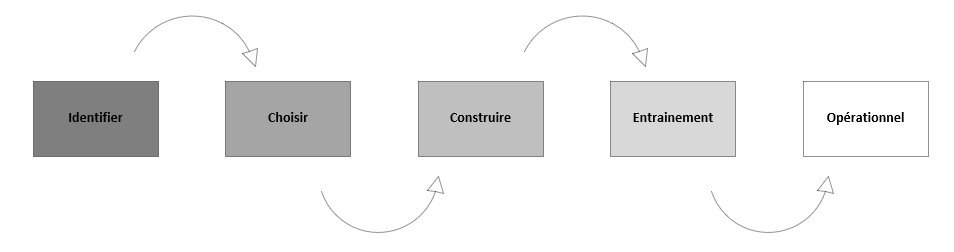
Le process pourrait se décrire de la manière suivante :
- Phase 1 : Identifier les mots clés fournit en entrée les plus pertinents afin de préparer ces derniers à être analysé. Nous parlons généralement de datasets.
- Phase 2 : Choisir le bon modèle ou algorithme qui sera le plus pertinent à être utilisé selon l’identification des datasets identifiés et analysés.
- Phase 3 : Construire le modèle d’analyse basé sur l’algorithme choisie lors de l’étape précédente.
- Phase 4 : Jouer le modèle sur un ensemble de jeux de données afin d’obtenir plusieurs jeux de données.
- Phase 5 : Utiliser le modèle pour attribuer une note à l’ensemble des jeux de données retournés et fournier des patterns pertinents adaptés aux datasets initiaux.
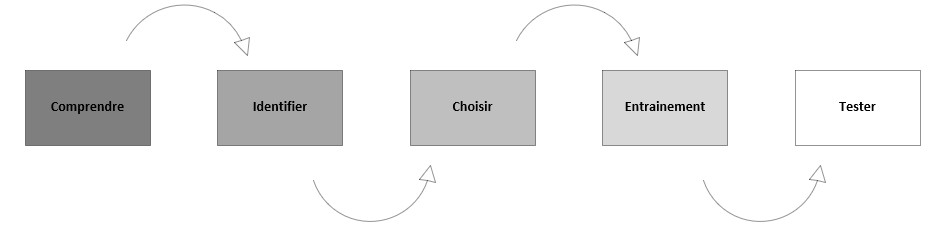
Le process pourrait se décrire de la manière suivante :
- Phase 1 : Comprendre le contexte présenté par l’utilisateur et décider ou non si le Deep Learning est nécessaire ou non.
- Phase 2 : Identifier les mots clés fournit en entrée les plus pertinents afin de préparer ces derniers à être analysé. Nous parlons généralement de datasets.
- Phase 3 : Choisir le bon modèle ou algorithme qui sera le plus pertinent à être utilisé selon l’identification des datasets identifiés et analysés.
- Phase 4 : Jouer le modèle sur un ensemble de jeux de données afin d’obtenir plusieurs jeux de données.
- Phase 5 : Compare le modèle ainsi que ces performances face aux données existantes identifiés ou non identifiées avec notre contexte initial.
Pour le comprendre au mieux, il convient de reprendre le Diagramm de Venn pour comprendre comment s’imbriquent ces différentes notions d’apprentissage.
| IA : a pour objectif de comprendre le langage humain, de réaliser les analyses prédictives offrir une IHM9 et AGI10. Machine Learning : se compose de l’apprentissage automatique, la clustérisassions, les arbres décisionnels, le SVM11, LLM et NLP12. Réseaux Neuronales : comprend les RAG13 / Finetuning ainsi que les Feed Forward. Deep Learning | 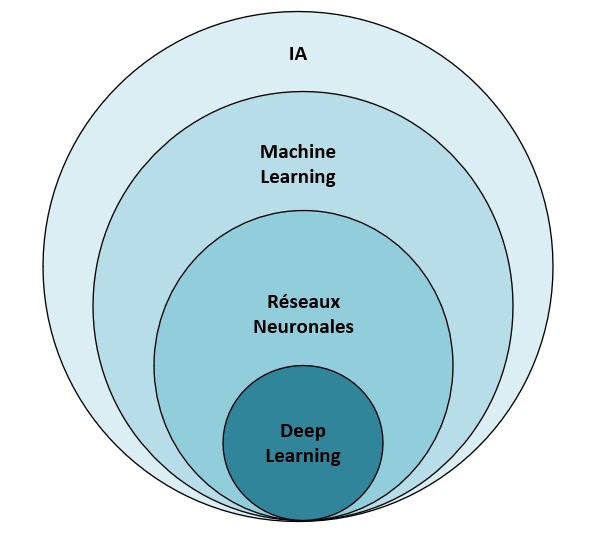 |
Bien que rapide dans la présentation, de ce qu’est l’IA, je pense que nous avons suffisamment d’éléments pour aborder les différents types d’IA.
Toutefois, je suis loin d’être spécialiste de l’IA et mes connaissances théoriques remontent de mes cours de 2014 et de ce que j’ai pu lire et apprendre depuis ces dernières semaines. Je vous invite donc à lire plus en détails son fonctionnement en profondeur.
Bon allez ça sera tout pour l’instant. Regardons de plus prêt Ollama. 🙂
Architecture et Best-Pratices
Ollama étant cross plateform, j’ai pris le parti de déployer ce dernier sous RHEL. Donc le guide va suivre dans ce sens. Ce choix est motivé par mes soins pour garder une meilleure maitrise des ressources qui vont être consommées par le système. Pour MacOS, je ne me prononce pas car je n’utilise pas ce dernier. Sous Windows, je voyais déjà mon petite dernier faire du rodéo sur l’hyperviseur qui gambade dans le couloir au premier prompt soumis… 🙂
| Comme énoncé ci-haut, il faut au minimum en ressource : * 4 vCPUs * 16 Gio de RAM * 2 Gio de GPU * Stockage Rapide Malheureusement pour moi, je n’ai pas les ressources nécessaires, mais cela ne m’empêchera pas d’aller au bout des choses. Je propose toutefois de dissocier les modèles et une partie de l’architecture OLLAMA sur un disque dédié pour des raisons de performances lors de la soumissions des prompts et ne pas saturer le disque système. L’accès à l’application se fera par des call API14 sur le port 11434/tcp. | 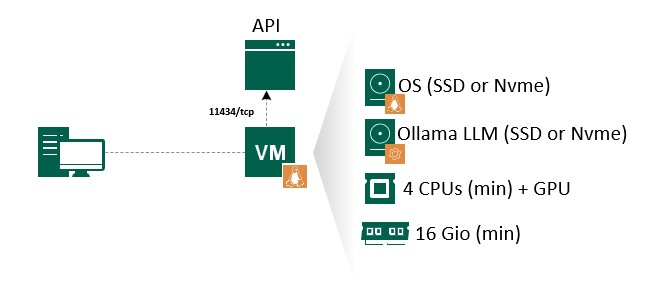 |
Si nous voulions aller plus loin il serait bien de dédié un disque pour les logs et ainsi améliorer les performances.
Niveau sécurité, je suis resté sur mon durcissement classique et divulgâchage alerte ça fonctionne (Jacques TOUBON, le retour aurait été fier de moi pour ce coup-là !).
Je ne vois plus qu’un dernier point à aborder et nous pouvons passer à la pratique. Oui comme toute bonne chose, il faut faire durer le plaisir. #sendkisses
Conséquences de l’IA
L’IA est à ce jour (2025) adopté par environ 2/3 de la population mondiale que ce soit à des fins professionnels ou personnels dont environ 73% dans le contexte pro. Ainsi, difficile de nier que l’usage particulier et bien au-dessus des institutions organisationnelles.
Comme énoncé bien plus tôt dans cette partie, l’usage est principalement à destination des centres de services et à destination des utilisateurs (chatbots, service clients) 60%, l’automatisation des ventes et marketings 13%, l’optimisation des systèmes IT 9%, l’aide à la décision entre 5 et 10% et la production de contenu entre 5 et 10% également. Bien que mes chiffres date de 2023-2024.
Dans son usage concrets, l’IA est utilisée à 46% pour la recherche d’informations, 43% pour la rédaction de textes et 33% pour de l’analyse ou traduction.
Les estimations à venir d’ici 2030 seraient un usage de l’IA par 80 à 85% de la population mondiale. Cette escalade et course n’est pas sans conséquence sur le plan économique et disponibilité des ressources en termes de composants électroniques.
Qui dit plus d’usage, dit plus de ressource de calcul et donc plus de composants et plus d’énergie. Le système peine à suivre. C’est ainsi qu’en moyenne, l’évolution des couts entre 2024 et 2026 (estimé sur le plan mondial) et de :
- RAM (DDR5) : +170 à +250 %
- SSD : +60 à +100 %
- GPU : +10 à 25 %
- CPU : +0% à +10%
Cela entraine donc une hausse des offres Cloud et service SaaS/IaaS/PaaS/BaaS et j’en passe ainsi que des couts équipements embarquant ce type de composants. Difficile de faire sans IA de nos jours.
Bon c’est promis, passe à la pratique, je ferme la parenthèse que je n’ai jamais ouverte.
Pratique
Avant de se lancer dans l’installation, si je reprends les prérequis énoncés ci-haut, sachez que :
- Je n’ai pas de GPU
- Je n’ai pas de stockage rapide
- Mon hypervisieur est monoprocesseur
Tout pour bien fonctionner en somme 🙂
Installation
L’installation va se dérouler en 2 parties. Une partie pour installer Ollama, une partie pour l’installation des modèles d’intelligence artificielle.
Ollama
Installation
La documentation fournit sur le site est simple et claire. Il suffit alors de télécharger et d’exécuter le contenu du script install.sh.
Vérifier en amont que le paquet zstd est installé sur notre environnement.
$ sudo dnf install zstdSi nous rentrons plus en détail, les arguments :
- -f : ignore les redirections en cas de retour autre que le code 200 du protocole HTTP15
- -s : supprime la barre de suppression et rend l’exécution de la commande silencieuse
- -S : indique les erreurs
- -L : permet de suivre les redirections HTTP
$ sudo curl -fsSL https://ollama.com/install.sh | sh| /!\ Attention : Il est vivement recommandé en amont avant d’exécuter un script téléchargé depuis le net de vérifier son contenu et de lire ce dernier. Question de sécurité. Sinon cela revient encore une fois à s’étonner d’avoir attrapé une gonorrhée après être allé aux p*tes sans capotes… $ sudo curl -fsSL https://ollama.com/install.sh | cat |
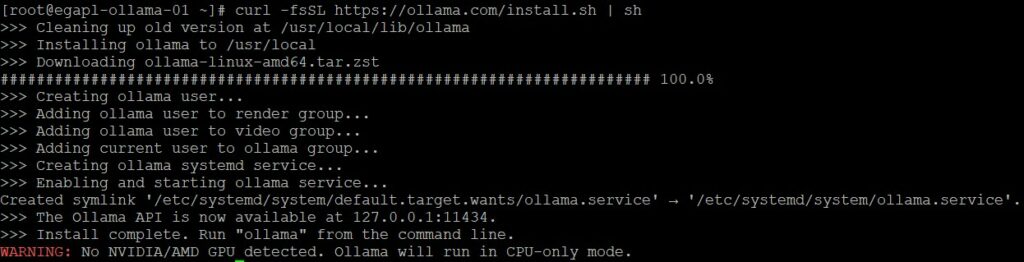
L’installation c’est bien passée. Toutefois, le script nous informe qu’aucun équipement GPU n’a été détecter et donc que les calculs seront effectués par notre CPU. Ce qui va donc être plutôt lent dans mon cas personnel.
Service au démarrage
Nous retrouvons une commande maintenant bien connue dans les environnements RHEL. Ainsi à chaque démarrage de notre système notre daemon ollama va être démarré.
$ sudo systemctl enable ollamaFirewalling
Encore une fois et comme toujours, il est nécessaire d’ouvrir le port 11434/tcp si nous souhaitons joindre l’API depuis l’extérieur (comprendre hors localhost).
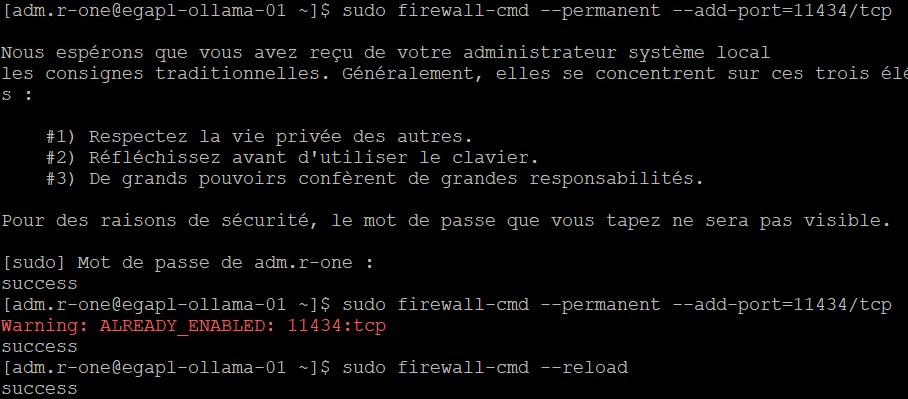
$ sudo firewall-cmd --permanent --add-port=11434/tcp
$ sudo firewall-cmd --reloadOn est d’accord que si nous souhaiterions mieux faire en termes de sécurité, il serait plus intelligent de créer la policy suivante :
$ sudo firewall-cmd --permanent --add-rich-rule='rule family="ipv4" source address="10.127.50.0/24" port port="11434" protocol="tcp" accept'
$ sudo firewall-cmd --reloadAyant un UTM16 en amont, je me permets donc de me contenter de la première solution.
HTTP ou HTTPS ?
Un doute m’habite… Le port 11434/tcp, ça ne serait pas du http ?
Bien vu l’aveugle ! Effectivement et niveau sécurité c’est pas super, il faudrait mieux user du protocole https. Pour ça, j’ai une solution passons par un reverse proxy 🙂
Je suis partagé quant à la rédaction de cette sous partie. Oui il est important de sécuriser l’accès à l’interface Web, mais j’ai peur d’être hors sujet et d’alourdir l’article. Mais d’un autre côté, je ne veux pas non plus bâcler la chose… Encore un pu**n de choix cornélien…
Bref, je vais faire au plus simple et si besoin écrirai un billet sur Nginx.
L’installation et activation du service, je passe mon tour.
$ sudo dnf install nginx
$ sudo systemctl enable nginx
$ sudo systemctl start nginx

Là encore une fois je rencontre un petit problème. Je n’ai pas de certificat public que je pourrais utiliser, ma topologie réseau ne me permet pas d’utiliser un certificat Let’s Encrypt et sans vouloir spoiler je n’ai pas envie de me prendre la tête. Donc ça va finir avec un bon vieux certificat autosigné 🙂
La génération n’est pas bien compliquée et si besoin, j’ai déjà rédigé un article sur le sujet.
Créons le répertoire qui va contenir nos éléments de sécurité :
$ sudo mkdir -p /etc/nginx/sslGénérons notre certificat :
$ sudo openssl req req -x509 -nodes -days 365 \
-newkey rsa:2048 \
-keyout /etc/nginx/ssl/ollama.key \
-out /etc/nginx/ssl/ollama.crtCréons et éditons notre fichier de configuration. Je prendrai le temps d’expliquer l’intégralité du fichier de configuration.
$ sudo vim /etc/nginx/conf.d/ollama.conf#server {
# listen 80;
# server_name 10.227.250.11;
#
# return 301 https://$host$request_uri;
#}
server {
listen 11444 ssl;
http2 on;
server_name 10.227.250.11;
ssl_certificate /etc/nginx/ssl/ollama.crt;
ssl_certificate_key /etc/nginx/ssl/ollama.key;
# TLS sécurisé
ssl_protocols TLSv1.2 TLSv1.3;
ssl_prefer_server_ciphers on;
ssl_session_timeout 1d;
ssl_session_cache shared:SSL:10m;
# sécurité headers
add_header X-Frame-Options SAMEORIGIN;
add_header X-Content-Type-Options nosniff;
add_header X-XSS-Protection "1; mode=block";
# taille upload
client_max_body_size 100M;
# compression
gzip on;
gzip_types text/plain text/css application/json application/javascript text/xml application/xml;
location / {
proxy_pass http://10.227.250.11:11434;
proxy_http_version 1.1;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_buffering off;
proxy_read_timeout 3600;
proxy_send_timeout 3600;
}
}| La première section permet de réaliser la redirection du protocole HTTP vers HTTPS de manière permanente. Ainsi si je contacte l’url http://10.227.250.11, je serais automatiquement redirigé vers https://10.227.254.11. Toutefois, la section est commentée car elle entre en conflit avec une autre configuration d’un billet à venir 😉 | 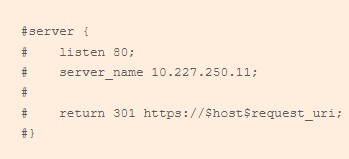 |
| Le second bloc indique que nous écoutons sur le port 11444 sur l’interface 10.227.250.11. L’emplacement des fichiers contenant la clé privée ainsi que le certificat sont spécifiés pour activer la couche de sécurité (j’ai l’impression d’enfoncer des portes ouvertes…). J’indique qu’elles sont les versions des protocoles TLS17 autorisées et laisse le serveur choisir le chiffrement le plus sûr. Côté en-tête, j’ai repris les suggestions de sécurité implémentée pour ITOP. Soit la restriction de mettre le site en iframe externe, de restreindre le navigateur à deviner le tye MIME qui est utilisé et surtout d’activer la protection anti-cross-site scripting. Niveau upload, j’ai vu large et j’ai autorisé le téléversement de fichier de 100 Mio. Côté performance, j’ai activé la compression des flux pour optimiser un peu les performances réseaux. | 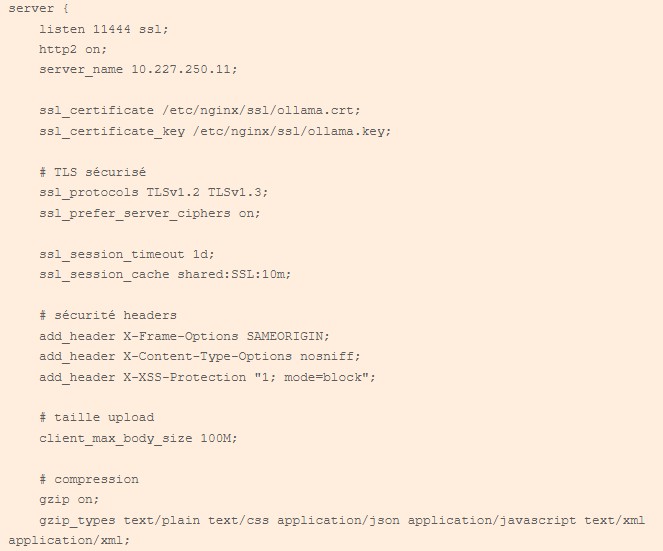 |
| Le troisième bloc concerne la partie Reverse Proxy. Toutes les requêtes qui sont envoyées sur https://10.227.250.11 sont redirigées vers le port 11434. Concernant les en-têtes il est nécessaire d’utiliser les websockets car seront transmis l’ip du client, le protocole utilisé et le NDD18 ou l’IP demandé. | 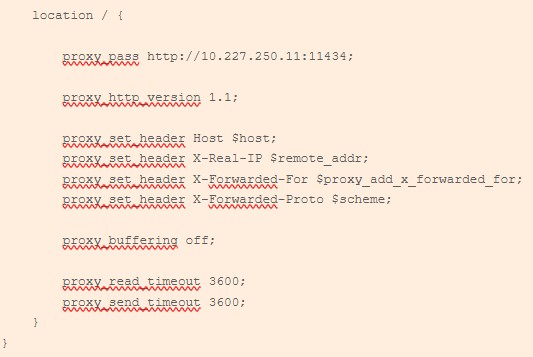 |
Une fois la configuration faite, il est important de réaliser un petit contrôle de notre petit fichier afin de s’assurer que ce dernier ne comporte pas d’erreur.
$ sudo nginx -t
$ sudo systemctl restart nginxTiens une erreur 🙂 Regardons ça dans la partie suivante…
Nous souhaitons toujours publier notre interface web en HTTPS. Donc il va falloir jouer avec nos UTMs !
Sur le plan interne, autorisons nos flux https :
$ sudo firewall-cmd --permanent --add-port=11444/tcp
$ sudo firewall-cmd --reloadToutefois lors de la relance du service on se tape une bonne grosse erreur. C’est lié au SELinux. Nginx n’est pas autorisé par le SELinux a écouter sur le port 11444. Donc il faut l’autoriser.
#Install semanage
$ sudo dnf install policycoreutils-python-utils
#Ajout du port comme autorisé à l'écoute
$ sudo semanage port -a -t http_port_t -p tcp 11444
#Relance du service nginx
$ sudo systemctl restart nginxNormalement nous ne devons plus avoir d’erreur. Toutefois si nous essayons de joindre l’url https://egapl-ollama-01:11444 nous devons avoir un jolie 502 Bad Gateway dans notre navigateur 😀
Ca vous fait la b**e hein ? Je vous rassure je me suis pris la même rouste. J’ai oublié d’autoriser le contexte de mon SELinux pour autoriser les services http à accéder aux réseaux 😀
$ sudo setsebool -P httpd_can_network_connect 1Un petit F5 et hop c’est tout bon <3
| Normalement avec toutes nos actions, nous devons joindre notre interface web depuis un navigateur de manière sécurisée (hormis l’erreur liée à notre certificat autosigné). | 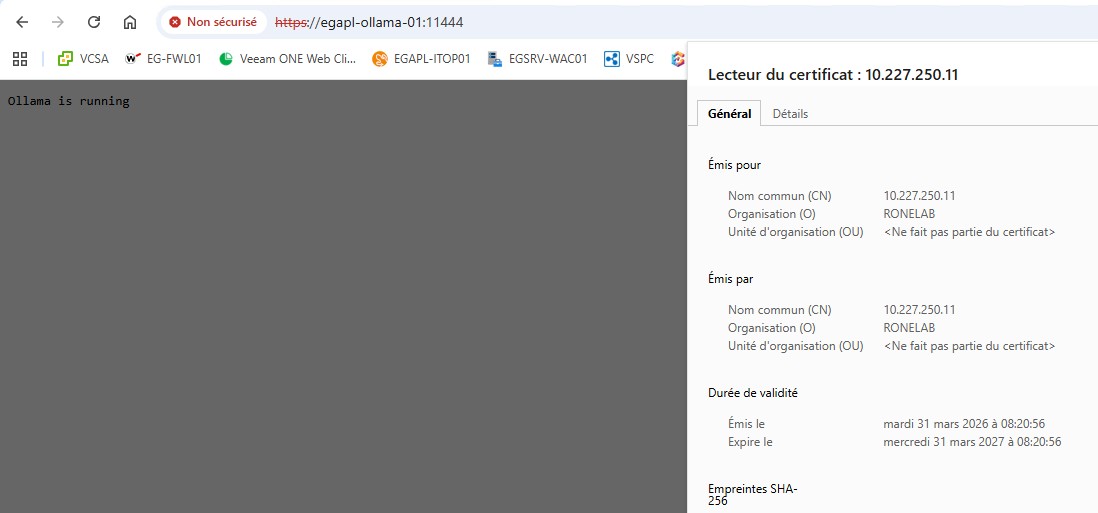 |
Emplacement des modèles
Lors de ce benchmark, j’ai été confronté à un problème d’espace disque lié aux modèles. Effectivement, les modèles sont au minimum supérieur à 3 Gio. Et c’est là que c’est le drame car « pouf » je me tape un message d’erreur…
La solution est donc de déplacer le répertoire de modèle vers un autre disque. J’ai vu large, j’ai provisionné 100 Gio. Je pars du principe que le disque est monté et formaté.
$ sudo chown -R ollama:ollama /mnt/ollamaLe changement de l’emplacement du répertoire du modèle va se faire par surcharge du service qui démarre Ollama. Naturellement, on ne modifie pas le service de base car les changements ne seront pas persistants. D’où la surcharge…
$ sudo mkdir /etc/systemd/system/ollama.service.d
$ sudo vim /etc/systemd/system/ollama.service.d/override.conf[Service]
Environment="OLLAMA_DEBUG=1"
Environment="OLLAMA_MODELS=/mnt/ollama/ollama-models"
Environment="OLLAMA_HOST=0.0.0.0"

Notons que le mode Debug est actif et que le chemin de nos modèles est défini. J’ai également défini la variable OLLAMA_HOST qui va nous permettre de joindre notre application depuis une source externe à notre machine.
Il convient alors de recharger, forcer le gestionnaire de services à recharger l’ensemble de ses configurations. Dans un second temps nous redémarrerons le daemon ollama afin de prendre en considération les changements présents dans notre fichier de surcharge. Par mesure de sécurité (car la confiance n’exclut pas le contrôle) j’aime à vérifier que le service est bien actif.
$ sudo systemctl daemon-reload
$ sudo systemctl restart ollama
$ sudo systemctl status ollama
$ sudo ls -al /mnt/ollama/ollama-models/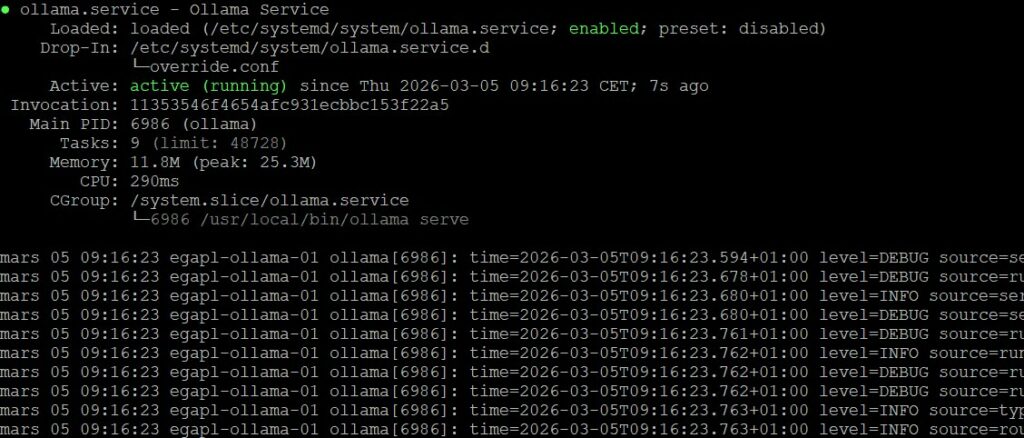
Dans les sources, nous pouvons constater la présence de nos variables surcharger. Néanmoins nous pouvons afficher le contenu de notre répertoire cible pour les modèles afin de vérifier que l’arborescence est bien présente.

Installer des modèles
J’ai fait le parti car c’est « un peu » l’objectif de base de ce billet d’avoir des modèles locaux qui vont être utilisés. Je ne souhaite pas utiliser des connexions avec des sources externes afin de garder un contrôle sur mes recherches et usage.
J’ai fait le choix d’étudier 4 modèles LLM :
- Llama3
- Qwen
- Mistral
- DeepSeek-Coder
Je propose dans un premier temps de faire un comparatif de ces modèles.
| Critères | Llama 3 | Qwen | Mistral | DeepSeek-Coder |
| Editeur | Meta | Alibaba | Mistral AI | DeepSeek |
| Type | Généraliste | Généraliste | Généraliste | Spé code |
| Usage | Populaire | Bon | Rapide | IDE / Dev |
| Licence | Llama Community Licence | Apache 2.0 | Apache 2.0 | Licence DeepSeek |
| Dataset | Texte/Code/Web | Multilingue web | Web + Données filtrées | ~ 90% de code |
| Avantages | Raisonnement et coding | Multilingue et contextuel | Rapide et faible consommateur de ressources | Bon pour du code |
Avec ce tableau, je pense que nous avons un bon récapitulatif. Toutefois et pour les curieux il existe une centaine de modèles compatible avec Ollama (Lien). J’ai fait mon choix, à vous de faire le vôtre. Vous êtes des grands garçons et des grandes filles hein ? #bisous
L’installation pour les modèles choisies, suivent tous la même logique. Pas de quoi épiloguer pendant 107 ans….
$ sudo ollama pull llama3
$ sudo ollama pull qwen
$ sudo ollama pull mistral
$ sudo ollama pull deepseek-coder:6.7b
Pour voir l’ensemble des modèles il est possible de lister ces derniers grâce à la commande suivante :
$ sudo ollama list
Démarrage de Ollama
Maintenant que tout est fonctionnel, démarrons Ollama et c’est parti pour un périple des possibles comme Heinrich Harrer à l’assaut du Nanga Parbat (l’élévation n’étant pas celle que l’on croit 🙂 ).

$ ollama| Dans le menu qui s’offre à nous, la première option permet de démarrer, lancer un de nos modèles localement. Toutefois, en dessous de cette première option de navigation, nous retrouvons la possibilité d’établir des connexions externes vers des moteurs en ligne tel que : * Claude Code * Codex * OpenClaw * Droid * Pi * Cline Si vous possédez un compte, vous pouvez réaliser la jonction, mais alors à quoi bon avoir un moteur d’IA interne ? | 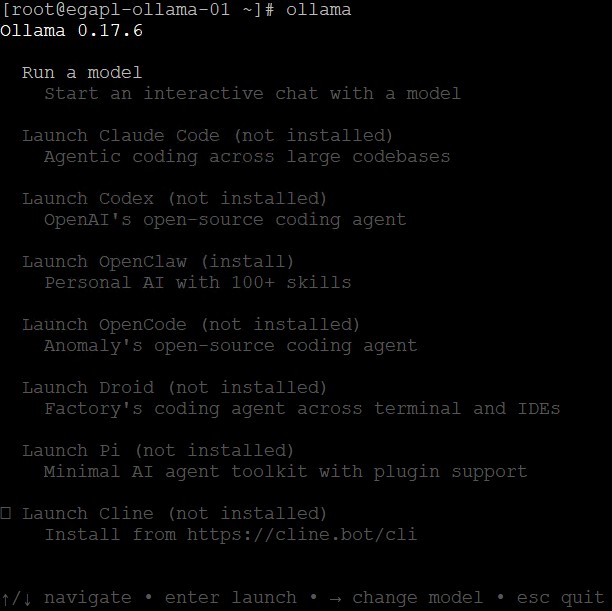 |
Si nous cliquons sur le premier choix, il nous est alors demandé de choisir un modèle. Il est possible de télécharger un modèle directement depuis ce menu ou de choisir un modèle précédemment installé tout en bas de cette interface.
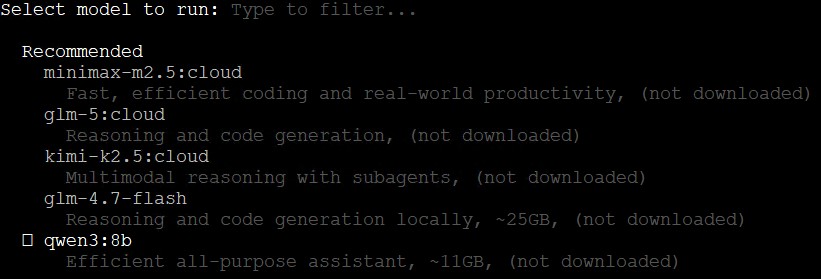
Tests
Et si on se lançais un petit benchmark de nos 4 modèles pour voir le fonctionnement ? 🙂
Amusons-nous tel un lamastico <3
Pour le test, j’ai décidé de partir sur quelque chose de simple et ISO sinon cela ne sert strictement à rien.
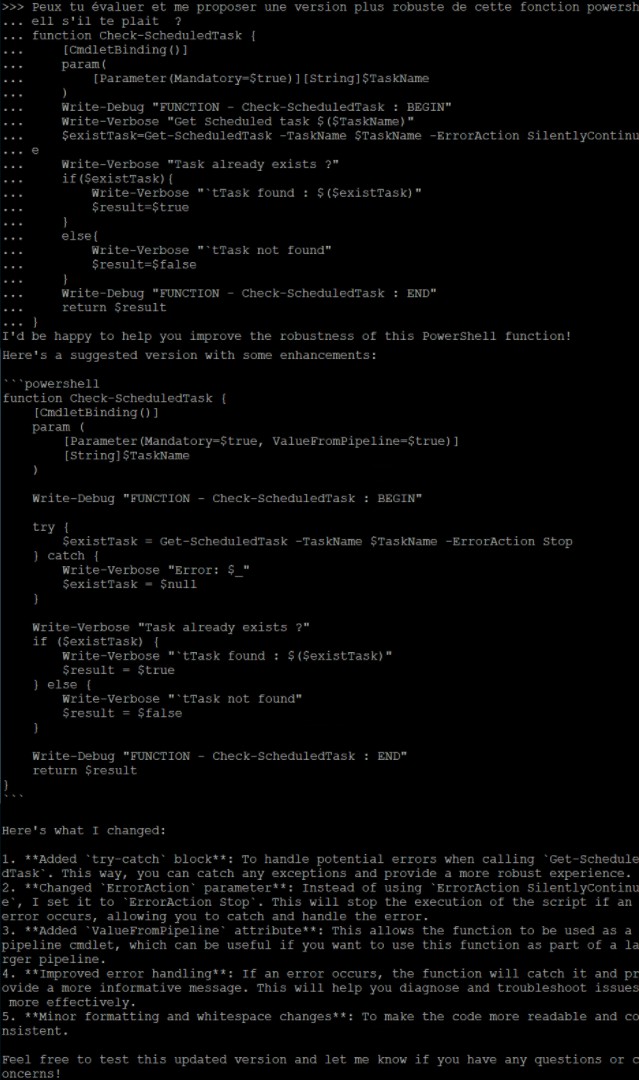
La question sera :
Peux-tu évaluer et me proposer une version plus robuste de cette fonction powershell s’il te plait ? [Suivie d’une petite fonction maison qui peut être amélioré]
 |  |
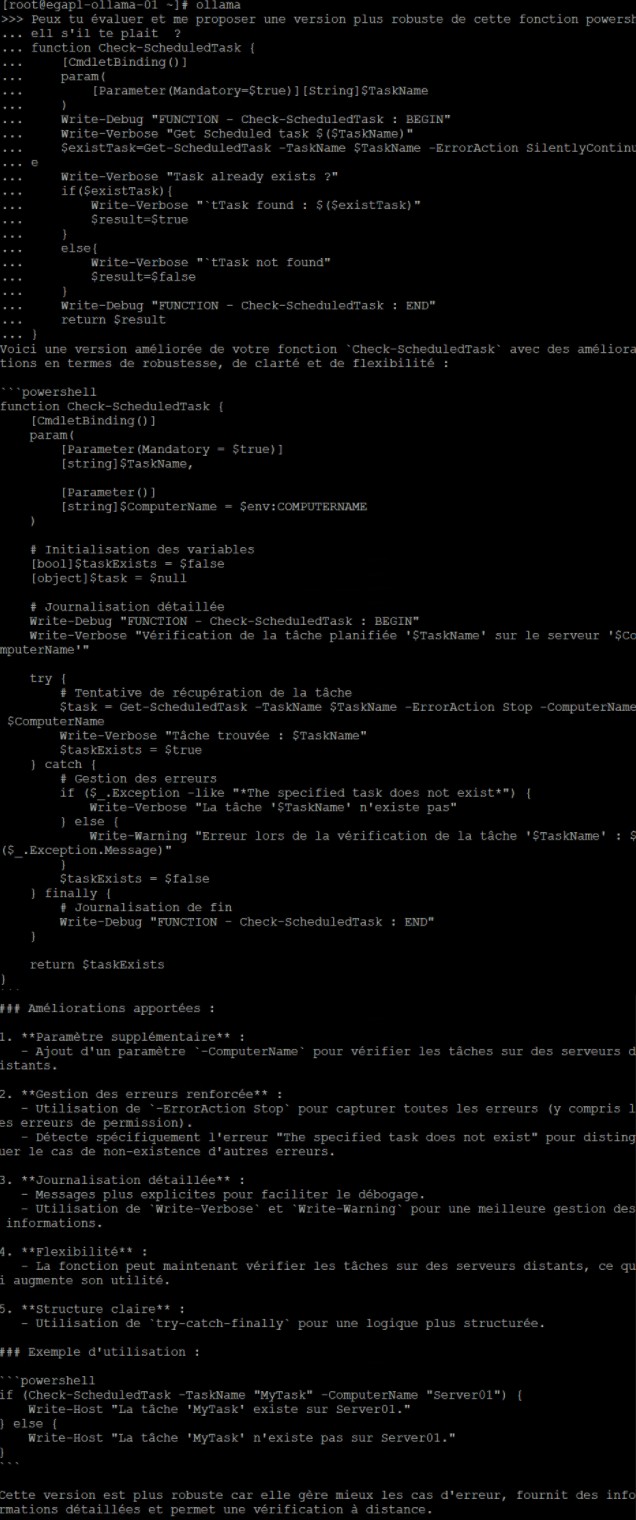 |  |
J’ai du tronquer la partie de la réponse en anglais car cela aurait pris énormément d’espace. Toutefois la réponse retournée est plus que satisfaisante pour celui qui sait parler la langue de Shakespeare
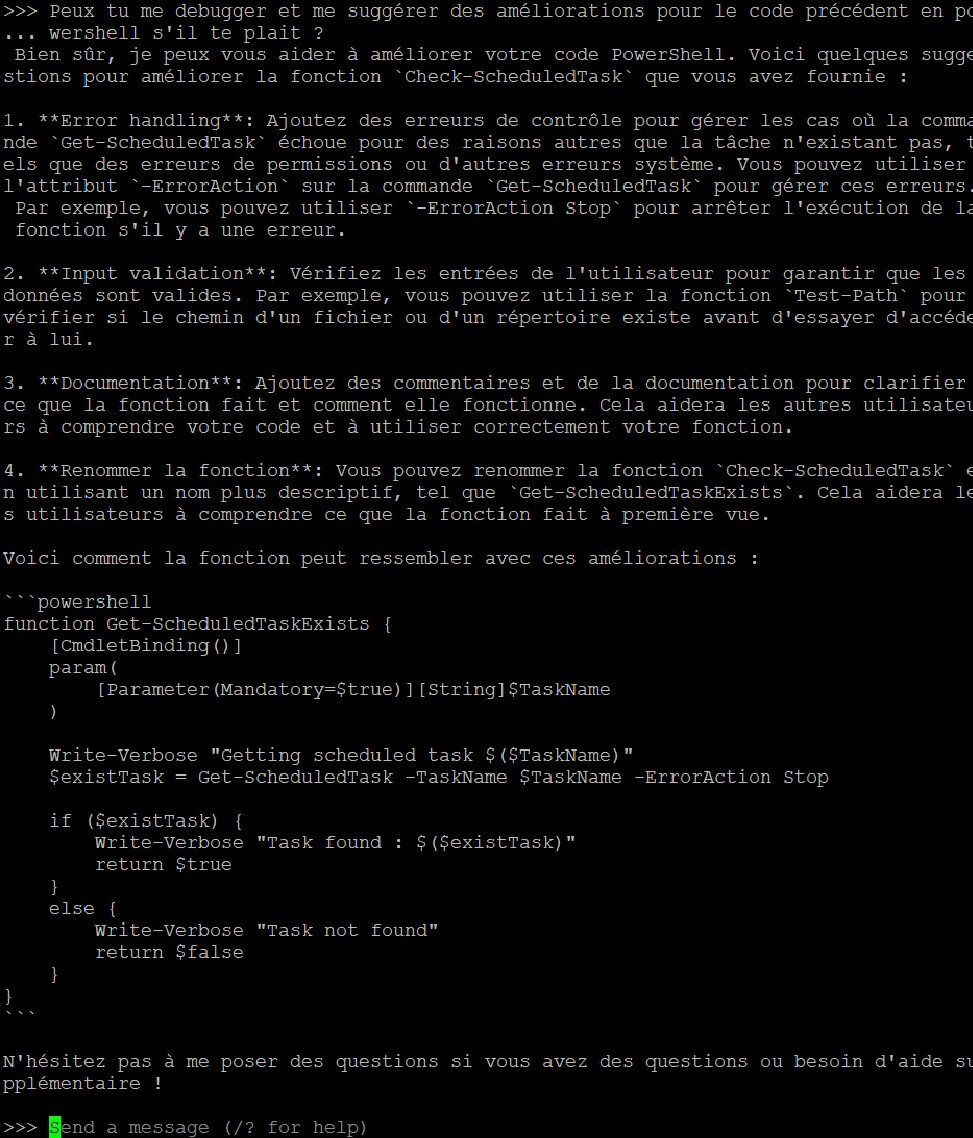 |  |
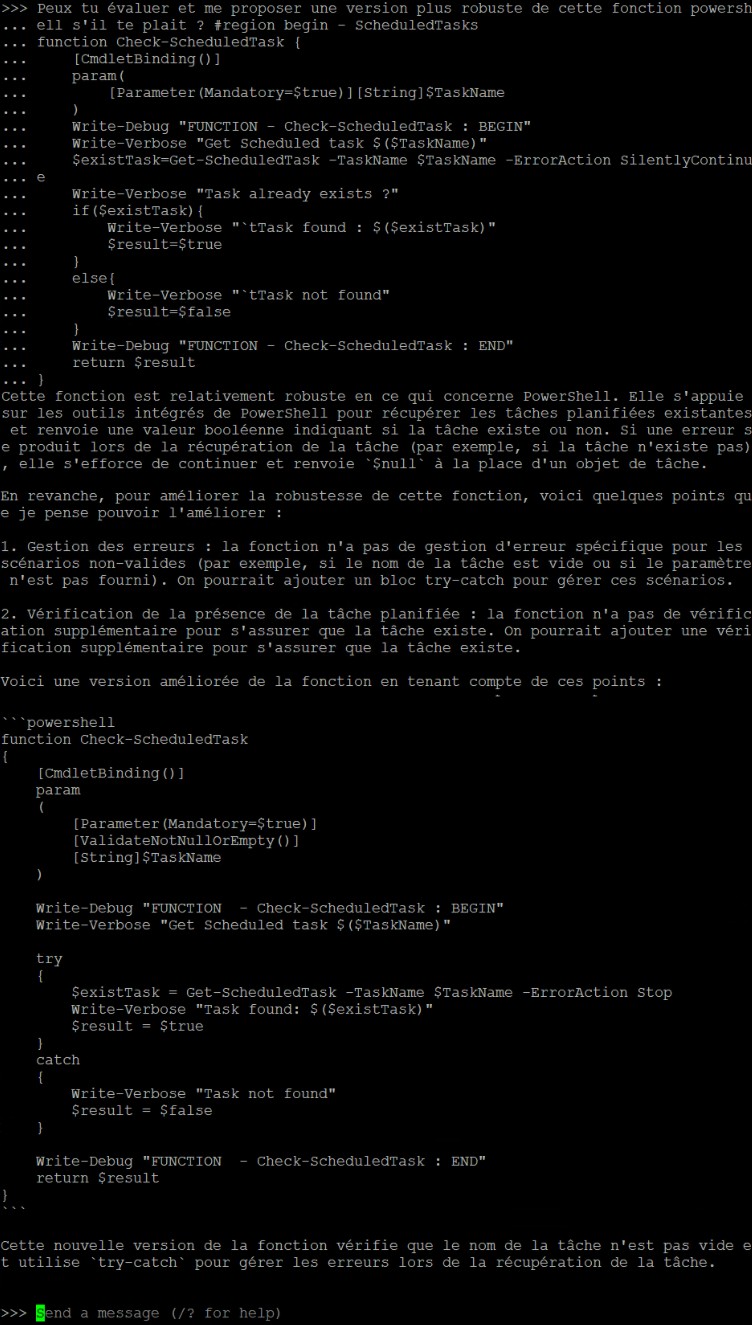 |  |
Je pense que cela est évident en termes de conclusions. Pour 1 prompt identique, nous avons quartes réponses différentes et un point commun. Si certains modèles mettent plus de temps de réponse il est indéniablement contestable que ça chauffe niveau calcul. Dans certains cas, j’aime même du SWAP ! Bref, côté consommation électrique, ça consomme… Mais bon je m’y attendais ce n’est pas la première fois que je fais des étincelles avec ma b*te…
Plus sérieusement, je sais quitte à me répéter ou pas ce que je dois faire pour améliorer ma fonction. Et je suis un peu déçu du résultat. Néanmoins en modifiant légèrement le prompt, en précisant :
Peux-tu évaluer et me proposer une version plus robuste, sécurisé de cette fonction powershell s’il te plait comme si tu étais un développeur sénior avec un regard plus critique et sévère ? [Suivie d’une petite fonction maison qui peut être amélioré]
| Résultat Prompt initial (qwen) | Résultat Prompt plus précis (qwen) |
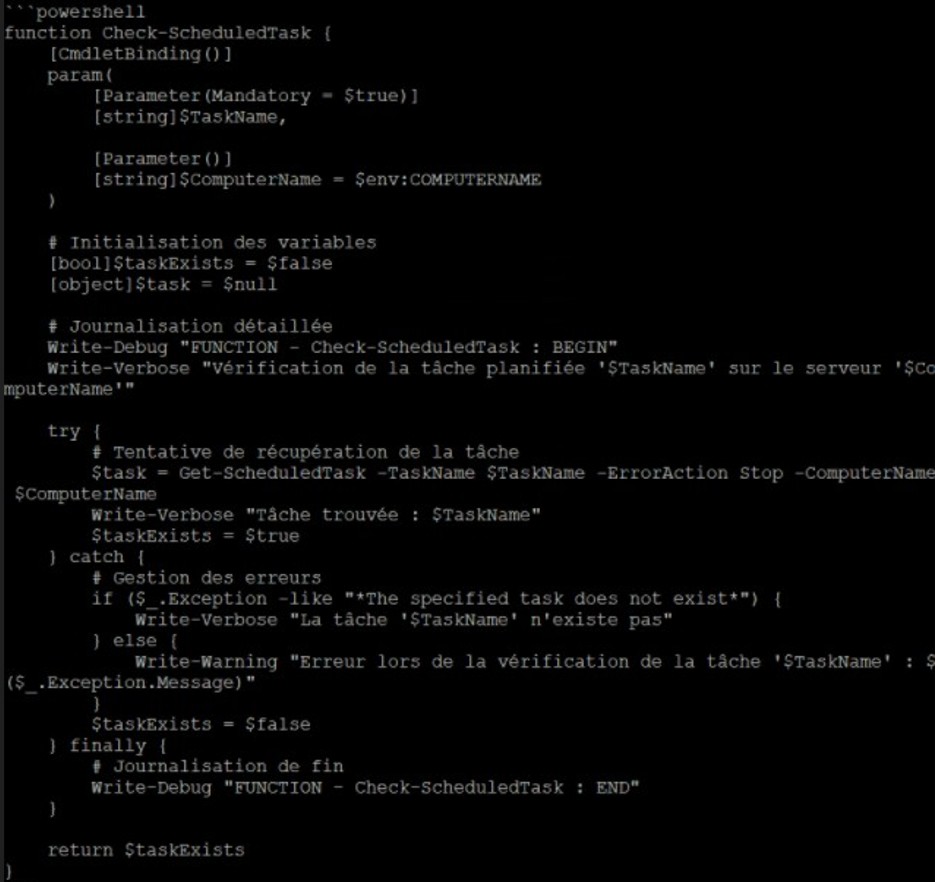 | 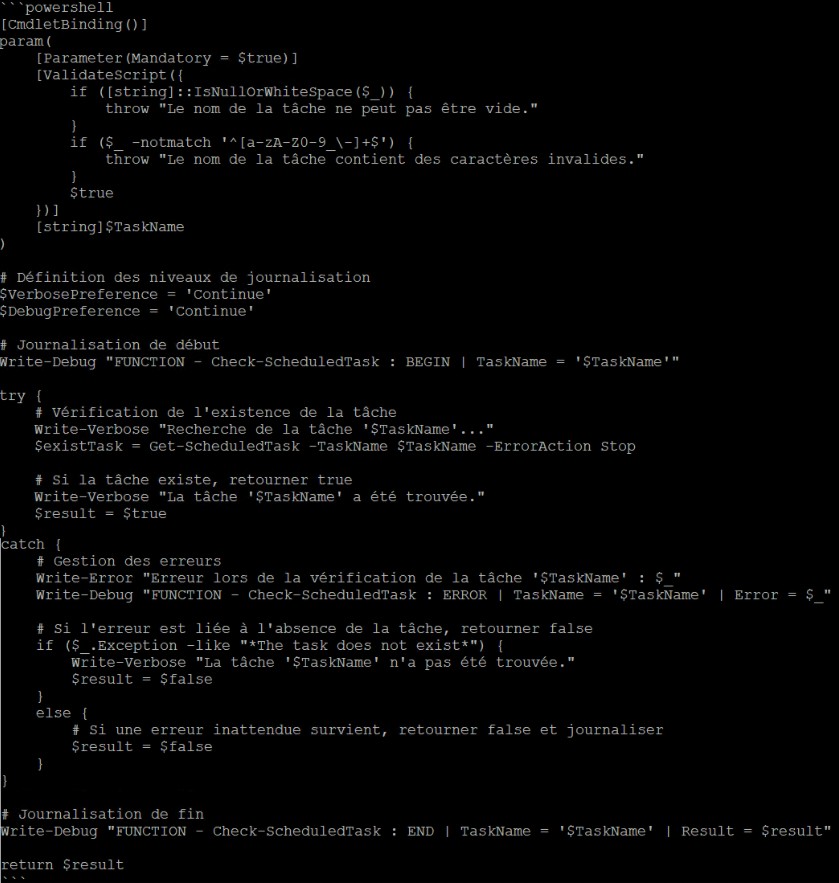 |
/!\ Attention : J’ai volontairement gardé que la suggestion de la fonction et non le blabla d’en-tête qui explique tout ce qui va être appliqué.
Encore une fois pas de magie, il suffit de bien rédiger son prompt et là j’obtiens un retour plus précis à mes attentes.
Si je résume la situation sur le test à iso périmètre selon le contexte :
- RAM : 8 Go
- vCPU : 4
- Processeur Physique : Intel(R) Xeon(R) CPU E5-2620 v4 @ 2.10GHz (Mono)
- Contexte : Coding
| Durée des réponses | Qualité des réponses |
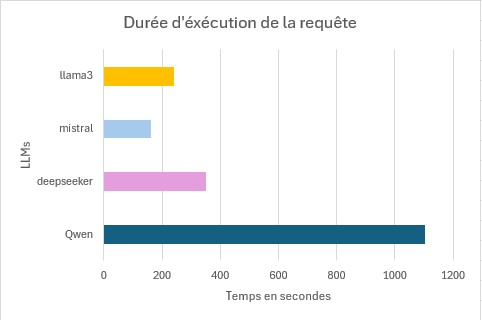 | 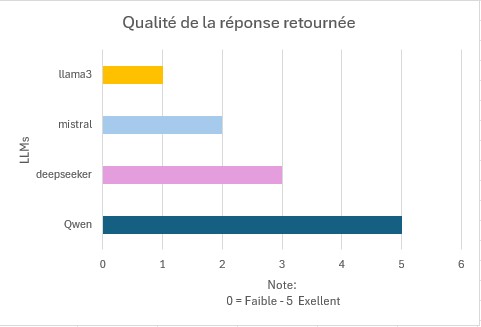 |
En conclusion Qwen est de loin celui qui met le plus de temps à délivrer la réponse. Cela s’explique par une explication plus poussée ce qui prends un certain temps à l’affichage. Cependant la qualité de la réponse retournée est de loin supérieur aux trois autres LLMs.
Il serait intéressant de pousser la comparaison sur un prompt de réflexion pur.
De tous les tests de modèles (du moins sur les quatre déployés) c’est qwen qui me convient le mieux. Néanmoins tout dépendra encore une fois du contexte et de ce que je souhaite réaliser avec l’IA.
Conclusion
Je suis plutôt satisfait bien que sans répondre aux prérequis il faut savoir s’armer de patiente. Dans l’ensemble Ollama est une bonne solution mais cette dernière doit être utilisé avec un certain contrôle selon les LLMs que l’on pourrait être amené à utiliser. Naturellement le retour de prompt vient de la qualité de celui que l’utilisateur aura exprimé.
De ce fait, Ollama ne garantit pas une fiabilité aussi conséquente que les géants du Cloud. Toutefois il permet d’assurer la confidentialité, sécurité des données localement et de nos recherches contrairement aux outils en ligne.
Ce qui pourrait toutefois rebuter son usage serait de passer par l’interface CLI dans le terminal. Effectivement c’est loin d’être ergonomique pour un usage quotidien d’un utilisateur n’ayant pas d’expérience dans ce domaine. Mais il existe toutefois des alternatives à cette problématique par des outils intermédiaires qui viennent se placer entre l’utilisateur et Ollama. Ce sujet sera abordé dans un prochain billet.
Initialement, je souhaitais aborder le sujet dans ce billet mais cela aurait été trop indigeste. Donc j’ai CUT comme on dit dans notre milieu 🙂
Ollama fournissant une documentation riche et simple il sera alors possible de jouer avec son API. Vous me connaissez avec le temps, s’il y a une documentation, une API… Que vais-je bien pouvoir faire avec le framework .NET et Powershell ? 🙂 L’objectif serait de proposer par exemple un petit client de bureau Windows pour les utilisateurs. Il serait également possible de mettre en place des passerelles d’automatisation inter applicatives intelligente comme L’ouverture d’un incident sur un event VEEAMOne dans ITOP ou une fonction de contrôle de code depuis PowerShell ISE par exemple.
Cette étude m’ouvre un nombre de porte considérable en guise de projet et de sujet d’étude et ce malgré les contraintes matérielles. Est-ce que je vais utiliser longtemps la solution, je ne pense honnêtement pas car cette dernière est assez énergivore pour mon petit lab et je ne travaille pas chez EDF ni n’habite Versailles. Mais cela peut (pour ne pas dire m’a) réconcilié avec l’utilisation de l’IA. Comme quoi il n’y a que les cons qui ne changent pas d’avis et nous sommes tous le con d’un autre.
Le mot de la fin :
J’ai cherché votre nom sur Ollama ? Comme ça vous êtes triple champion du monde de descente de Guiness catégorie galopin ?
Vous devez faire erreur avec une autre personne, je suis un DC10 fantôme sortant d’une tempête codéinée.
Milles excuses M’sieur Ollama.
Erwan GUILLEMARD
Sources
- Définition Larousse
- Wikipédia : IA
- DataBird : Type d’IA
- Ollama : Documentation
- Ollama : Téléchargement
- Ollama : Bibliothèque de modèle
- OpenWebUI : Documentation
- OpenWebUI : Intégration Ollama
- Comparatif : Modèles performances
- Comparatif : Modèles usages
- Usage de l’IA : DAFMag
- Répartition de l’usage : BPIFrance
- Usage de l’IA : LeMonde
- IA : Intelligence Artificielle ↩︎
- L’erreur est humaine, persévérer diabolique ↩︎
- CGU : Conditions Générales d’Utilisations ↩︎
- LLM : Large Language Models ↩︎
- GPU : Graphics Processing Unit ↩︎
- CPU : Central Processing Unit ↩︎
- SSD : Solid State Drive ↩︎
- DARPA : Defense Advanced Research Projects Agency ↩︎
- IHM : Interface Homme Machine ↩︎
- AGI : Artificial General Intelligence ↩︎
- SVM : Support Vector Machine ↩︎
- NLP : Natural Language Processing ↩︎
- RAG : Retrieval Augmented Generation ↩︎
- API : Application Programming Interface ↩︎
- HTTP : Hypertext Transfer Protocol ↩︎
- UTM : Unified Threat Management ↩︎