
Apps – PostgreSQL
Après les otaries, toujours dans le contexte des animaux je vais me déplacer latéralement vers l’enclos des éléphants.
Alors non je ne vais pas abandonner MariaDB. Ce billet simple et efficace traitera de la SGBD1 PostgreSQL. Le pourquoi de cet intérêt soudain se justifie par la rupture technologique de nombreux éditeurs du marché vers ce moteur puissant. Ne nous voilons pas la face, ce jour les grands acteurs de BDDs2 proposent des versions communautaires qui sont limités en termes de volumétrie et de fonctionnalité. Pour jouir de l’ensemble des fonctionnalités il faut passer à la caisse.
$$$ Bonjour le bandit manchot $$$
Les bases de données étant de plus en plus volumineuse et l’évolution que nous utilisateurs nous en faisons facilite auprès de ces mêmes éditeurs la mise à jour de leurs tarifications. C’est de bonne guerre (ou pas). Ce « ou pas » laisse donc la voie à d’autres alternatives. Plus simple, moins complexes et parfois plus puissante en s’alignant sur le principe de la philosophie OpenSource.
Je laisse une version communautaire, tu passes à la caisse si tu veux un service d’assistance ou de maintenance.
Il y aura toujours chez certains éditeurs quelques fonctionnalités en moins. Toutefois, je pense que c’est dans cette approche et la bonne et je réfléchis à adopter le même principe dans un projet de vie d’une plus grande dimension.
Bref, après cette marche de l’éléphant (sans prendre de LSD3 ou autres acides). Je me fais un petit guide sur PostreSQL 🙂
Avant-Propos
Il me semble important une nouvelle fois de préciser que ce billet portera sur le déploiement d’un environnement PostgreSQL dans sa dernière version stable à ce jour (release 18 en ce mois de grace Octobre 2025). Sur Windows, le déploiement ne m’intéresse pas des masses. Par contre sur un système GNU/LINUX, j’écris un OUI majuscule (gras, italique, souligné rouge !).
Bien que les chiffres ne soient pas réellement suivis, PostgreSQL estime la part d’environnement de production d’environ (lien) :
- 52 % l’usage sur les systèmes GNU/LINUX
- 23% l’usage sur les systèmes Windows
La raison de mon choix est que nous retrouvons un grand nombre d’appliance qui utilise PostgreSQL dans des environnements GNU/UNIX. Donc en tant que SysAdmin il faut bien savoir se positionner 🙂 (franchement, quelle remarque de me*de…).
Je considère que l’environnement sera durci selon les recommandations de l’ANSSI4 concernant les systèmes GNU/LINUX et comme d’accoutumé, je pars sur ma distribution RHEL favorite RockyLinux.
Prérequis
- SE :
- Rocky Linux 9.4 et version ultérieures
- Apps :
- PostgreSQL 18.4
- Autres :
- Non applicable
Théorie
L’implémentation d’un SGBD passe forcément par une réflexion de sa topologie. Nous ne balançons pas une application 1-tiers, on essaie à minima d’adopter une architecture 2-Tiers. Soit 1 serveur Frontend et 1 serveur Backend.
Pour des raisons qui sont évidentes (enfonçage de porte ouverte) une application publiée ne doit pas héberger la BDD. L’application doit être en DMZ5 et la BDD dans une autres bulles avec un contrôle des flux entrants et sortants interlans.
M’sieur? Et pour l’identification des flux ? Pour l’attribution des ressources ? Comment on fait ?
Donnez moi un R, un T, un F et un M… RTFM6 ! Il suffit encore une fois d’avoir le courage de se palucher le wiki de l’éditeur applicatif. Un peu d’huile de coude n’a jamais fait de mal.
Une fois la topologie bien pensée, passons à l’architecture de notre serveur BDD.
| Comme tout SGBD déployé il convient au minima d’implémenter la topologie ci-contre. Soit, un disque dédié au système UNIQUEMENT. Un disque dédié au stockage des données de notre SGBD et en dernier lieu un disque dédié au dump de nos BDDs avec une périodicité définie. J’ajouterai également un quatrième disque quant aux journaux de la BDDs et les journaux de transaction (les fameux transaction logs). Toutefois, ayant une petite infrastructure, je m’octroie le luxe de laisser ces derniers dans le /var/log. | 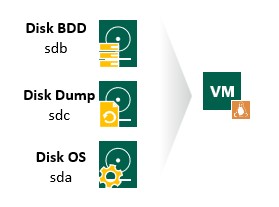 |
Hardware Requirements
Niveau des ressources là c’est une autre histoire… Si la documentation officielle nous communique les ressources et interopérabilités avec les dépendances tierces, je n’ai malheureusement pas trouvé d’informations sur les ressources matérielles. Dans un sens logique car cela va dépendre de ce que nous souhaitons traiter comme données etc.
J’ai donc décidé d’appliquer de mon plein gré et non sous la contrainte de calquer les recommandations MariaDB (lien). Toutefois, cela fait un peu beaucoup pour moi…
Je partirai donc pour un minimum 2 vCPU et 4 Gio de RAM. Dans l’idéal, je serai je pense sur du 4 vCPU et 8 Gio de RAM. Comme écrit plus haut, tout dépendra de ce que notre application va consommer en termes de traitement. Il faudra alors raisonner en bon père de famille (spéciale dédicasse) et ajuster les ressources afin d’éviter la sur ou sous allocation.
Côté réseau, la documentation nous indique que le port 5432/tcp est le port de communication par défaut. Surprise, nous pouvons changer le port dans le fichier de configuration…
Je pense qu’avec le peu de base énoncée, nous pouvons passer à la pratique.
Pratique
Un dernier point pour faire une magnifique transition entre la théorie et cette partie. Il est à noter que les dépôts officiels des distributions contiennent une version de la solution PostgreSQL. Toutefois, il ne s’agit généralement pas de la dernière version. Il est recommandé d’ajouter le dépôt de l’éditeur et de ne pas utiliser le dépôt système pour PostgreSQL.
Installation
Franchement, je trouve là la démarche super-mega overcool de proposer un webwizard pour définir comment déployer PostgreSQL selon les différents OS7 et distributions (nous noterons au passage un excellent usage de la figure de style hyperbolique) (lien).
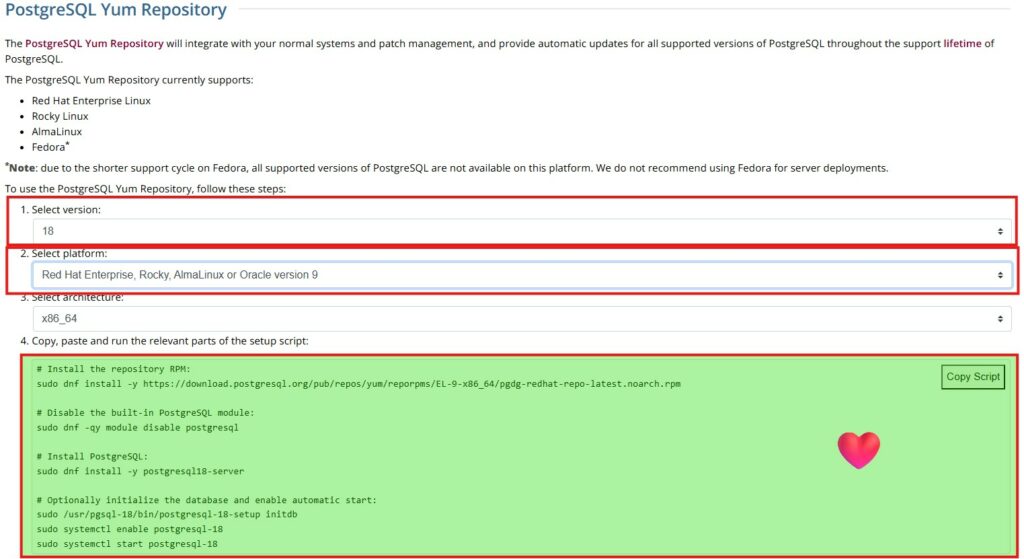
Je ne vais pas copier bêtement le script proposé. Mais reprendre chacune des lignes. Ce que je trouve admirable, c’est la simplicité du déploiement. Pas besoin d’installer 10k de dépendance en amont et de configurer ces dernières.
A partir du lien fournit par le webwizard installer le nouveau repo :
$ sudo dnf install https://download.postgresql.org/pub/repos/yum/reporpms/EL-9-x86_64/pgdg-redhat-repo-latest.noarch.rpm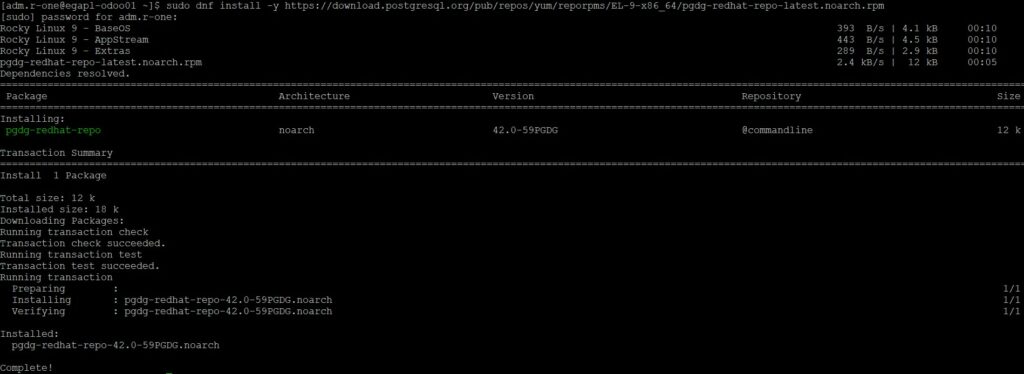
Comme indiqué précédemment, il convient de désactiver la version de postgreSQL contenu dans le repo par défaut. Ainsi, nous aurons une plus grande flexibilité dans le choix de version de nos composants.
A noter que mon système étant durci j’ai été contrait de réaliser l’opération en tant que root.
# dnf -qy module disable postgresql
Rien de plus simple, il suffit de faire une petite recherche par précaution puis une installation de notre package.
# dnf search postgresql18-server
# dnf install postgresql18-server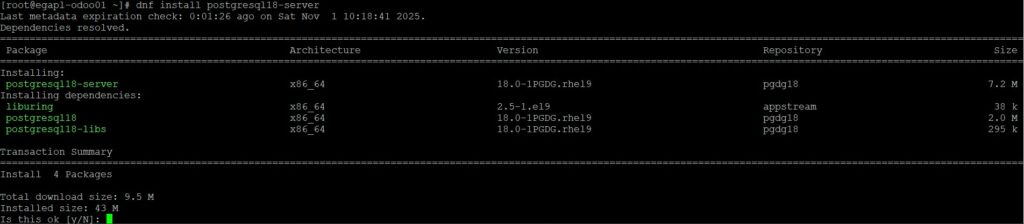
Comme tous SGBDs, il convient d’initier la première installation. Puis de s’assurer que le service va être lancer automatiquement au démarrage du système en cas de reboot.
Pour conclure, le traditionnel démarrage de notre daemon.
# /usr/pgsql-18/bin/postgresql-18-setup initdb
# systemctl enable postgresql-18
# systemctl start postgresql-18
Pour le fun, une petite vérification 🙂
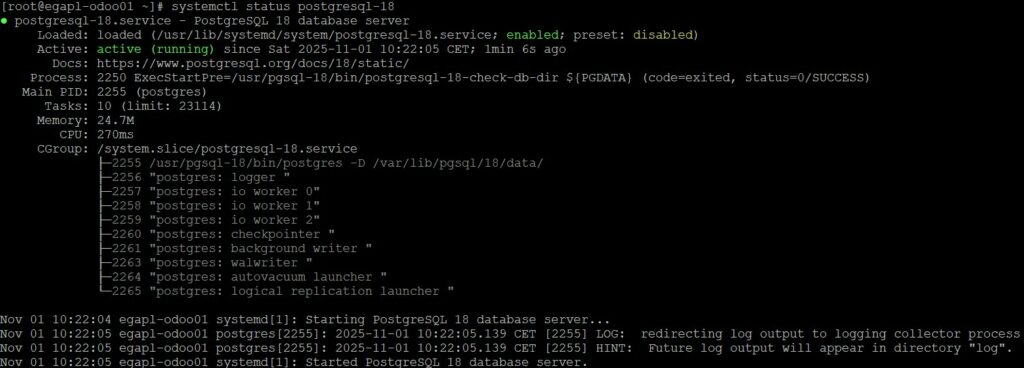
Notre daemon PostgreSQL étant déployé, j’arrive toujours à ce point d’application des bonnes pratiques systèmes. C’est là que ça peut être délicat si on se plante dans la configuration car cela peut mener à repartir de zéro. D’où l’importance de lire la documentation encore une fois.
C’est qu’un éléphant ça trompe énormément !
Et voilà comment on casse tout 😀
Déplacement de la BDD Location
Si nous gardons la topologie mis en place ci-haut, il sera nécessaire de déplacer le répertoire data stocké sur /var/lib/pgsql/18/data vers notre répertoire /mnt/database/postgresql/data monté sur notre disque /dev/sdb.
Je ne vais pas mentir, je me suis pris les pieds dans le tapis une fois et j’ai dû restaurer ma VM. Toutefois, les étapes ci-dessous sont bien éprouvées et valide.
La base de la base est donc d’arrêter le service postgresql :
$ sudo systemctl stop postgresql-18.service
$ sudo systemctl status postgresql-18.serviceIl est primordiale de s’assurer que le service ne tourne plus.
Sur notre partition /dev/sdb1 préalablement configurée et montée sur /mnt/database, nous allons créer et définir les droits et permissions pour autoriser notre compte postgres à accéder à ce dernier.
$ sudo mkdir /mnt/database/postgresql
$ sudo mkdir /mnt/database/postgresql/pg_sock
$ sudo mkdir /mnt/database/postgresql/data
$ sudo chown postgres:postgres /mnt/database/postgresql
$ sudo chmod 755 /mnt/database
$ sudo chmod 700 -R /mnt/database/postgresqlMais alors pourquoi 700 ? La base de donnée ainsi que l’ensemble des fichiers de ressources doivent être accessible uniquement de l’application par sécurité.
Comme j’ai pris l’habitude de faire comme pour MariaDB, je vais copier le contenu du répertoire data puis renommer la source afin d’éviter tous dysfonctionnements.
$ sudo rsync -av /var/lib/pgsql/18/data/ /mnt/database/postgresql/data/
$sudo mv /var/lib/pgsql/18/data /var/lib/pgsql/18/data.oriUne erreur classique lors de l’usage de la commande rsync reste l’oublie du /. Cela entrainera la copie du répertoire et non de son contenu uniquement. En gros, ça va bégayer dans les chemins (../postgresql/data/data/…).
Le service est configuré pour démarrer le daemon sous /var/lib/psql/18. Pour prendre en charge le nouveau chemin, il faut modifier ce dernier. La philosophie et de surcharger la configuration.
Créer le répertoire qui va contenir la surcharge de notre daemon psql :
$ sudo mkdir -p /etc/systemd/system/postgresql-18.service.dCréer un fichier de surcharge qui va contenir le chemin du répertoire data :
$ sudo tee /etc/systemd/system/postgresql-18.service.d/override.conf > /dev/null <<'EOF'
[Service]
Environment="PGDATA=/mnt/database/postgresql/data/"
EOFPar acquis de conscience, j’aime vérifier que le fichier est bien présent ainsi que le contenu de ce dernier.
$ sudo cat /etc/systemd/system/postgresql-18.service.d/override.confLe daemon ‘system’ a été altéré (puisque j’ai ajouté une configuration) et donc ? Un petit reload des familles pour prendre en compte le changement et zou.
$ sudo systemctl daemon-reloadUn étape un peu border avec la sécurité (comme un excès de Delirium un jeudi soir pour oublier une semaine compliqué).

Toutefois, il est important de noter un petit point et non des moindres sur notre fichier /etc/fstab. Il va être nécessaire d’ajouter le contexte sur notre partition et de relabeliser notre point partition.
Editons le fichier avec VIM, VI ou NANO puis modifier la ligne comme ci-dessous en ajoutant au niveau des droits defaults,context=system_u:object_r:postgresql_db_t:s0
Ce qui veut dire en SELinux :
- Defaults : Activation des droits standards
- Context=
- system_u : Identité SELinux, sans impact concernant notre SGBD
- object_r : Rôle d’objet de type fichier
- postgresql_db_t : Match avec le type de données PostgreSQL autorisé par SELinux. Ainsi, SELinux interdit à PostgreSQL d’accéder à des fichiers qui ne sont pas dans le contexte.
- s0 : Le niveau de sécurité par défaut.
Il sera nécessaire de définir le bon contexte sur notre nouveau répertoire.
$ sudo semanage fcontext -a -t postgresql_db_t "/mnt/database/postgresql(/.*)?"
$ sudo restorecon -Rv /mnt/database/postgresql/Le moment de vérité.
Vais je vomir l’ensemble de mes bières et commander une nouvelle tournée pour noyer mon échec ou commander une nouvelle tournée pour célébrer le succès de cette opération ? 🙂
$ sudo systemctl start postgresql-18
$ sudo systemctl status postgresql-18Il faut noter que le service fonctionne. Néanmoins, il convient de se demander si nous pouvons requêter notre BDD à la suite de ce changement.
$ sudo -u postgres psql -c "SELECT version();"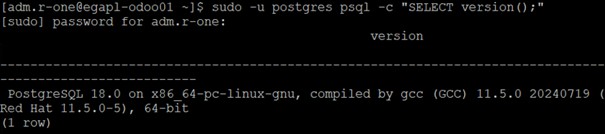
Vérifions également que le chemin du PGDATA a bien été pris en compte.
$ sudo -u postgres psql -c "SHOW data_directory;"
Ouf ça fonctionne 🙂
Place à l’étape suivante ! BA-BA-BAR POM POM POM POM
Sécurisation & Configuration
Nous revenons encore et toujours au même point. Qui dit données implique la sensibilité de ces dernières. Aujourd’hui braquer une banque ne rapporte pas grand-chose. Le rapport bénéfices/risques n’est pas bon… Mais braqué des données, utiliser ces dernières et les revendre apporte un bien meilleur rapport en termes de bénéfices / risques.
Donc, je me retrousse les manches car je ne suis pas un manche !
Si du côté MariaDB il existe le fameux mysql_secure_installation, ce n’est malheureusement pas le cas chez PostgreSQL.
Il se pose alors de dresser un inventaire rapide des points que nous souhaitons sécuriser :
- Mot de passe du compte postgres
- Restreindre l’accès réseaux
- Mettre en place une stratégie d’authentification
- Utiliser des algorithmes de chiffrement fort
- Supprimer les BDDs inutiles
- Droits sur les fichiers
- SELinux
- Firewall embarqué (même si je préfère le terme embedded)
- Audit et Journaux d’événements
Ca fait une petite tripoté n’est-il pas ? Naturellement, certains des points ci-haut ont déjà été traité lors du déploiement et du changement d’emplacement de la base de données.
Comme pour MariaDB (compte root), l’utilisateur postgres ne possède pas de mot de passe. Il convient par sécurité de définir ce dernier afin qu’il ne vienne une idée à un individu malveillant (comme un RSSI 8lors d’un audit ou pire un SysDBA9) de mettre sa truffe humide dans notre BDD.
$ su - postgres
$ psql -c "alter user postgres with password 'MyP@ssw0rd'"
Il est important de faire un petit clear de l’historique de frappe. Un mot de passe en clair c’est pas cool.
Ouvrons le fichier de configuration /mnt/database/postgresql/data/postgresql.conf.
Attention comme indiqué précédemment, il faudra être authentifié en tant qu’utilisateur postgres ou root.
Recherchez la section CONNECTIONS AND AUTHENTIFICATION.
Se pose alors la question, depuis où je peux consulter ma BDDs et sur quel port ? Personnellement, le port je le laisse par défaut soit 5432/tcp. Toutefois, la source, il est bien de spécifier le subnet ou les adresses IPs qui sont autorisé à se connecter à notre SGBD. Naturellement, la valeur ‘*’ est proscrite.
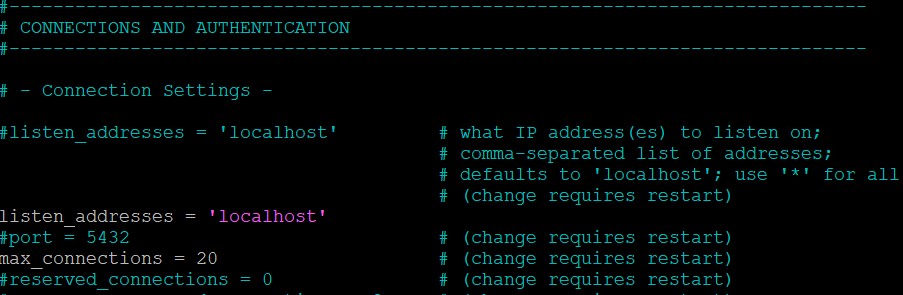
Ce paramétrage va de pair avec la configuration de notre UTM10 embedded (cf le point plus bas).
On va changer de fichier. L’objectif est de définir qui va se connecter à quoi, comment et depuis où.
Direction /mnt/database/postgresql/data/pg_hba.conf
La logique de lecture est la suivante TYPE correspond à la nature de l’authentification (local? hôte ?) pour quelle DATABASE (all ? replication ? db_test ?) pour quel USER (all ? r-one ?) depuis quelle ADDRESS (127.0.0.1/32 ? 0.0.0.0/0 ? 10.36.16.0/24 ?) et par quel METHOD (peer ? scram-sha-256? MD5?).
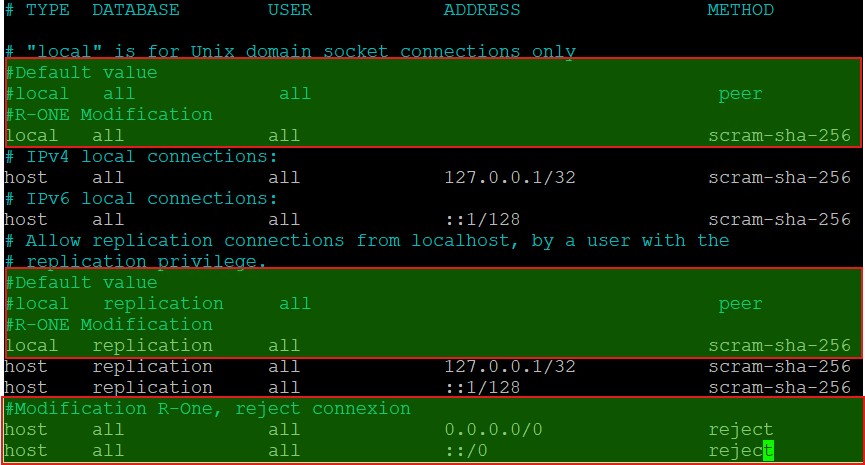
Il est certain qu’il faut limiter l’usage au maximum du all comme du masque 0.0.0.0/0. Toutefois, il n’y a pas de base les paramètres « implicites » de refus des connexions. C’est donc à implémenter (dernières lignes de la capture d’écran).
On sauvegarde, puis on reload le service.
$ sudo systemctl reload postgresql-18Toujours dans le fichier de configuration /mnt/database/postgresql/data/postgresql.conf. Attention comme indiqué précédemment, il faudra être authentifié en tant qu’utilisateur postgres ou root.
Recherchez la section CONNECTIONS AND AUTHENTIFICATION et activez l’algorithme de chiffrement scram-sha-256. Le MD5, nous passons notre tour hein ? Autant allez aux champignons sans capotes, c’est du pareil au même.

Il est important de lister les bases présentes sur notre SGBD et de supprimer les bases qui ne servent à rien.
$ su - postgres -c "\l"
$ psql
postgres=#\l
postgres=# DROP DATABASE NAME_BDD;
Attention : Il ne faut en aucun cas supprimer les bases template0 et template1. Ces dernières permettent (pour la 1) de générer les futurs BDDs) et (pour la 0) de regénérer la BDD de modèle.
Comme expliqué ci haut et pour des raisons évidentes. L’accès aux données doivent être accessible uniquement du compte utilisateur postgres et root. Pas de quoi foutez milles éléphants…
Je glisse toutefois les commandes.
$ sudo chown -R postgres:postgres /mnt/database/postgresql/data
$ sudo chmod 700 /mnt/database/postgresql/dataNous retrouvons la commande saisie ci-haut si nous avons modifié le database location.
Ainsi nous définissons le contexte de fichier de type postgresql_db_t à l’ensemble des éléments qui sont situer sous /mnt/database/postgresql. Puis on restore le contexte.
$ sudo semanage fcontext -a -t postgresql_db_t "/mnt/database/postgresql(/.*)?"
$ sudo restorecon -Rv /mnt/database/postgresql/Avant c’était iptables maintenant c’est firewalld ou ufw. Personnellement je reste sur la configuration de firewalld.
Il convient d’autoriser les flux 5432/tcp dans notre firewall si des connexions se font depuis un autre réseau ou une autre machine.
$ sudo firewall-cmd --permanent --add-service=postgresql
$ sudo firewall-cmd --reload
Cela étant, il serait également plus précis de filtrer les connexions entrantes sur un réseau ou une adresse ip uniquement sur le port 5432/tcp.
J’assume cette configuration du fait de mon UTM en amont qui filtre l’ensemble des flux inter-lans.
Ouvrons le fichier de configuration /mnt/database/postgresql/data/postgresql.conf. Attention comme indiqué précédemment, il faudra être authentifié en tant qu’utilisateur postgres ou root.
# vim /mnt/database/postgresql/data/postgresql.confSe rendre ensuite dans la section REPORTING AND LOGGING. Puis vérifiez que la configuration suivante est active.
| Activation de logging_collector sur on afin de récupérer les erreurs sous la forme json ou csv. L’emplacement où va être stocké les journaux. Par défaut celui-ci se trouve dans le répertoire log. Il faudra renseigner si l’emplacement est différent le chemin absolu, le chemin relatif si c’est un cluster. log_directory = ‘log’ Le nom du fichier, par défaut ce dernier est sous le format postgresql-%Y-%m-%d_%H%M%S.log. log_filename = ‘postgresql-%a.log’ Activer la journalisation pour l’ensemble des événements de connexion et de déconnexion. log_connections = on log_disconnections = on En guise de traitement des logs, nous choisirons ddl pour avoir les définitions des commandes utilisés. Attention, l’usage de all peut être dangereux vis à vis des ressources. log_statement = ‘ddl’ | 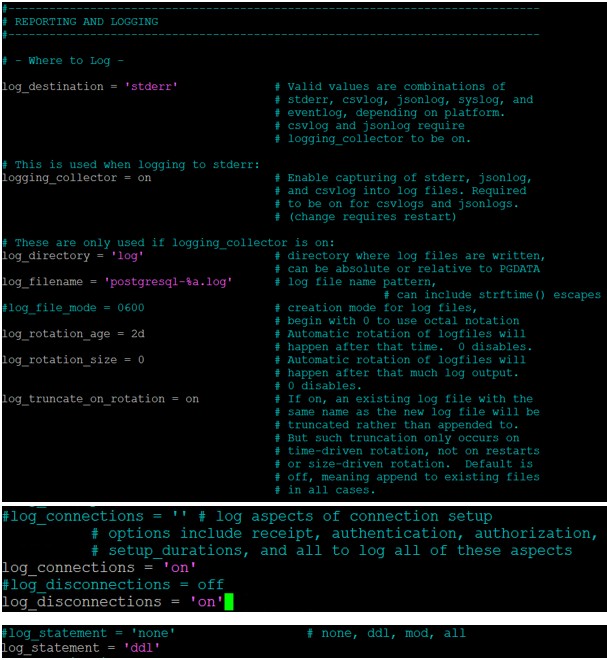 |
Une fois les modifications apportées, n’oubliez pas que notre serveur PostgreSQL à besoin d’être redémarré :
$ sudo systemctl restart postgresql-18Pour une configuration spécifique comme la gestion de la mémoire allouée, les fonctionnalités et j’en passe. Je pense qu’il est inutile d’aborder cela dans ce billet.
Pourquoi ? Parce que cet aspect-là et intrinsèquement lié aux dépendances des applications qui nécessite le SGBD PostgreSQL.
Premiers Pas
Cette sous partie vise plus à entrevoir les commandes de bases pour instancier une BDD dans le cadre de déploiement d’une application (spoiler Odoo par exemple ?).
Je n’ai pas la prétention de réinventer la roue, il existe la documentation pour cela et je n’ai pas non plus la prétention de devenir SysDBA. J’ai juste envie de faire les choses bien et surtout en suivant la doctrine des 3S, Simple, Standard et Sécurisé (14 ans d’ESN11 ça vous forge un homme !).
Création d’un user
La création d’un utilisateur suit un paradigme différent de MariaDB. La finesse de l’application du contexte d’un utilisateur se fera dans le fichier pg_hba.conf.
$ psql -U postgres
postgres=# CREATE USER user_odoo WITH PASSWORD 'MyPassw0rd';
Création d’une BDD
La création d’une BDD nécessite qu’un utilisateur (de la SGBD naturellement) ait le privilège CREATEDB ou d’utiliser un compte super utilisateur. Cela parait logique mais pas pour tout le monde. La documentation nous rappelle que la création d’une nouvelle base de données sera effectué en réalisant un clone de la BDD template1 (si, le truc qui ne fallait pas supprimer).
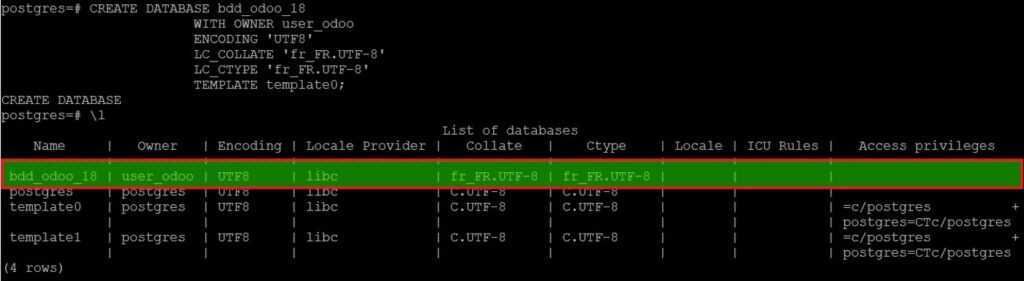
postgres=# CREATE DATABASE bdd_odoo;Toutefois, nous pouvons allez plus loin en définissant le propriétaire de la BDD, le jeu de caractère de la BDD ainsi que la collation locale afin de faciliter le tri des chaines. Par exemple :
postgres=# CREATE DATABASE bdd_odoo_18
WITH OWNER user_odoo
ENCODING 'UTF8'
LC_COLLATE 'fr_FR.UTF-8'
LC_CTYPE 'fr_FR.UTF-8'
TEMPLATE template0;/!\ ARTUNG /!\ Bicyclette et petit vélo !
| Il n’est pas impossible que vous tombiez sur une erreur de ce type « invalid LC_COLLATE locale name« . Cela signifie que tu vivras ta vie sans aucun soucis. (Tes vraiment sûre ?) En gros, il manque le fichier de mappage de caractère au niveau système. Soit il n’est pas présent, soit il n’est pas généré. | 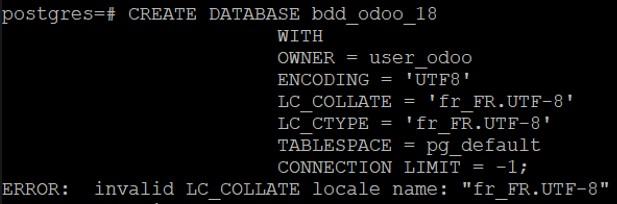 |
Afin de vérifier si ce dernier est présent :
$ sudo locale -a | grep frSi cela ne retourne rien c’est que le packet ne doit pas être installé. Alors installons le vin diou !
$ sudo dnf install glibc-langpack-fr
$ sudo locale -a | grep fr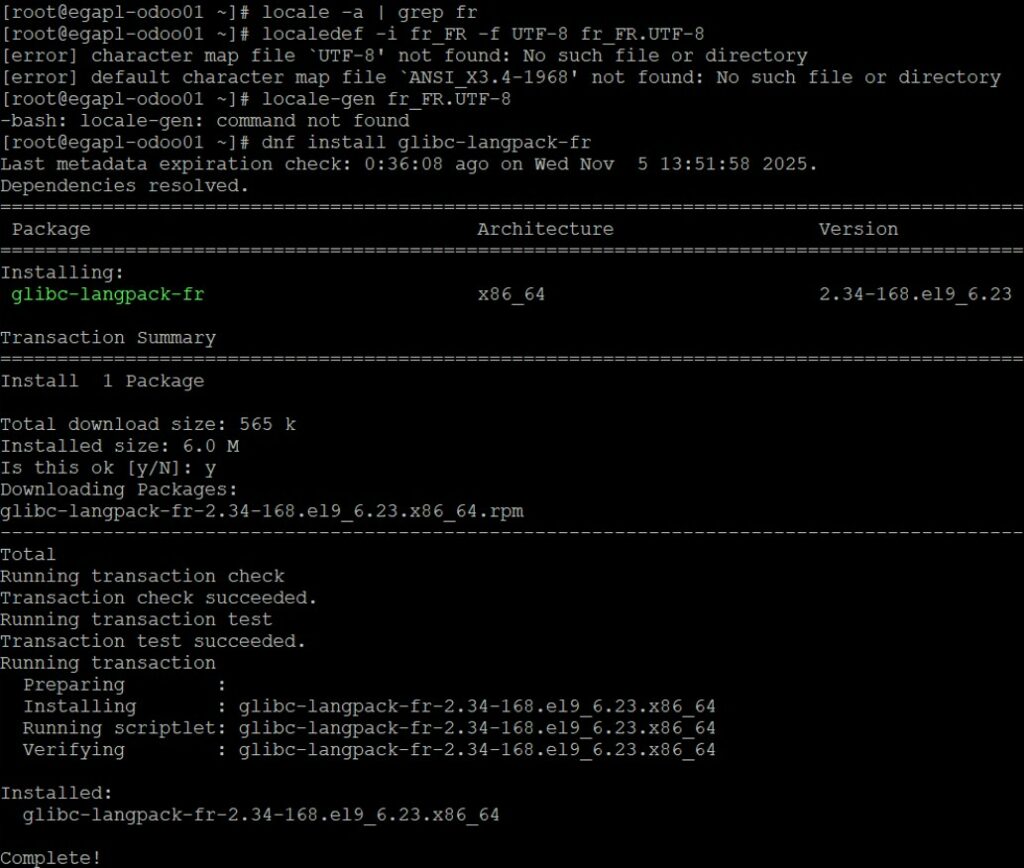
Surprise le fichier de mappage est présent ! Si nous rejouons la requête, cela fonctionne.
Attribution des privilèges et rôles
Comme tous systèmes de base de données, un incontournable reste la notion de rôle et de privilège.
Dans la pratique, il convient et je sais que j’enfonce une porte ouverte d’adopter la bonne pratique de créer des rôles et d’affecter les rôles aux utilisateurs. Un rôle sur la BDD en modification, en lecture, superutilisateur ect.
Ainsi et c’est d’une logique implacable, si modification il doit avoir, je ne modifierai QUE le rôle et non utilisateur par utilisateur. MALINX le LYNX…
Rôles
Par défaut, nous retrouvons :
| SUPERUSER | Accès total à tout le serveur |
| CREATEDB | Peut créer des bases de données |
| CREATEROLE | Peut créer, modifier ou supprimer d’autres rôles |
| INHERIT | Hérite des privilèges des rôles dont il est membre (activé par défaut) |
| LOGIN | Peut se connecter à PostgreSQL |
| REPLICATION | Peut initier des connexions de réplication |
| BYPASSRLS | Ignore les politiques de sécurité par lignes |
Toujours dans le spoil (parce que je suis un mec underground moi. MOUMOUNIGAN !) je vais créer un rôle pour ODOO qui permettra uniquement de se connecter, de créer une bdd avec un mot de passe.
postgres=# CREATE ROLE r_odoo LOGIN CREATEDB;Pour attribuer le rôle à un utilisateur (en prenant toujours le cas ODOO avec notre role r_odoo et user_odoo) :
postgres=# GRANT r_odoo TO user_odoo;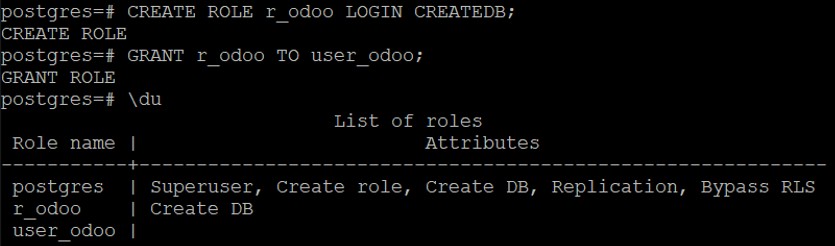
Privilèges
La notion de privilèges que ce soit sur la BDD, les tables où les schémas suivent le principe de SQL. Ainsi il suffira d’user des commandes GRANT accompagner de :
- CONNECT ON
- USAGE
- SELECT ON ALL
- SELECT, INSERT, UPDATE, DELETE
- ALTER
- DROP
- …
Il est important de prendre en compte que le propriétaire de la BDD a tous les droits.
Toujours dans notre exemple ODOO, il n’y aura donc pas de privilèges à appliquer.
PostgreSQL Client
Il existe un outil que j’ai découvert à travers un case chez VEEAM pour un problème de protection O365 du nom de pgAdmin. Cette solution officielle est l’outil graphique pour administrer PostrgreSQL.
Je pense important de présenter cette dernière car dans le cas où nous ne nous serions pas SQL native language ou seconde langue. Cela nous permettrait de bien comprendre certains dysfonctionnements ou structures.
L’installation n’est pas en soi bien complexe… Ma grand-mère y arriverait sans difficulté. Toutefois, je glisse le tips…
Certains pourrait dire, oui c’est un PHPMyAdmin. Oui c’est un fait. C’est une IHM12 en GUI13 pour faciliter l’expérience quotidienne.
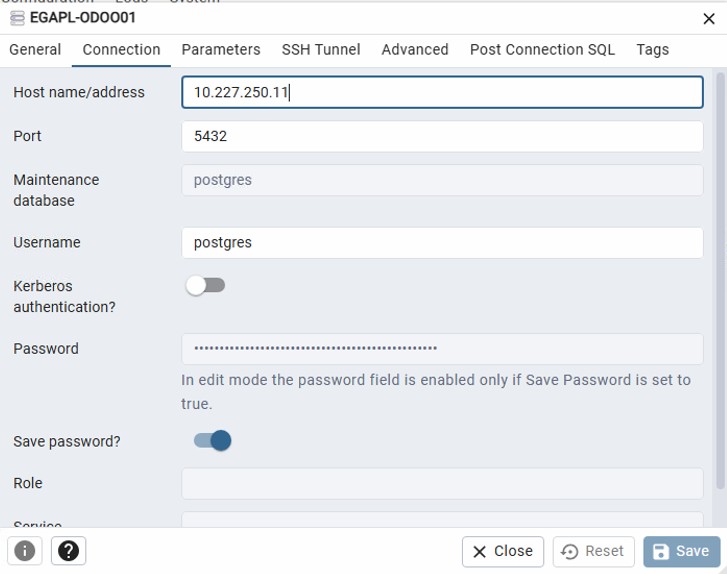
Pour se connecter, il suffira de renseigner les informations de connexion et de s’assurer au préalable que la politique de communication est bien présente sur notre UTM concernant les flux interlans. Sans oublier de vérifier :
- La configuration du fichier pg_hba.conf est compliante
- Les adresses d’écoutes dans le fichier postgresql.conf ne sont pas restreinte cas localhost et que le bind d’interface est bien configuré. (Le bind c’est l’ip de l’interface du serveur, pas l’adresse ip du client… Je dis ça parce que je vous vois venir hein !)
 |  |
Et si nous jetions un coup d’œil dans le viseur pour observer nos logs voir si on voit notre pachyderm numérique ?
$ sudo tail -f /mnt/database/postgresql/data/log/postgresql-Wed.log
Impeccable. Tout fonctionne 🙂
Conclusion
Ce billet revient aux prémices des premiers articles rédigés il y a maintenant quasiment deux ans. Quelques choses de simple qui vise à jouer les aides mémoires de ma cafetière qui commence à s’effriter.
Je ne tenais pas à me lancer dans un benchmark de « Est ce que l’otarie et plus fort que l’éléphant ? » cela ne m’intéresse pas le moindre du monde. Toutefois et comme j’ai pu l’aborder en avant propos, le tournant des éditeurs vers la solution PostgreSQL mérite de s’intéresser à cette dernière.
- VEEAM enchaine sa rupture technologique avec Windows (SE14 et/ou MSSQL) pour RHEL et PostgreSQL
- ODOO qui reste dans la philosophie du libre
- La Société Générale (faut bien renflouer les caisses après le passage de Jérôme KERVIEL… Ok, la blague est mauvaise, mais il fallait la faire. Trop tentante).
- Patrick BALKANY pour gérer son patrimoine non déclaré. Ah non autant pour moi c’est une fake news… Que je suis naïf 🙂
Au delà des deux derniers points douteux, il est bien je pense de se garder deux SGBDs relationnels sous le coude les solutions MariaDB et PostgreSQL. L’implémentation de la couche de sécurité relève d’un défi parfois mais reste nécessaire et plus qu’indispensable de nos jours.
Il manque toutefois un point que je n’ai pas développé ici. La possibilité de sauvegarder une base de manière périodique. J’avais traité le sujet pour MariaDB à la suite d’une connerie de ma part un vendredi aprem sur l’environnement de production. Je pense qu’il serait bien de reprendre ce projet et de l’adapter pour PostgreSQL 🙂
Ca fait un sujet supplémentaire à traiter d’ici la fin d’année. Mais surtout, le levé de voile ayant été fait un poil plus tôt ce billet est le tremplin pour l’implémentation d’ODOO comme mon ERP à venir.
Le mot de la fin :
Egaré dans la base de données infernale, le sysadmin se nomme R-ONE. A la recherche du datalocation, le problème s’appelle la durcification. Avec la solution VEEAM, il a pu rollback super vite. Dérivant à dos d’éléphant, R-ONE arrivera toujours dans l’étang… (faut bien se mouiller un peu qu’ils disaient les anciens)
Erwan GUILLEMARD
Sources
- PostgreSQL Secteur par OS
- PostgreSQL – Main Apps Guide
- PostgreSQL – Download
- PGAdmin – Download
- MariaDB – Hardware Requirements
- SGBD : Système de Gestion de Base de Données ↩︎
- BDD : Base De Données ↩︎
- LSD : LySergique Diéthylamide ↩︎
- ANSSI : Agence Nationale de Sécurité des Systèmes d’Informations ↩︎
- DMZ : Demilitarized Zone ↩︎
- RTFM : Read The Fuck*ng Manual ↩︎
- OS : Operating System ↩︎
- RSSI : Responsable Sécurité des Systèmes d’Informations ↩︎
- SysDBA : Administrateur des Systèmes de Bases de Données ↩︎
- UTM : Unified threat management ↩︎
- ESN : Entreprise des Services Numériques ↩︎
- IHM : Interface Homme Machine ↩︎
- GUI : Graphical User Interface ↩︎
- SE : Système d’Exploitation ↩︎