Apps – VBR Partie 1 : Théorie
Architecture & Best Pratices
Il est compliqué de donner un mode empirique d’une infrastructure VEEAM pour la bonne et simple raison qu’en fonction des autres produits et solution VEEAM qui peuvent graviter autour (VEEAMOne, VSPC, VCC etc). Toutefois, nous retrouvons sur l’infrastructure plusieurs rôles majeurs :
- Backup Server
- Proxy Backup
- WAN Accelerator (Optionnel)
- Mount Server
- Backup Repository
Le rôle qui nous intéresse le plus est Backup Server. Ce dernier est le cœur de l’ensemble de la solution et va venir piloter les autres différents rôles selon les tâches qui seront exécutées. Si nous devons décomposer le rôle, nous aurions le schéma suivant :
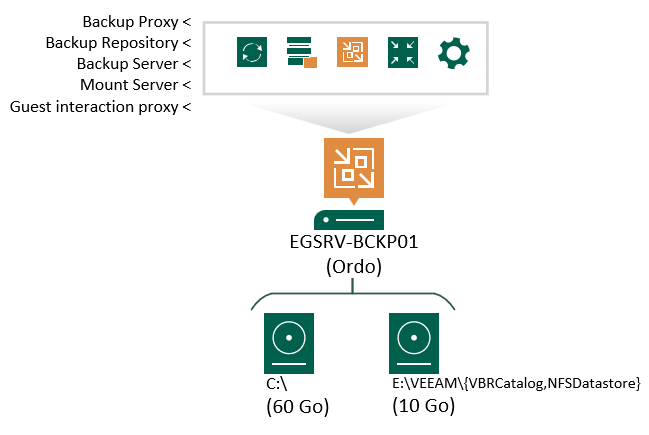
Attardons nous rapidement sur chacun des 5 rôles présents pour bien comprendre comment fonctionne un Ordonnanceur VEEAM.
Naturellement et pour chacun des rôles la liste des ports à autoriser sont disponible avec la description sur la page de l’éditeur.
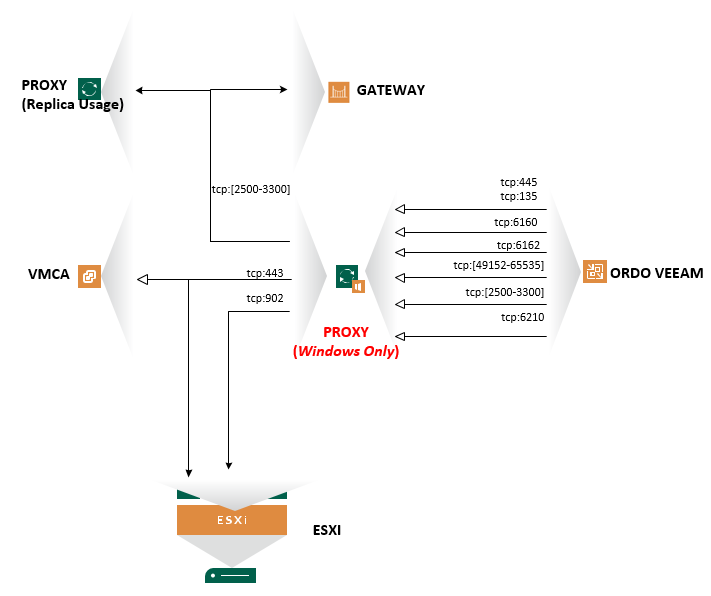
Ce rôle va permettre de traiter les instructions de sauvegarde définis par l’ordonnanceur. Il se situe entre le stockage, l’ordonnanceur et les ressources à sauvegarder. Que ce soit pour une infrastructure de sauvegarde composé que d’un ordonnanceur ou une structure avancée, le rôle proxy est d’office déployé sur le serveur d’ordonnancement.
Ce qui nous donne en théorie la topologie suivante :
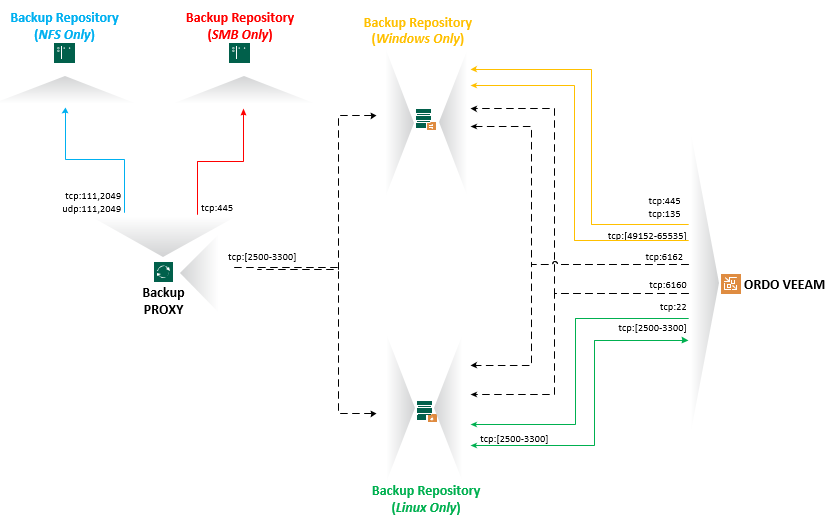
Ce rôle comme son nom l’indique, va servir a stocker les données sauvegardées par notre ordonnanceur VEEAM.
Au vu du nombre de solution existante, j’ai décidé de ne traiter uniquement que la partie NFS, SMB, Windows et Linux. Il serait facile de faire un billet par technologie de repo. Nous allons rester simple, basique.
Ce qui nous donne en théorie la topologie suivante :
Bien, bien nous avançons. Le rôle du serveur de sauvegarde a déjà été présenté. Ce dernier vous l’avez compris à pour objectif de définir et de piloter les jobs de protection (sauvegarde, externalisation, réplication etc).
Je passe volontairement le schéma. Pourquoi ? Parce que ce dernier va être imbuvable. Le serveur de backup et la tête pensante de l’infrastructure et interagie avec l’ensemble des composants VEEAM pour commencer et secundo il faut rajouter les dépendances externes (SMTP, Licence VEEAM etc). Je n’ai donc pas envie et je ne suis pas venu ici pour souffrir ok 🙂
Ce rôle est super important. Pourtant le nom au premier abord n’est pas bien parlant, même si nous pouvons facilement deviner.
Il permet d’assurer la restauration des éléments protégés. Soit réaliser l’ensemble des types de restauration proposés par VEEAM (objet, fichiers, éléments virtuels, VM, etc).
Ce qui nous donne en théorie la topologie suivante :
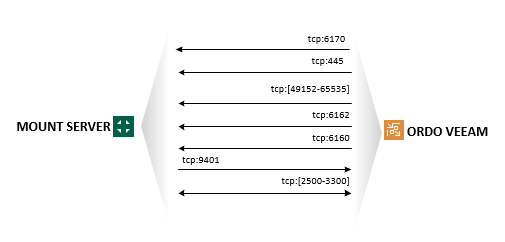
Attention, car d’autres éléments gravitent autour de ce rôle mais ne sont pas liés directement à ce dernier. Je m’explique. Lorsqu’une demande de restauration est initié, d’autres composants rentrent jeu tel que l’Helper Appliance Connection, l’Helper Host Connection et le Guest OS Connection.
Nos 4 éléments sont liés au processus de restauration, Guest OS File Recovery.
Naturellement, il existe différent type de restauration selon le média de destination. Les ports changeront donc selon si une restauration vPowerNFS, Microsoft Azure, AWS etc.
Ce rôle vient se positionner entre les ressources à sauvegarder (VMs) et le serveur de sauvegarde. Ce dernier va sur les ressources déployer des ressources consistantes ou non pour réaliser les protections à chaud des données.
Le cycle de vie, c’est par ici.
Ainsi, il est possible de définir plusieurs Guest Interaction Proxy dans un job pour améliorer les performances ou pour forcer un proxy spécifique pour un job de protection (subnet différent par exemple).
Ce qui nous donne en théorie la topologie suivante :
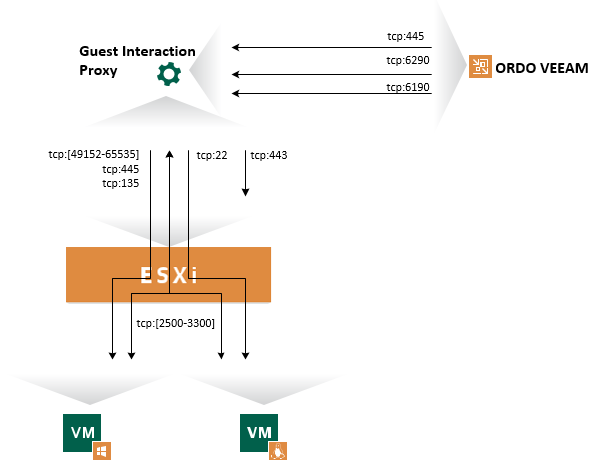
Je ne traiterai pas de la partie consistance pour ne pas surcharger le schéma. Néanmoins, vous retrouver le détail sur le site de VEEAM.
Dans tous les cas, les différentes machines (pour ne pas dire serveurs de préférence) doivent être hors domaine et isolé dans une bulle réseau à part ou dans le pire des cas uniquement dans la réseau d’administration.
VEEAM pour le coup assure une nouvelle fois en facilitant la mise en place et la sécurisation de son architecture auprès des SysAdmin en fournissant la matrice des flux réseau à implémenter (différent subnet ou micro segmentation).
Avant de définir l’infrastructure cible, il convient de se poser les questions :
- Qu’elle est la taille de l’infrastructure à sauvegarder ? Si l’infrastructure est conséquentes, l’ajout d’un Proxy Backup n’est pas du luxe.
- Qu’elle est la nature de mon infrastructure virtuelle ? Cas d’une infrastructure virtuelle, architecture HA (Baie de stockage et N Hyperviseurs) ou un seul hyperviseur, que choisir ? Nous étudierons les deux scénarios.
- Qu’elle va être la nature du stockage de destination qui va accueillir les sauvegardes ? NAS, Tape, Serveur, Média amovible ?
- Dans le cas d’externalisation, ai-je besoin d’un WAN Accelerator ?
- Plutôt du stockage block ou objet ?
Ca nous fait déjà un petit paquet de question. Mais pas de quoi s’affoler. Le plus difficile n’est pas l’implémentation mais la construction et sécurisation de notre infrastructure de sauvegarde.
La première vrai question est comment assurer la règle des 3-2-1-1-0.

| Objectifs | Réponses/Observations | |
| 3 | Avoir 3 copies différentes des données de production | Il faut prendre en compte 1 pour les données de production, 1 pour les données sauvegardées et 1 pour les données externalisées et optionnellement 1 pour les données déconnectées ou immuables. Soit un total minimum de 3 copies, 4 en incluant les données de production. |
| 2 | Avoir 2 médias/supports différents pour le stockage des sauvegardes | Dissocier le stockage de la sauvegarde sur 1 média et 1 média différent pour la copie de cette sauvegarde et optionnellement 1 média supplémentaire pour les données déconnectées ou immuables. Soit un total minimum de 2 médias, 3 en incluant les médias déconnectées ou immuable. |
| 1 | Avoir 1 copie hors site de production | Il est indispensable de réaliser la copie de la sauvegarde sur un autre site que le site de production. Il est possible de passer par un fournisseur pour stocker une copie de sa sauvegarde ou de réaliser un copie dans un Cloud Public (avec les avantages et inconvénients que cela peut entrainer). |
| 1 | Avoir 1 copie déconnecté ou immuable | Cette mesure vise à se prémunir des attaques visant à corrompre ou altérer les données sauvegardées. Si ces dernières sont sur un médias déconnectés, il est peu probable sauf s’il n’est pas déconnecté du SI d’être altéré… Quant à l’immuable qu’il soit hardened ou objet, le nom parle de lui-même. Les TAPES ou Bandes sont également une alternatives avec le Cloud. |
| 0 | Avoir 0 erreur dans les chaines de sauvegarde | Le dernier point consiste à vérifier la cohérence des chaines de sauvegardes et des différents points et d’affirmer que l’intégrité des ces derniers ne comportent pas d’erreur. |
Personnellement, j’arrive toujours à 3-2-1-1. Le 0 je n’ai jamais pu l’atteindre, par manque de temps. Cependant, grâce à ce billet, je vais enfin faire un grand pas en avant pour sortir du gouffre intellectuel dans lequel je commençais à me complaire.
Ensuite, il serait hypocrite de ma part de réinventer la roue. Puisqu’il suffit de RTFM1 le site de l’éditeur et de s’inspirer des différentes architectures (et des exemples mis en avant). Comme je l’ai dit plus haut il n’y a pas d’architecture empirique et cela dépend, fortement des équipements et ressources qui seront utilisés, des locaux, des contraintes de l’organisation et du PAS2 défini par la direction.
Alors pourquoi parler/écrire pour ne rien dire ? Tout simplement pour avertir sur le fait qu’on installe pas un composant VEEAM comme nous installerions NotePad++. Et qu’il faut bien penser à tout. Ce n’est pas quand la partie de Dungeon Keeper et lancée qu’on change les pièges, fallait y penser avant.
En gros pour moi avec une infrastructure classique, j’opterai pour l’architecture suivante à moindre cout.
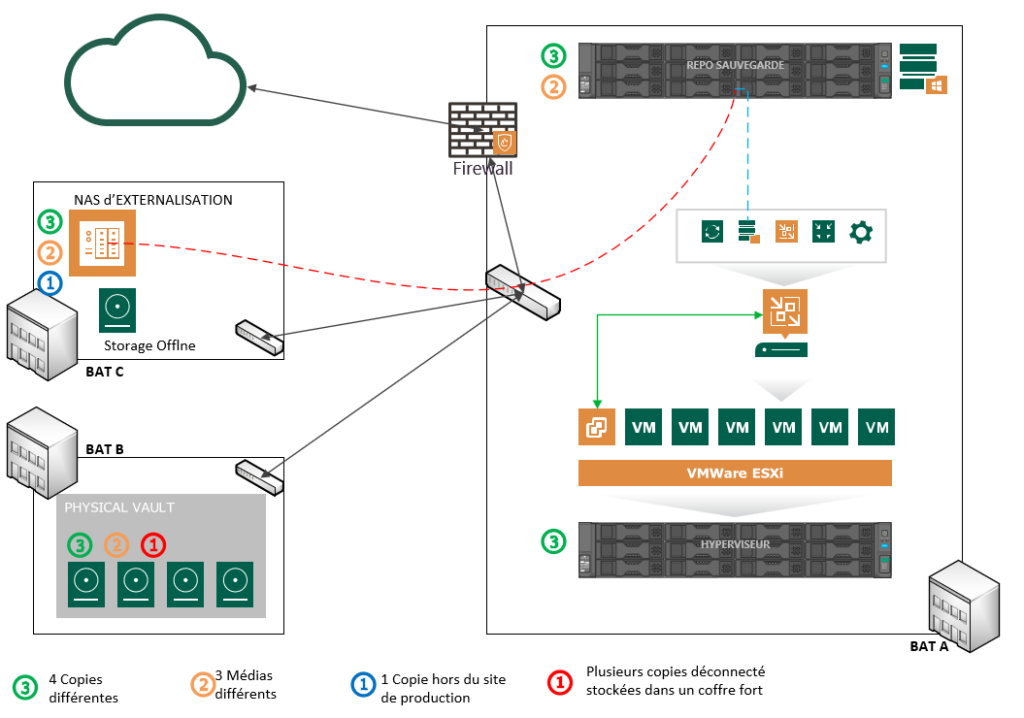
Ainsi en respectant les bonnes pratiques VEEAM, j’ai considérablement restreint le risque de mon système d’information. Certes, je considéré que sur un seul site, j’ai trois bâtiments interconnecté et que les bâtiments B et C sont suffisamment loin du bâtiment A. Avec les recommandations, nous constatons avec les deux schémas ci-dessous qu’il est possible de continuer ou de reprendre les données en cas de sinistre.
| Sinistre Site principal | Sinistre Sites Secondaires |
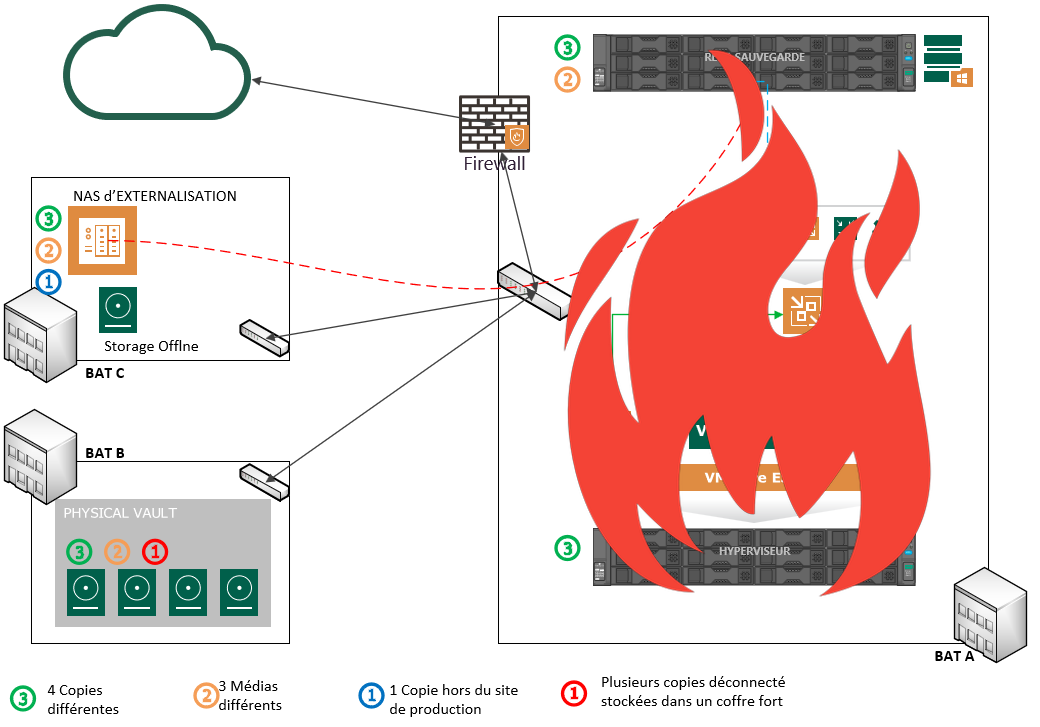 | 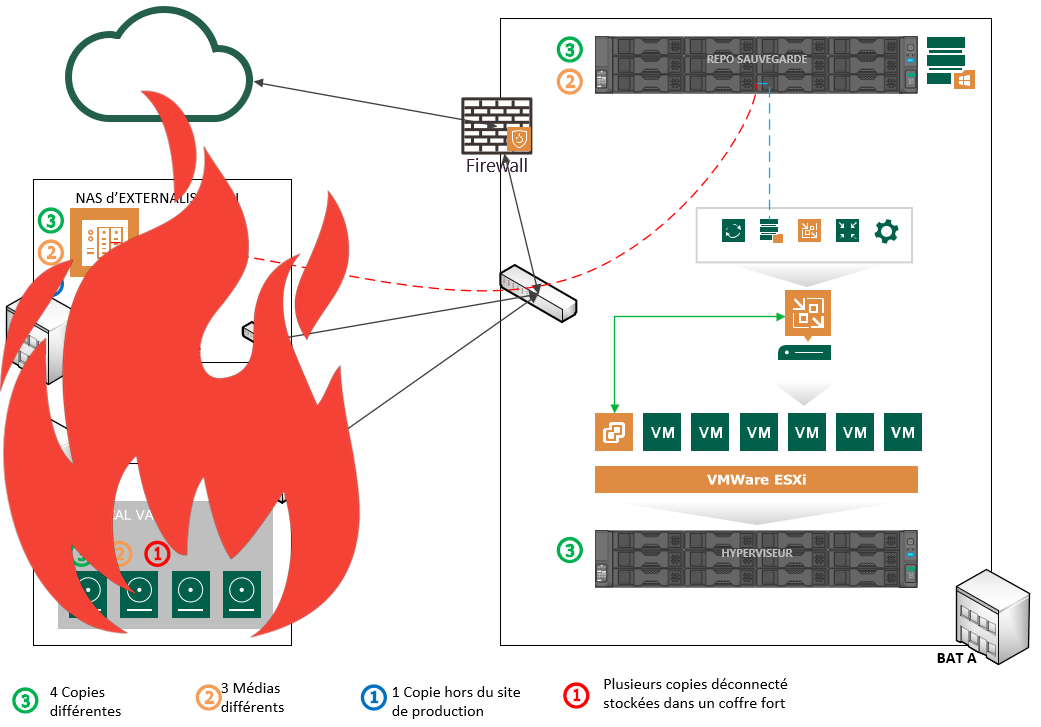 |
Quelque chose m’embête. Imaginons le cas où le sinistre concerne l’ensemble du site et donc les trois bâtiments ? Une externalisation de la sauvegarde (ou copie de la sauvegarde) sur un autre site ou un cloud privé, public assurerai une reprise d’activité MAIS nécessiterai un cout mensuel récurrent (entre nous largement acceptable).
Niveau sécurité, il convient de suivre les recommandations de l’éditeur et de durcir au préalable les environnements Windows. J’enfonce une porte ouverte, mais chaque mot de passe doit être unique et ne doit pas être réutilisé et TOUTES les sauvegardes doivent être chiffrées. Pour mieux comprendre la criticité de la chose j’oserai même à dire cryptées !
Vous avez tiré une carte lynchage. Les gars de la branche sécurité des systèmes d’informations vous jettent des clés FIDO et des dictionnaires Gros Larousse et Petit Robert pour votre hérésie !
Rien ne justifie de ne pas chiffrer ces sauvegardes, surtout quand ces dernières sont sur des médias qui peuvent être facilement perdu. D’ailleurs, un point et cas qui m’a marqué dans mes études lors d’un partiel portait justement sur le stockage des données amovibles. Le coffre fort. Ce dernier doit être assez robuste en terme de sécurité, mais doit être ignifuge et réfractaire.
Access & Less Privileged
Je traiterai et completerai au fur et à mesure cette partie car cela va dépendre des systèmes à lequel VEEAM va s’interconnecter (VMWare (vCSA, ESXi) ou Microsoft (HyperV)).
Cette partie (peut importe la solution à mettre en place) est un véritable casse tête. La simplicité voudrait que nous attribuons les permissions root ou system pour avoir la paix. L’objectif est de définir un compte dédié à VEEAMBR sur les plateformes de gestion de socle de virtualisation avec uniquement les permissions nécessaires.
Là, c’est plutôt simple, il suffit d’utiliser directement le compte root de notre VCSA.
NO WWWWAAAAYYYYY !
RTFM une nouvelle fois mon gars ! VEEAM explique ce qu’il faut faire (ici). Je ne vais donc pas m’attarder là dessus encore une fois (oui car c’est déjà abordé dans un article pas encore publié) :p .
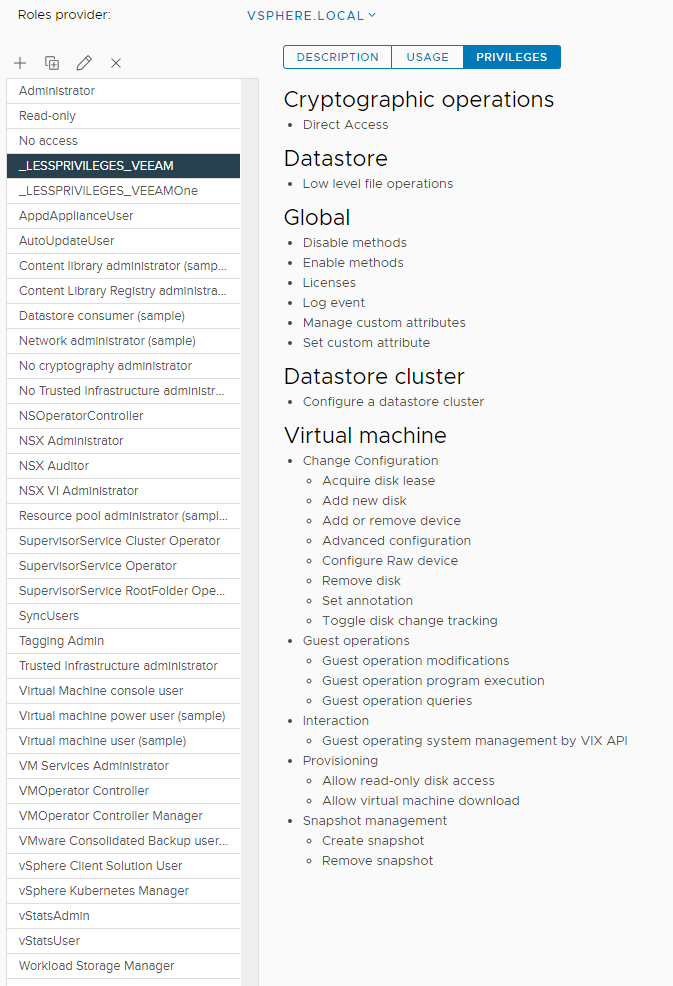
Pour cette partie, c’est un peu plus compliqué. Pourquoi ? Il faut tâtonner et créer ça propre politique (rôle). Si dans un sens nous pouvons nous appuyer sur la première étape de notre accordéon (partie précédente).
Je n’ai pas trouvé à ce jour de KB ou guide officiel uniquement pour la partie ESXi. Mais cela va t-il nous retenir pour autant d’innover ? Au pire ça ne fonctionne pas et nous aurons appris certaines choses. Au mieux ça fonctionne et nous aurons appris des choses. Dans les deux cas c’est win-win.
Bien que je ne l’ai pas encore testé, je dirai qu’une des bases serait du type :
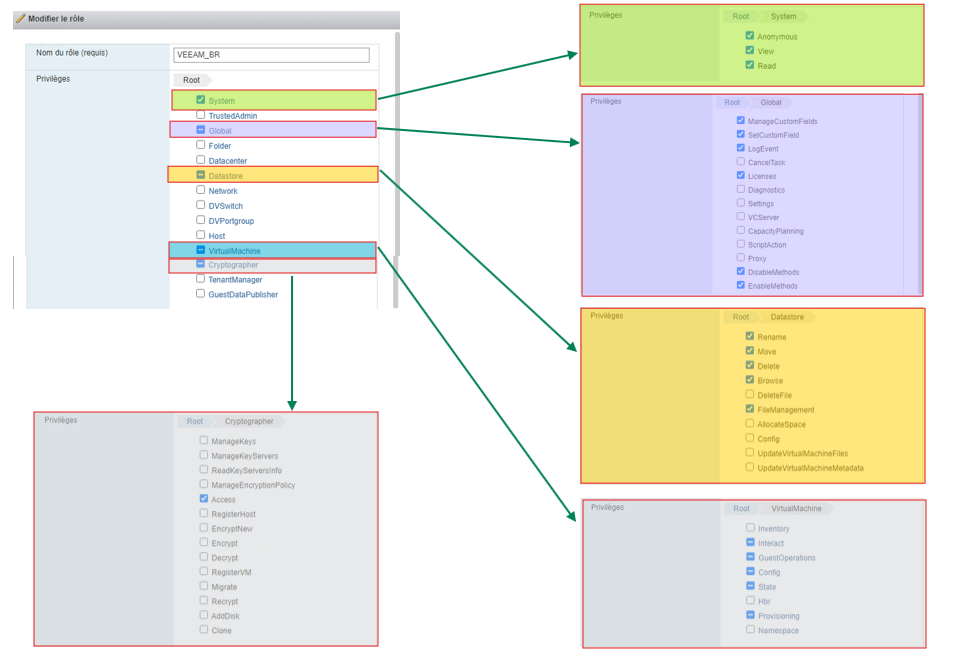
Je pense avoir fait le tour. Pour le reste, je vous invite à vous perdre dans le guide de VEEAM. C’est difficile de tout aborder et de ne pas tomber dans la paraphrase.