
Apps – VEEAM One
Avoir un système d’information, c’est bien. Savoir si ce dernier est en bonne santé c’est une autre paire de manche…
Pourquoi commencer ce billet en étant si désagréable ? Parce que le sujet de la supervision, surveillance ou « monitoring » représente un enjeu capital pour l’activité des entreprises et il existe un large panel de solution payante ou gratuite sur le marché. Toutes ces solutions ne couvrent pas les mêmes périmètres de surveillance. Il est donc facile de multiplier les applications et de ne plus savoir où donner de la tête.
Personnellement, j’aime dissocier la surveillance d’un SI avec 3 types de solutions :
- Firewall et Liens
- Réseau Local
- Equipements Infrastructures Physiques et Virtuels
Dans certains cas, une 4 et dernière brique peut être amenée à être utilisée pour superviser des services applicatifs. Néanmoins, je ne suis pas un grand fan de ce niveau de surveillance (mais c’est mon opinion personnel) et il faut bien justifier le poste d’un Responsable Informatique dans sa société non ? (Je suis réducteur, mais un RSI ça sert à bien d’autre chose et ça ne fait pas que de boire des cafés toute la sainte journée avec Martine de l’accueil. Coucou Martine 🙂 ).
Je souhaite donc aborder le point de surveillance « Equipements Infrastructures Physiques et Virtuels » à travers une solution payante.
Soyons claire sur un point car je vois venir les détracteurs de la communauté GNU/UNIX et autres DAFs (bien trop proche de leurs budgets).
« Ouai mais il y a des solutions gratuites sous licence GNU qui font très bien l’affaire. En plus tu n’arrêtes pas de nous em*****r avec tes RHELs. VENDU ! »
Mon avocat à la barre, commis d’office me représente et assure ma défense.
« Mon client, tiens à préciser qu’il présentera une solution de supervision libre dans un autre billet car il est important de couvrir un périmètre similaire et plus flexible. Mon client s’engage dans cette démarche pour réduire sa peine si toutefois il est jugé coupable. Dans un second temps, il est important de se rapporter à la maxime « Le pas cher coute trop cher ». Une solution libre et gratuite c’est bien. Mais le jour où le MCO ne se passe pas comme prévu il est facile de passer un nombre d’heure conséquent. Les solutions payantes offrent un service de support et de correctif en cas de vulnérabilité critique. » CHEH ! Et en plus je vais tenter de vous convaincre que nous pouvons gagner ou économiser du MONEY MONEY.
J’ai donc décidé, d’après le titre de ce billet de continuer avec les solutions VEEAM, VEEAMOne.
Pourquoi le choix de VEEAMOne ? La solution est cross plateforme et permet d’avoir une bonne visibilité sur le socle de virtualisation, les ressources virtualisées ainsi que l’ensemble des éléments et environnement propres à la sauvegarde (VBO365, VDP). La cerise sur le gâteau reste la partie Business View, Reporting et Capacity Planning. Mais promis, je reviendrai plus en détail sur ces points bonus.
Je me garde également pour plus tard un autre article pour lequel j’ai besoin de VEEAMOne 🙂
Prérequis
- SE : Windows Server 2k19 et version ultérieures
- Apps : VEEAM B&R 12.x, VEEAMOne 12.x, VMWare/Hyperv
- Autres :
- VEEAM B&R 12.x
- License VEEAM Entreprise
Avant-Propos
Dans une logique de garantir un niveau de sécurité optimal, j’ai dans un premier temps longtemps pensé que l’ensemble des environnements de surveillance (supervision/monitoring) devaient être dans le même subnet que les éléments d’administrations ou de management. Maintenant, mon approche est différente. Je préfère dédier un subnet pour l’ensemble des solutions.
Mais pourquoi ? Je juge ces éléments sensibles. Ils donnent une bonne, trop bonne visibilité sur l’ensemble du SI. Admettons que la bulle de monitoring soit compromise, il nous suffira de restreindre totalement les flux réseaux ou à en limiter les flux depuis des ressources isolés. De plus, et cela se vérifie avec le temps certaines solutions de monitoring apportent des fonctionnalités d’actions sur les ressources sous surveillance ou de remédiations automatiques. (Mon dernier HP Tour Customer & Partner nous indique bien la tendance de l’IA et sa capacitée [monstrueuse ?] de traitement). Bref, ce n’est pas un outil à mettre dans toutes les mains, c’est un coup à être satellisé…
Théorie
Architecture & Best Pratices
Encore une fois, chacun voit midi à sa porte. Il est donc compliqué de définir une MO1 empirique. Cela dépendra des technologies et solutions utilisées que ce soit en socle de virtualisation (VMWare, HyperV etc) et produits VEEAM (VBO MS365, VBR2, VCC3 etc).
Mais commençons par le début. Qu’est-ce que contient VEEAM One et qu’a-t-il dans le ventre ?
VEEAM One se décompose de deux grandes parties. Une partie client et une partie serveur.
Comme on s’en doute, cela permet d’accéder aux données des environnements virtualisés ainsi que les données relatives à la sauvegarde, réplication et autres. Toutefois, nous distinguerons deux types de client.
 | Client Lourd : Son objectif est de permettre à travers la console d’accéder à l’ensemble des données de manière efficiente et d’avoir une vue globale sur notre infrastructure et d’interagir avec ce dernier selon les alertes remontées par les différentes sondes. Il sera nécessaire de déployer/installer le client sur le poste concerné et d’ouvrir les ports.  |
 | Client Web : A l’inverse, la console web est moins orientée « opérationnelle » au sens technique, mais plus au sens qualitatif avec l’élaboration de rapport, de tableau de bord et de définir l’évolution du SI (capacity planning, optimisation des ressources, optimisation des couts etc). Si les flux sont ouverts, il suffira d’accéder à ce dernier à travers un navigateur web à travers l’url https://monserver.contoso.lab:1239  |
Ce qui nous donne le schéma des flux suivants.
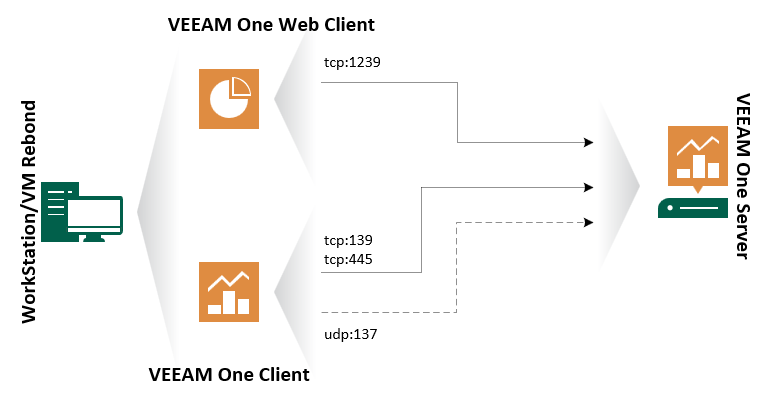
Donc si nous résumons, les choses. Le client lourd sera satisfaire les équipes opérationnelles et la partie client web les responsables / directeurs de services. Les jambes et la tête en sommes. 🙂
Dans son fonctionnement et c’est là l’une des forces de la solution. Le client lourd fonctionne sur la base d’une API. Ce qui implique que nous pouvons réaliser TOUTES les actions qui sont présents dans la console 😀 (Vous me voyez venir avec mes grosses charentaises ? )
La partie serveur est bien plus complexe. De facto, les deux clients présentés précédemment sont présents sur le serveur
- VEEAM One Client
- VEEAM One Web Client
Ce qui est logique puisqu’il faut bien administrer la solution…
Toutefois, nous rencontrons également les rôles suivants :
- VEEAM One Server
- VEEAM One Database
- VEEAM One Agent
- VEEAM One WebServices
Dans le détail de chaque rôle, la partie Server va servir à la collecte des informations, des données et stocker ces dernières dans la Database afin de pouvoir par la suite les restituer sur l’action de l’utilisateur à travers les clients (web ou lourd). Il est possible de mutualiser la base de données VEEAMOne (MSSQL) avec d’autres produits. Toutefois je préfère ne pas mettre tous mes œufs dans le même panier et tenter de mutualiser mes BDDs, cela reviendrait à essayer d’additionner un veau avec des cigarettes…
La partie WebServices permettra comme nous pouvons nous en douter de garantir l’accès depuis un navigateur web au WebClient ainsi qu’à l’API.
C’est quoi la partie Agent ? Ne me dit pas qu’il faut se palucher le déploiement d’un agent sur les ressources que nous souhaitons surveiller ? Si c’est le cas, j’arrête ma lecture après ta réponse !
La partie Agent n’est pas à déployer sur toutes les ressources et heureusement. VEEAM One a été pensé pour être flexible ! La communication avec les applications de virtualisation se font soit par le biais de protocoles « classiques » ou par les APIs constructeurs.
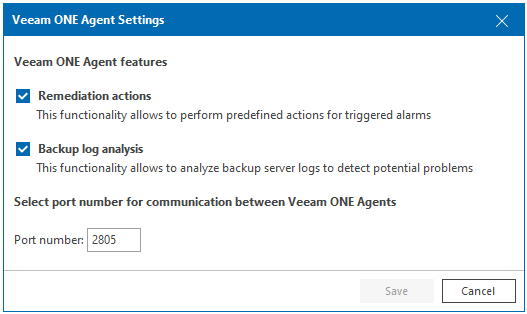
L’Agent est nécessaire uniquement lors du monitoring, de remonter d’informations (logs) et d’effectuer des commandes de remédiations si nécessaire entre les serveurs VBRs et le serveur VEEAM One. Le guide, recommande son installation, toutefois il n’est obligatoire de déployer l’agent (personnellement, pourquoi ne pas le faire ?).
La partie Agent comporte deux modes. Un mode client (paramètre par défaut) ainsi qu’un mode serveur. La différence entre les deux se trouve dans l’exécution des commandes de remédiation qui ne sont présentes que dans le mode client. La partie serveur quant à elle va gérer les mises à jour des signatures et analyser les journaux VBR.
Et si nous réalisions une petite Map des différents flux ? 🙂 Naturellement, je ne compte pas réinventer la roue, mais juste mettre en avant ce que je vais implémenter plus tard. Pour le reste, il suffira de consulter le lien constructeur.
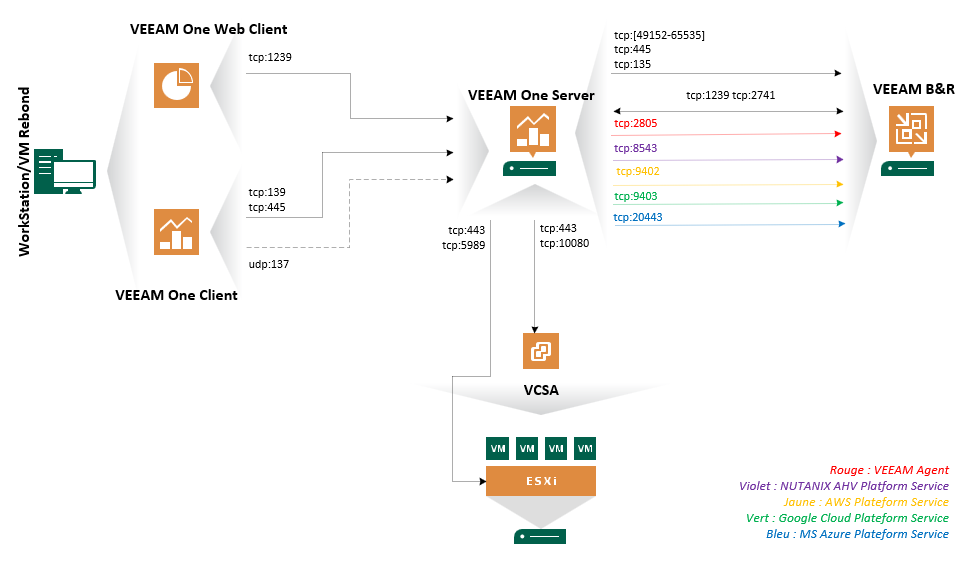
Comme pour le serveur VEEAM dans un billet précédent, une restriction des flux sortant vers l’extérieur est appliquée sur le serveur VEEAMOne. Ainsi, seul les URLs et NDDs habilités à communiquer avec VEEAM et MS sont autorisés.
Soit pour VEEAM One :
- Serveurs de mise à jour :
- dev.veeam.com
- Serveurs de licences :
- one.butler.veeam.com
- download2.veeam.com
Okay, maintenant que nous voyons un peu plus clair dans nos différents flux, posons-nous la traditionnelle question du « le principe de moindre privilège ».
Access & Less Privileged
Cette partie (peu importe la solution à mettre en place) est un véritable casse-tête. La simplicité voudrait que nous attribuions les permissions root ou system pour avoir la paix.
« Regarde, ça fonctionne ! » J’aime à répondre à ça soit par le traditionnel « Peinture sur merde égal propreté » ou « Je travaillais comme ça quand mon patron m’a viré« .
Soyons sérieux deux secondes… VEEAM nous mache encore une fois le travail et nous allons voir en détail comment configurer les différents comptes avec les moindres privilèges. Cependant, je pense utile de nous remémorer que dans certains cas, il est obligatoire d’attribuer des permissions d’administrateur du domaine ou à privilège (sudo) et malheureusement nous ne pouvons pas faire autrement.
Dans ce cas de figure, il est difficile de faire autrement. Néanmoins, nous pouvons et je dirai même c’est notre devoir de mettre tous les artifices en place pour restreindre le périmètre d’exposition de ce type de compte.
Nous distinguons dans notre cas 3 accès à configurer. L’accès à l’application, l’accès à notre socle de virtualisation et notre infrastructure de sauvegarde.
Dans le respect des bonnes pratiques, notre serveur VEEAM n’est pas joint au domaine. Nous avons besoin pour interconnecter VEEAMOne à notre serveur VEEAM d’un compte administrateur local.
Pourquoi ? Parce que VEEAMOne doit avoir les droits nécessaires pour déployer son agent. Comme présenté précédemment, il nous faut contraindre ce compte.
Typiquement, nous pouvons considérer ce compte comme une compte de service. Il nous faudra alors interdire les connections locales et distantes à ce compte directement sur le serveur VEEAM.
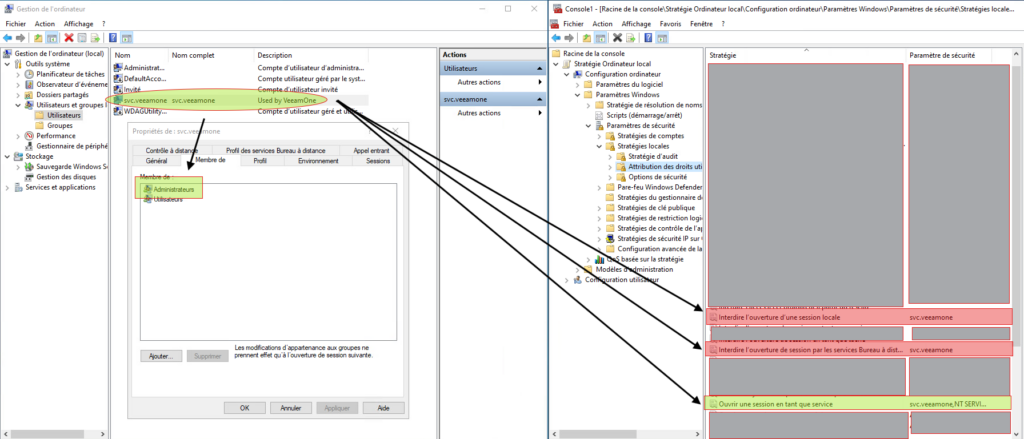
Attention, étant un compte local il sera nécessaire d’effectuer au minima une rotation du mot de passe une fois par an.
Là, c’est plutôt simple, il suffit d’utiliser directement le compte root de notre VCSA4.
NO WWWWAAAAYYYYY !
RTFM5 mon gars ! VEEAM explique ce qu’il faut faire (ici). Je ne vais donc pas m’attarder là-dessus.
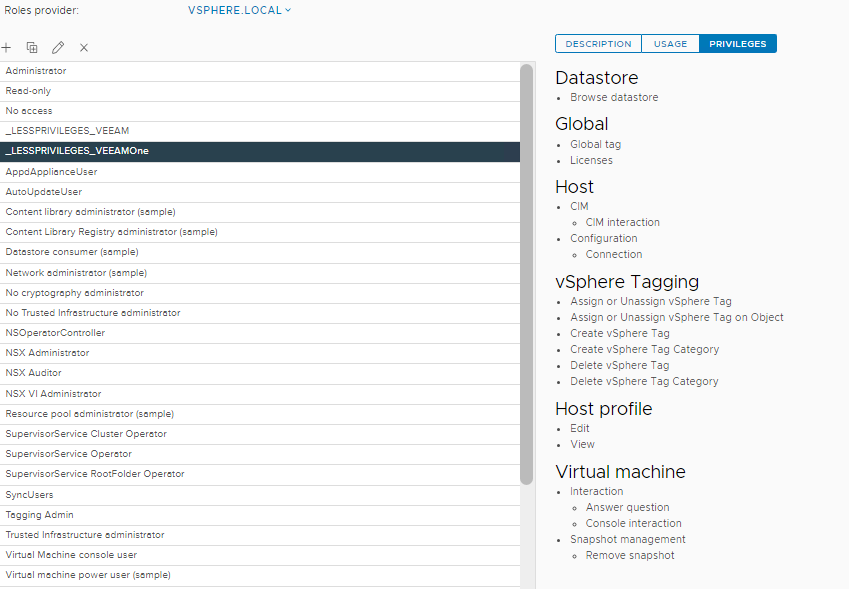
Là, il y a deux écoles. Je n’ai pas encore fait un article sur le sujet VCSA et personnellement je ne sais pas si j’ai envie d’en faire un car les interfaces changes tout le temps au gré des montées de version VMWare. Bref, il reste à définir si nous souhaitons utiliser des comptes locaux ou un compte du domaine pour interconnecter VEEAMOne à notre environnement VMWare.
Les raisons sont toujours les mêmes. Sécurité, Sécurité et Sécurité.
L’application se base également sur le principe de moindre privilège ainsi que sur le principe de RBAC6 (un truc vraiment cool pour les SysAdmins).
Nous retrouvons donc les schémas 3-Tiers classiques, utilisateurs lecture seul, utilisateur avec pouvoir et les utilisateurs administrators.

Sur notre serveur VEEAMOne, nous retrouverons ainsi les groupes locaux qu’il siéra à notre guise de peupler en respectant les bonnes pratiques et recommandation avec les ressources de notre domaine.

Pour enfoncer le clou, les rôles énumérés précédemment permettent les actions ci-dessous. A nous de mettre les bonnes ressources techniques en face du bon profil.
| Rôles | Permissions |
| VO Read-Only | Accès à la surveillance des données en lecture seule Accès à la génération de rapport |
| VO Powered | Accès à la surveillance des données Accès à la génération de rapport |
| VO Administrator | Accès à l’ensemble de la plateforme Accès à l’administration des données Accès à la génération de rapports Modification de la configuration VEEAMOne |
Licensing
Pratiques
Nous considérons que le serveur Windows a été durci au préalable et que nous possédons un serveur à jour.
Nous avons également téléchargé en amont les sources (iso) de Veeam One.
Nous ne traiterons ici que de l’installation d’un server VEEAMOne « AllinOne » (car j’ai un petit lab). Mais il est possible d’envisager un déploiement 3-Tiers (VEEAMOne Server, MSSQL Server et VEEAMOne UI). Je propose quelques choses de standard (car il faut sur un petit LAB se satisfaire du nécessaire et être heureux) sur la base de VEEAM BR, ESXi7 et VCSA.
Installation
Nous partons donc du principe que notre serveur Windows est déjà configuré et joint à un domaine (oui oui, j’ai bien écrit joint à un domaine). Que nous avons une appliance vCenter (joint ou non au domaine) ainsi qu’un serveur VEEAM BR (non joint au domaine et préalablement durci et conforme aux recommandations VEEAM.
Les prérequis en termes de ressources doivent être les suivantes (pour une Single Server):
- OS : WIN10, WIN11, WS 2012 à WS 2022
- CPU : 4 cores (minimum)
- RAM : 8 Go (Minimum) / 16 Go (Recommandé)
- Disk : 50 Go pour la SGBD MSSQL et VEEAMOne DB
- Network : 1 Gbps minimum
| /!\ Attention : Cela relève de mon settings. Les recommandations en termes de performances ne sont pas à être négligées. (Oui il ne va pas falloir être un rat. Je vous connais bande de SysAdmin pret à gagner 1 vCPU par ci, par là et autres petits Go de RAM.) Vous retrouverez les liens ci-dessous pour les recommandations : Supported Virtualization Platforms Supported VEEAM BR Supported System VEEAMOne Sizing |
Top à la vachette, démarrons l’installation !

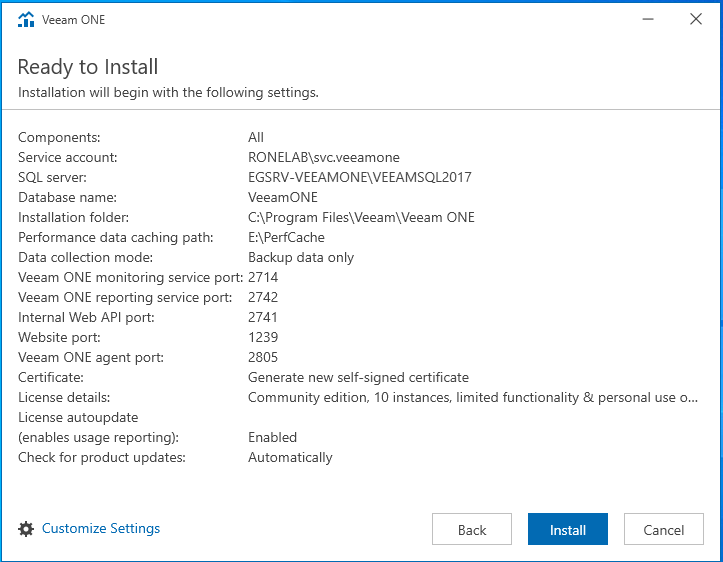
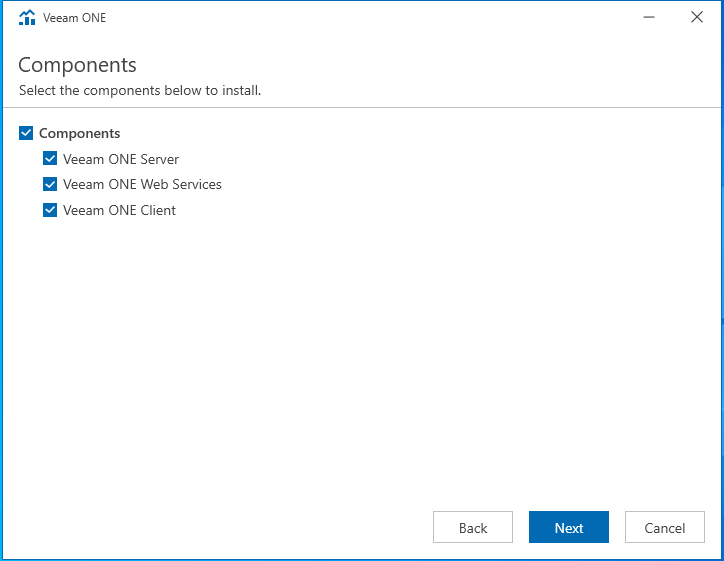
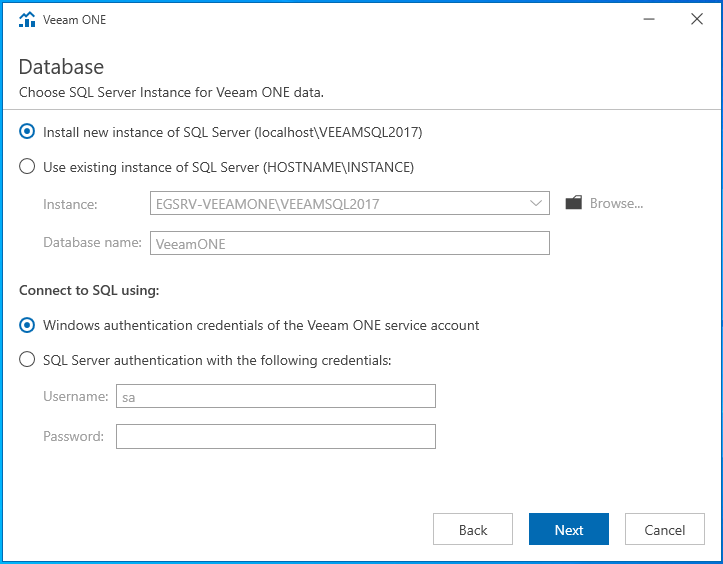
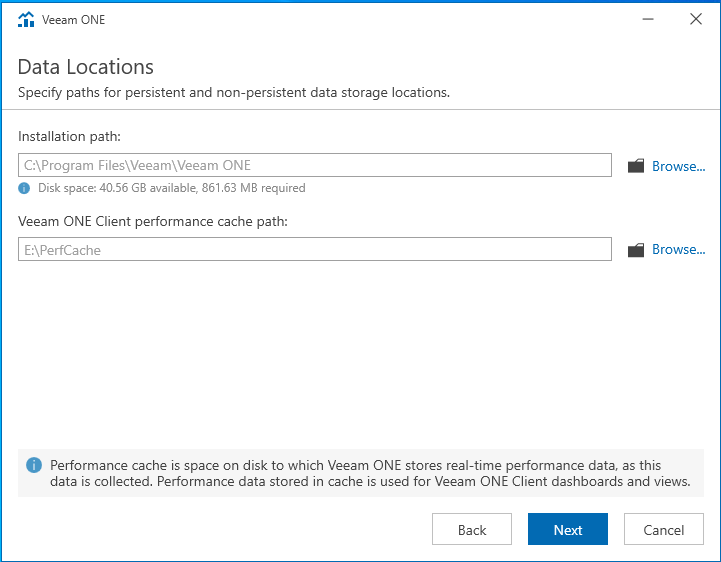
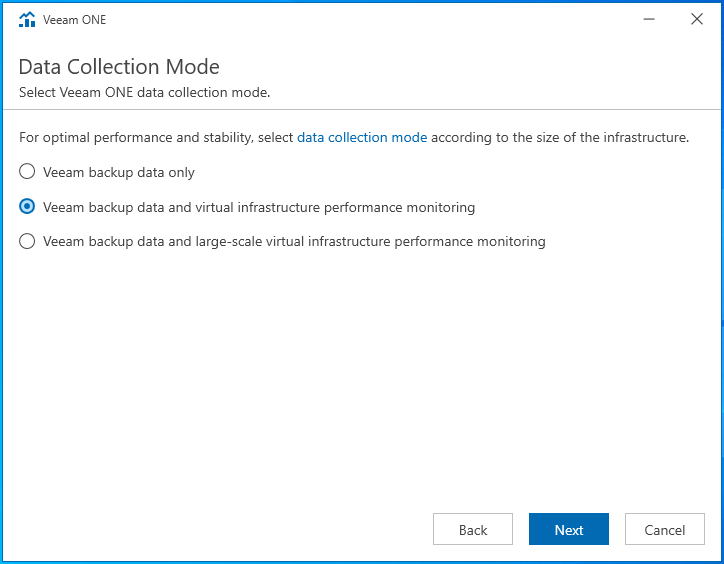
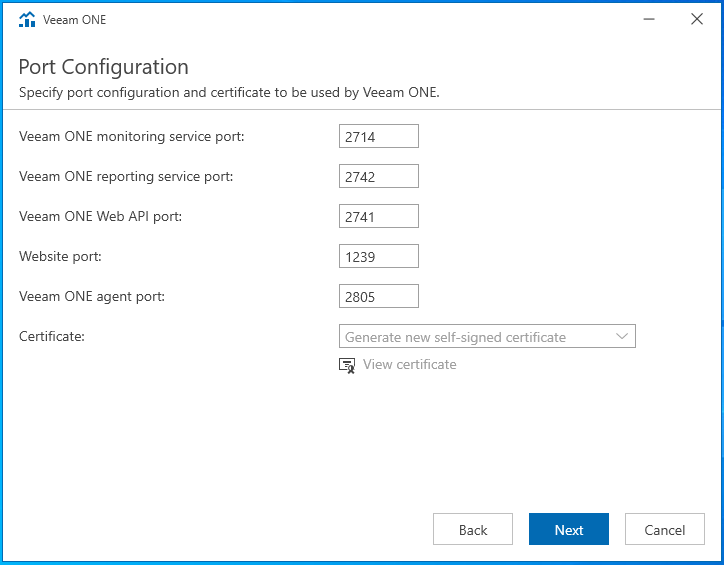
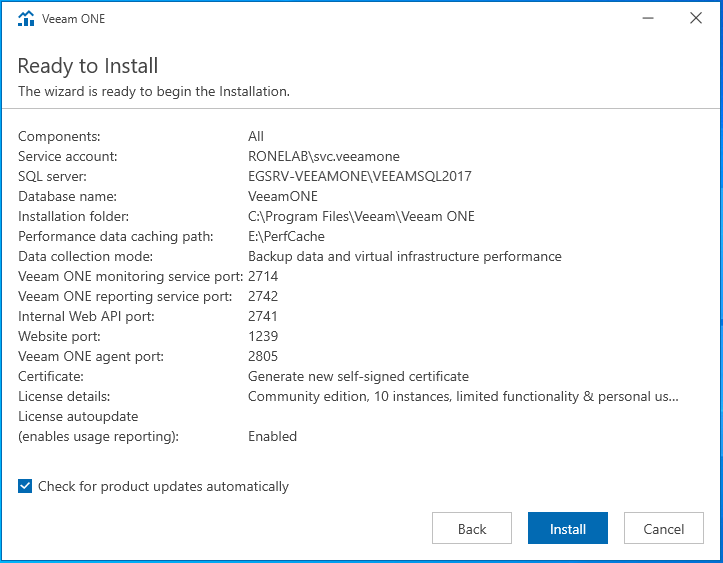
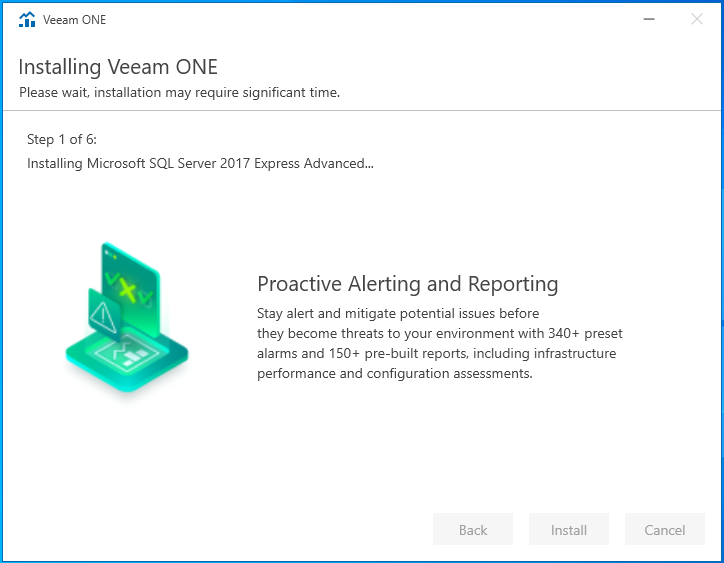

Configuration
Lors du premier lancement du client VEEAMOne, nous allons être invité à configurer l’application. Il faut comprendre par configuration le paramétrage général du serveur. Pour ce qui relève de la configuration des autres vues ou fonctionnalités, cela relèvera d’une partie dédiée dans cet article ou d’un article à part entière (je n’ai pas encore décidé).

De la sorte et je pense qu’il est utile de le souligner une nouvelle fois, un système de supervision et de monitoring sans être notifier reviens à commander un steack frites alors que l’on aime pas les frites et que l’on est végétarien. Hé ben c’est con ! Configurons alors les notifications.
Nous commençons à avoir l’habitude avec les solutions VEEAM de configurer les notifications. C’est exactement la même chose que pour VEEAM BR, à l’exception que l’IHM8 est d’une couleur différente.
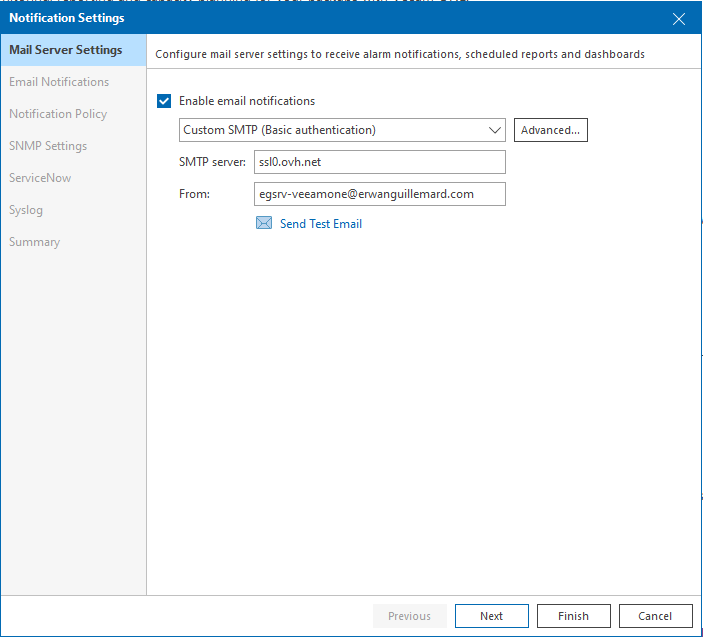
M’autorisez vous à passer cette partie ? Naturellement car je fais ce que je veux 🙂 Le seul point, bien penser à ouvrir les flux outbounds concernant le protocole utilisé. Sinon ba ça marche pas et ça ne court pas non plus… (Il est comique le garçon…)
Dans ce cas, nous pouvons ajouter plusieurs adresses mails en destinataire des notifications selon l’état des notifications (Toutes, les erreurs et avertissements, les resolved etc).
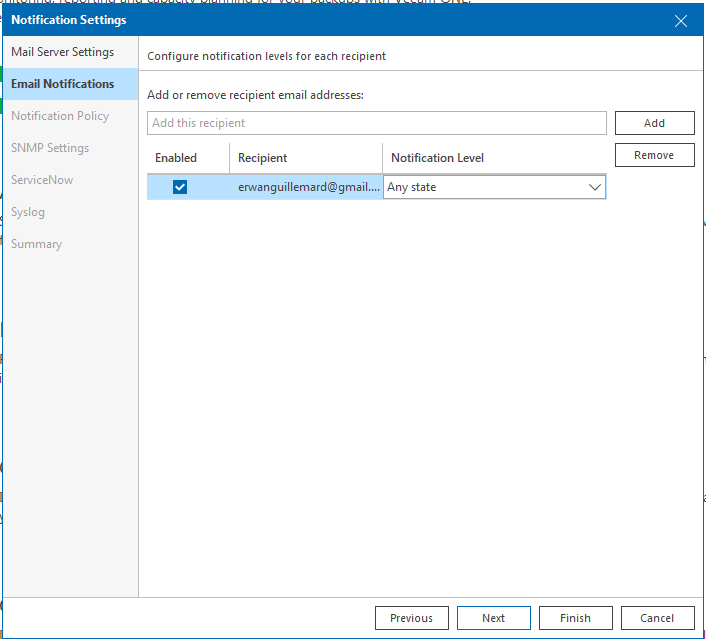
Toutefois, cela pose un problème car si nous souhaitons notifier qu’une équipe particulière sur certaines ressources, cela va être difficile de se coltiner toutes les notifications de l’infrastructure et donc d’être pollué…
Il faut voir ce paramétrage ci à destination de l’équipe Cloud, Services Hébergés et autres fiches de poste. Concernant les notifications plus ciblées à destination d’équipe spécialisée, je reviendrai dessus dans la partie Business View.
Pour cette étape, je suis un peu un SysAdmin sans personnalité car je vais laisser les paramétrages par défaut.
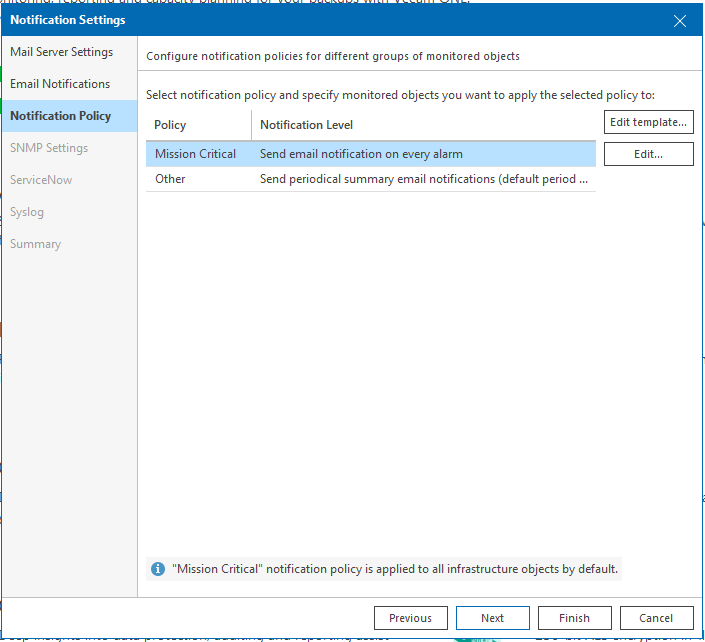
Il est possible de définir et de modifier un template. Dans mon cas d’usage, je trouve (et encore une fois il va nous dire que c’est son avis personnel…) que ça fait le taf.
Encore un classique de la supervision. Qui dit supervision dit log et donc SNMP9. Cela permet d’avoir une bonne visibilité de son réseau, des équipements et de l’état de santé de ces derniers.
Je ne l’utilise pas.
HAAAANNNN, NANI !!!!
J’ai une excuse. Dans un contexte professionnel, je préfère utiliser les solutions propriétaires. L’inconvénient, c’est que cela à un coup. Néanmoins, je pense qu’il serait temps de regarder d’un peu plus prêt cette fonctionnalité de collecte.
Et si nous cherchions un peu d’efficience pour notre infrastructure, les équipes opérationnelles ? L’un des rêves d’un SysAdmin (surtout le mien) reste d’intégrer les alertes dans la solution ITSM10 afin de pouvoir traiter de manière pro-active les alertes systèmes.
VEEAMOne propose de s’interconnecter à la solution ITSM ServiceNow. M***e pas de bol je n’utilise pas cette solution. Donc je passe mon tour…
« Tristesse, ton petit cœur doit saigner et tu dois roter du sang en boule sur ton paillasson ? »
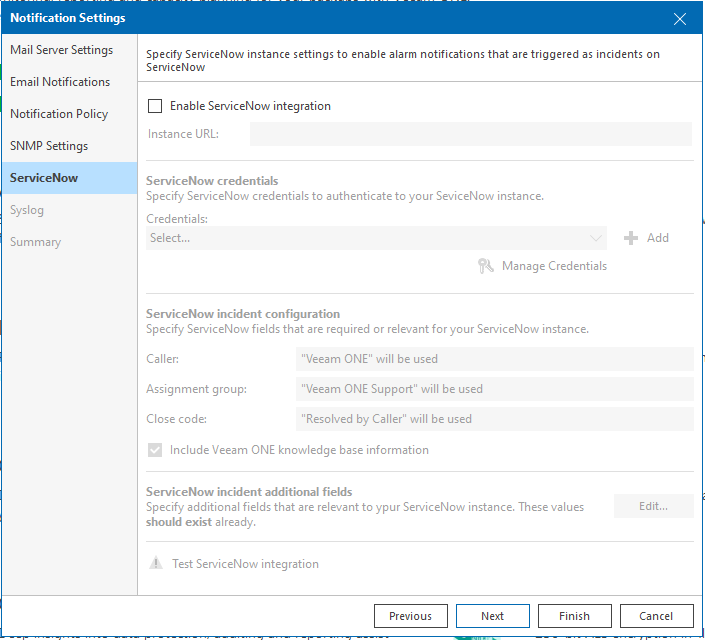
Hé non ! Si VEEAMOne ne propose pas de passerelle avec la solution ITSM que j’utilise (ITOP pour ne pas la nommer), les deux solutions possèdent une API11. Vous voyez où je veux en venir. 🙂
Je prépare cette introduction depuis longtemps et j’espère vous présenter mon connecteur dans le prochain article. Je ne suis pas vache, je vous lâche un petit teasing <3
Le puit de log… Fonctionnalité que je n’utilise pas non plus. Mais sur laquelle je devrais me pencher.
Garantir un historique des alarmes déclenchées et centraliser ces dernières seraient vraiment sympa. Toutefois, je rencontre une problématique. Je n’ai pas ce jour mis là main sur une solution libre qui soit facile d’administrer et de maintenir. Libre ne veut pas dire gratuit que nous nous entendons bien.
Par exemple, j’ai utilisé la solution GrayLog. Nous sommes vite limités par la licence communautaire sur le notre de flux journalier échangé. Il suffirait de prendre la CB est hop le tour est joué.
1-0 pour la solution
J’ai voulu mettre à jour la plateforme et j’ai tout cassé. Il suffirait de passer en SaaS chez l’éditeur comme ça plus de problème de MCO.
2-0 pour la solution
Pour le coup, je demande la VAR. Je ne suis pas fan de l’hébergement en SaaS dans ce cas précis. L’arbitre accorde donc 1-1, balle au centre…
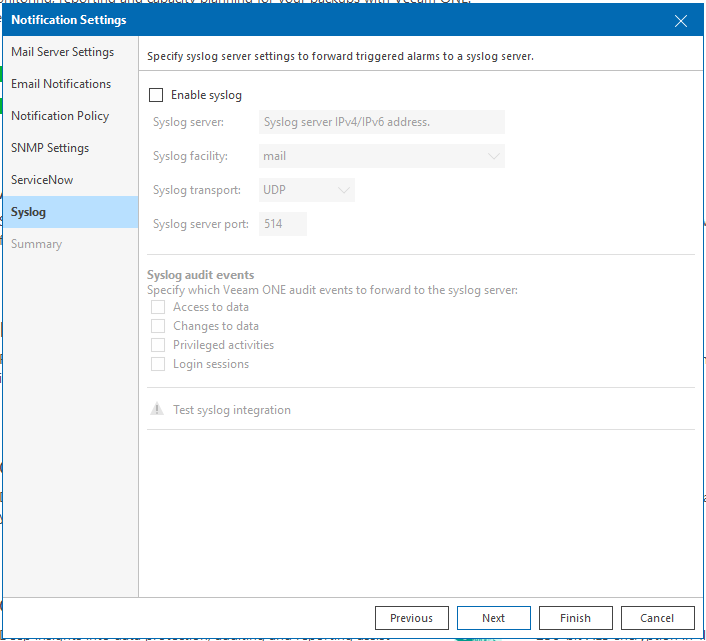
Conclusion, il faut que je torture encore quelques cellules grises dans mes travaux nocturnes pour étudier ce point.
Le petit récapitulatif, comme nous avons l’habitude de l’avoir chez VEEAM. Je trouve cela d’une simplicité et d’une efficacité remarquable. Chose que nous n’avons pas toujours sur d’autres solutions.
Tu vas vraiment nous faire croire que t’as pas d’action chez VEEAM ?
La configuration terminée, nous pouvons admirer notre console vierge et vide de toutes données. Il faut l’avouer, il y a là un côté tristoune. Je rassure, pas pour bien longtemps.
Virtual Infrastructure
La vue Virtual Infrastructure va nous permettre de suivre l’intégralité de l’état de santé ainsi que les évènements de notre SIs depuis le socle de virtualisation jusqu’aux SEs des machines virtuelles.
Comme souligné précédemment, l’objectif est d’être proactif face à un dysfonctionnement d’infrastructure ou d’anomalie sur un serveur virtuelle en production.
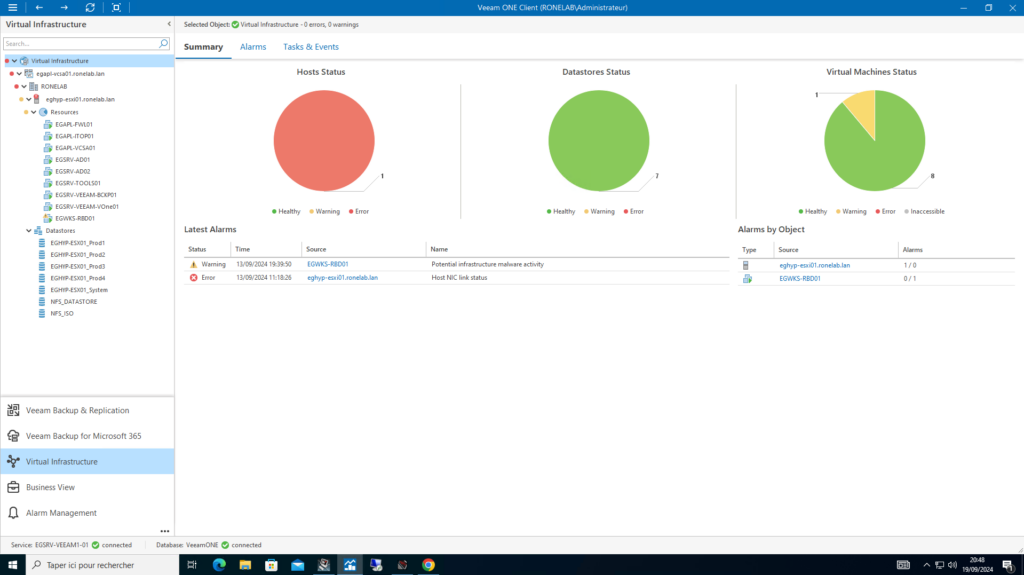
VEEAMOne prend en charge les produits suivants, VMWare, VMWare Cloud Director, Microsoft Hyper-V.
Un exemple ci-dessous d’ajout d’une appliance VCSA.
VMWare
Sous Virtual Infrastructure, faire un clic droit et ajouter un nouveau serveur.
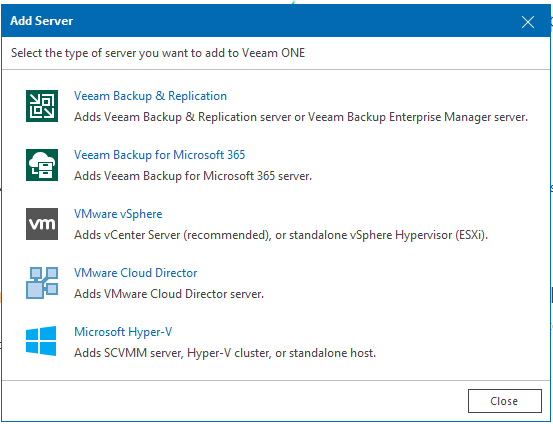
VEEAMOne nous demande si nous souhaitons ajouter une appliance ou un hote directement. Renseignons le nom DNS de notre appliance.
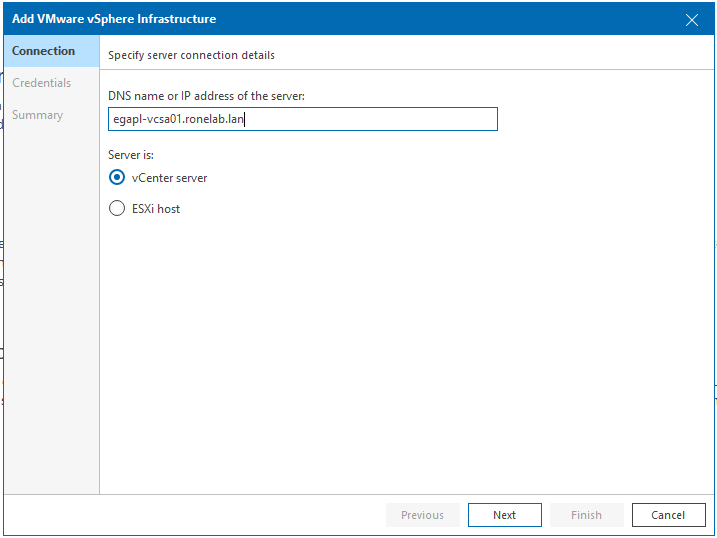
J’ai fait le choix (pour l’instant) de ne pas binder mon appliance VCSA à mon AD. C’est pourquoi j’ai créé un compte local svc.veeamon@vsphere.local sur mon appliance avec les permissions nécessaires.
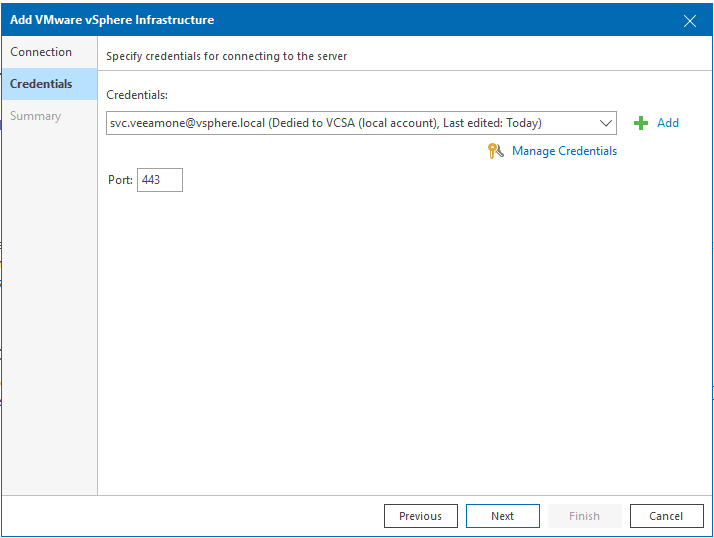
Naturellement, il ne faut pas oublier d’ouvrir les ports interlan dans le cas de segmentation des réseaux.
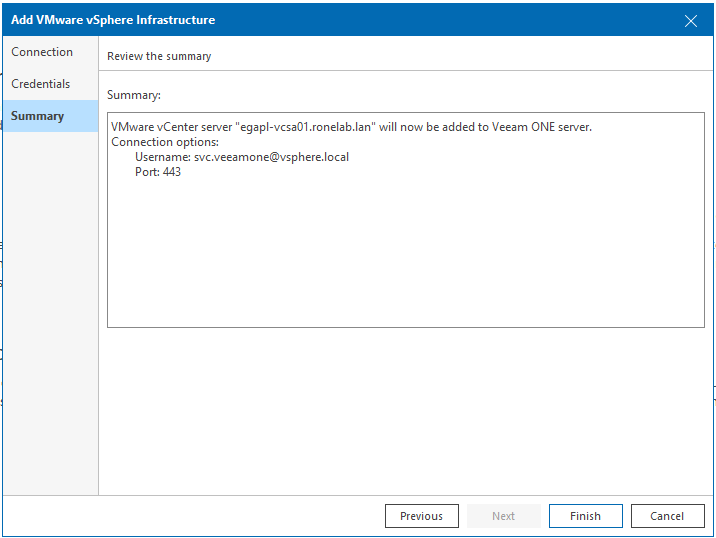
Le traditionnel rappel et voilà notre appliance VEEAMOne connecté à notre VSCA.
Veeam Backup & Replication
La vue Veeam Backup & Replication comme son nom l’indique va traiter de la sauvegarde et de l’ensemble des jobs de protection. Si la vue d’infrastructure vient à donner une bonne visibilité de notre infrastructure virtuelle, nous aurons avec cette vue ci une visibilité sur l’ensemble de notre infrastructure VEEAM.
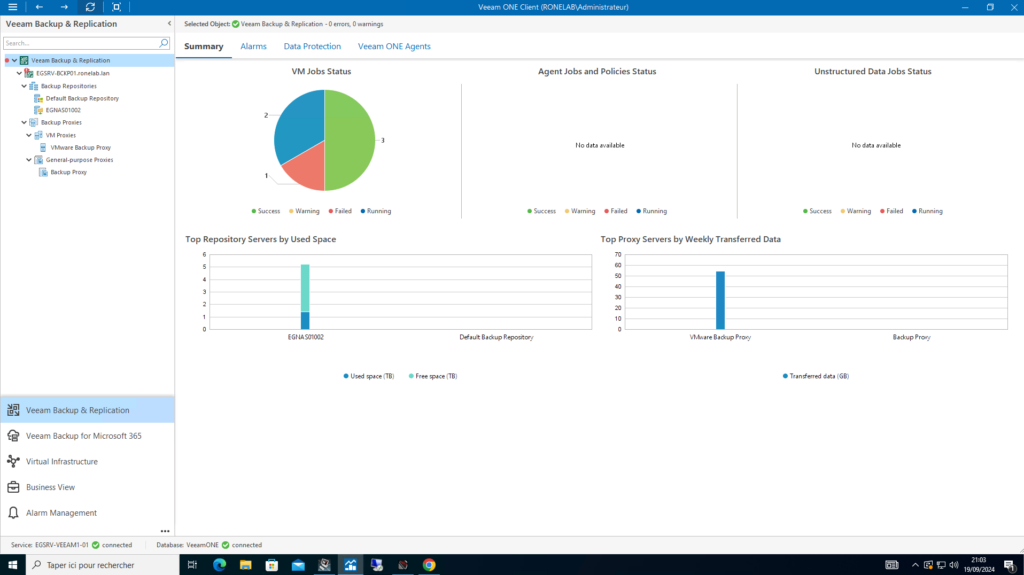
Depuis l’état du serveur de sauvegarde, des jobs en passant par la charge des proxies VEEAM ainsi que l’utilisation des repos de sauvegarde ainsi que le détail des chaines (full et incréments).
Lors de la présentation de la solution dans la partie « Théorique » le déploiement d’un agent de supervision permettra de réaliser en plus de la remontée d’informations la possibilité de réaliser des actions de remédiations.
M’sieur, un petit clic droit sur Add Server 🙂
Nous renseignons comme précédemment pour l’ajout d’une ressource d’infrastructure le nom DNS de notre serveur VBR. Il est également possible d’intégrer un serveur VB Entreprise Manager.
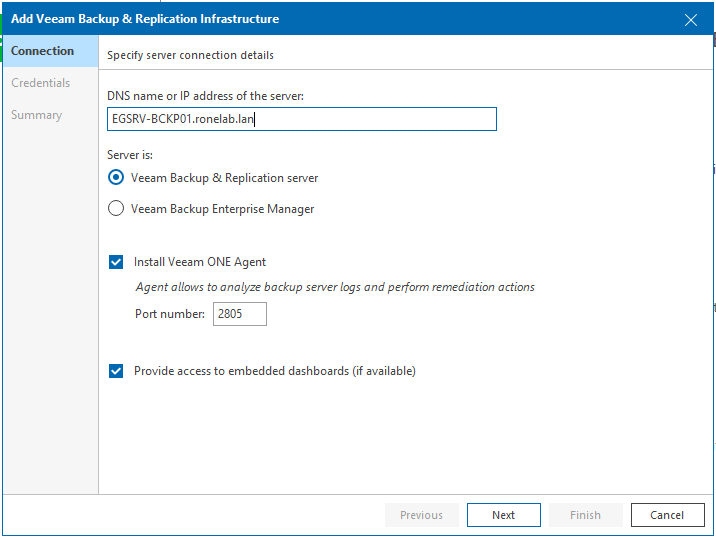
Je n’utilise pas ce dernier et pourtant c’est le manque de temps en ce moment qui vient ralentir ma boulimie intellectuelle et m’empêche d’avancer.
Je coche volontairement l’installation de l’agent VEEAMOne pour avoir les actions de remédiation et d’avoir le relevé de journaux d’événements ainsi que son analyse.
La seconde coche permet de joindre notre serveur VBR à notre serveur VEEAMOne et donc avoir directement dans la console VBR les informations et performance de notre infrastructure de sauvegarde. (Franchement, il ne faut pas hésiter C’est du read only pas de risque 🙂 )
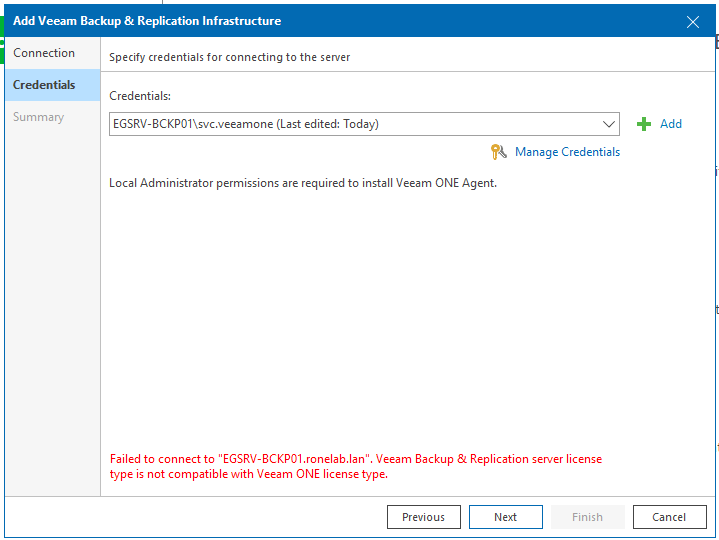
Renseignons le compte local de notre serveur VBR qui va permettre le relevé d’installation. J’ai déjà expliqué les actions préconisées pour garantir un niveau de sécurité acceptable.
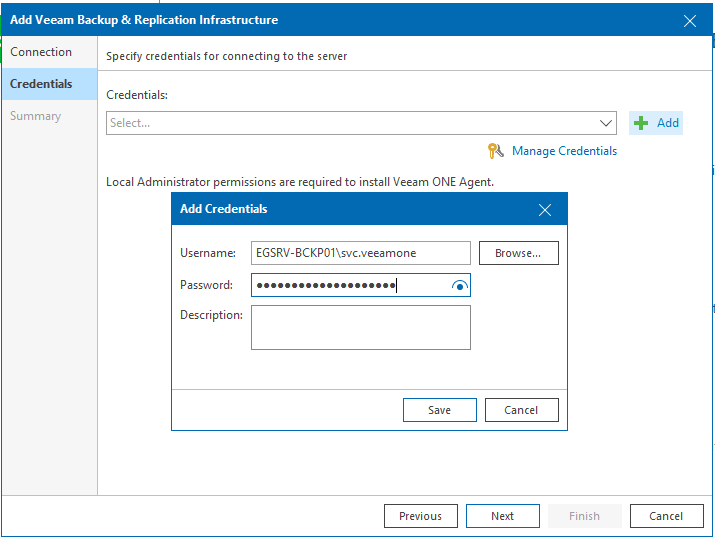
Toutefois, rappelons-nous qu’il est nécessaire d’avoir les droits d’administrations pour que VEEAMOne puisse installer l’agent VEEAMOne. Sans quoi vous aurez le joli message ci-dessous <3
Le récap, le récap, le récap !
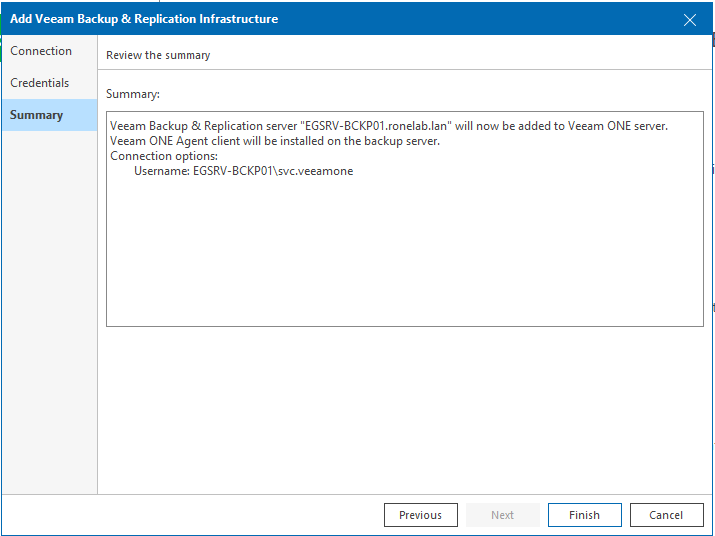
Une fois ajoutée, nous obtenons une interface vide. Pas de panique, c’est normal. Ce n’est pas un bug.
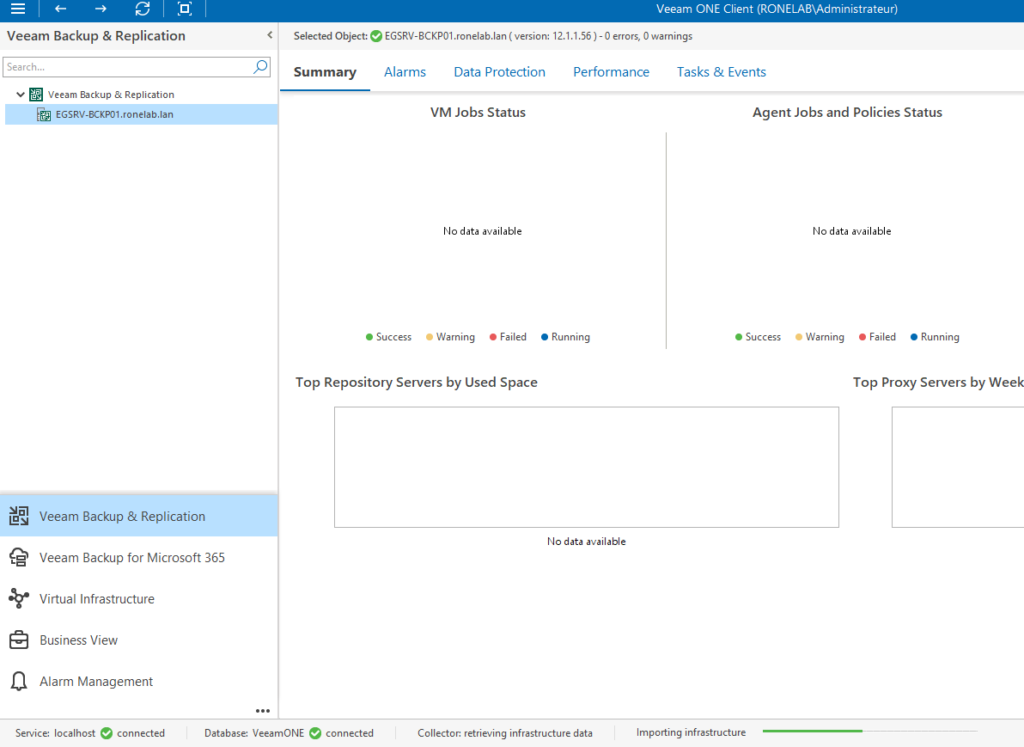
En regardant l’image précédente, nous remarquons en bas à droite que l’infrastructure est en cours d’import. Ah ouf ! Il en sera de même avec l’installation de l’agent et la remontée de log. Il faut faire preuve de patience et non pas cliquer 50 fois sur le bouton d’impression au risque de griller notre imprimante. Les données remonteront d’elles-mêmes comme présenté dans le début de cette partie.
Dans la même logique, si nous avons coché l’accès aux tableaux de bords dans la console VBR, il sera nécessaire d’attendre l’intégration des datas.
Dans notre console VBR, dans l’onglet Analytics nous retrouverons les informations sur la planification, durée des jobs. La sollicitation de telle ou telles ressources, l’espace de stockage de nos repos ainsi qu’une vue globale MENSUELLE de nos jobs de sauvegarde (et dire qu’avant cette fonctionnalité je me suis fait iéch à faire des extracts et tableau xlsx…. Je les utilise toujours pour mes indicateurs hein 😉 ).
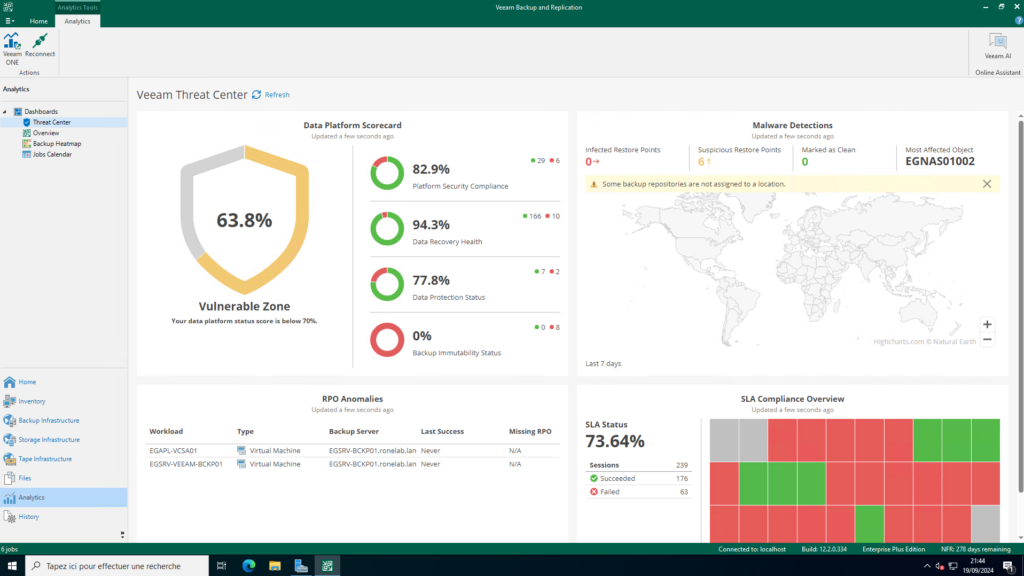
Sinon, il est tout à fait possible d’avoir les mêmes informations dans la WebConsole VEEAMOne. Si vous savez, le truc qui commence par https et se termine par 1239 du type https://monseveur_VEEAMOne.contoso.com:1239.
Business View
Cette partie est intéressante pour celui qui sait la manier. Personnellement j’ai mis un certain temps à comprendre son mécanisme et l’intérêt que cet onglet peut apporter.
Dans cette « Vue Affaire », il va nous être possible de faire presque quasiment tout ce que nous souhaitons en termes de filtre et d’identification sur les ressources VMs, Hosts, Datastores et Clusters.
Cette vue va donc nous permettre de répondre à des problématiques financières et techniques.
- Financière : Afin d’avoir un rapport précis des ressources consommées par un service (SaaS) ou d’infrastructure (IaaS). D’assurer l’efficacité et l’efficience de notre infrastructure afin de définir si nous sommes en over-capaciting ou under-capaciting. Investir, pas investir ? Prospecter, pas prospecter ? (Mon PDG répondrait sans hésiter OUI ! et il a bien raison)
- Technique : Pour garantir un état de santé par service, la présence de snasphot, la possibilité de notifier que certaines ressources aux bonnes équipes… J’en passe car la liste pourrait être longue.
Sincèrement, je vois la partie Business View comme le pivot et point le plus important pour maitriser son budget ainsi que son SI.
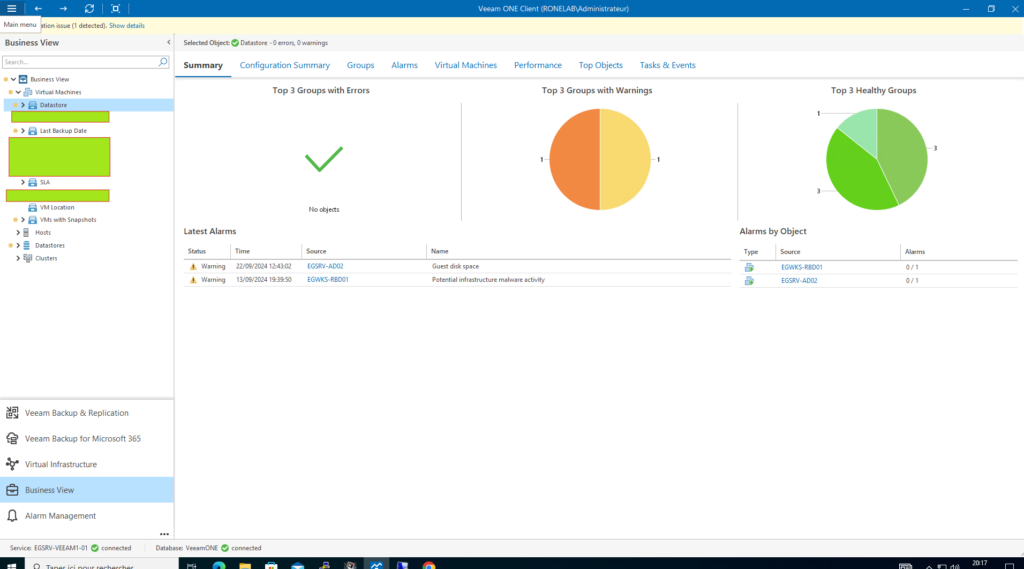
Bon hormis le fait que je laisse l’impression que mon exploitation n’est pas faite à la maison. Objection lecteur ! Mon MCO est fait. Il se trouve que l’erreur disque sur mon second AD est lié à la sauvegarde Windows et que je n’ai pas acquittée cette dernière (Oui j’ai bien écrit Acquitté et non Résoudre).
Mais bon entre nous, un système de monitoring sans erreurs et avertissements ça serait d’un ennui non ?
| Par défaut nous avons la vue ci-contre. Il sera alors possible pour nous de définir des nouvelles catégories pour chacune des familles présentée plus tôt. Nous allons réaliser les catégorisations selon 3 critères. *** Single Parameter *** Muliple Conditions *** Grouping expression  |  |
Je pense que pour bien comprendre la puissance de ces trois méthodes de catégorisation, il faut que nous nous attardions dessus.
Comme présenter rapidement plus haut, nous allons catégoriser une ressource sur un groupe d’objet qui se base sur une propriété du type concerné (VMs, Hosts, Datastores ou Clusters).
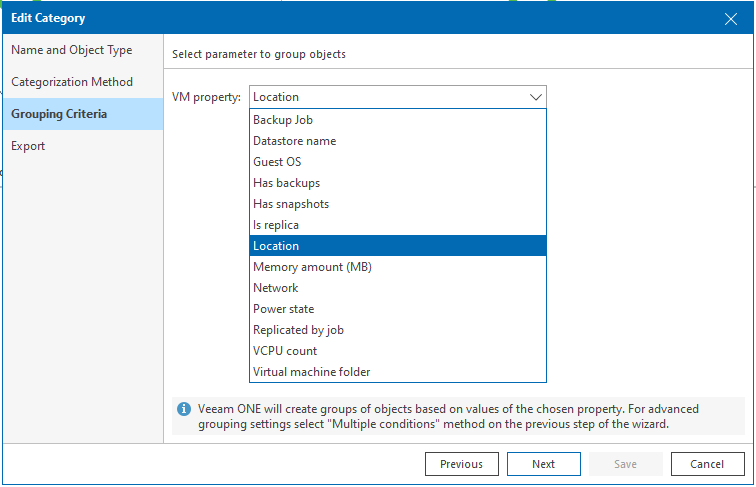
L’étape qui suit vous demandera si vous souhaitez créer un tag sur l’environnement vSphere ou non. Personnellement je n’utilise pas les tags sur ce genre de catégorisation.
Je reviendrai plus bas sur la notion de tag au sens VMWare du terme car il y a des subtilités à assimiler.
Le cas d’usage pour cette catégorisation (à mon sens) et de filtrer, identifier rapidement des ressources sur des actions, états simples. Je dirais donc parfait pour l’administration et le MCO.
La catégorisation mutli-paramètres va nous offrir plus de possibilité quant à la possibilité de trier et de sélectionner les ressources que nous souhaitons obtenir.
Comme nous pouvons le constater ci-dessous, la liste des critères de ciblage est plutôt conséquente. Passant des paramètres systèmes aux éléments d’infrastructures en réalisant une halte par la sauvegarde. Nous retrouvons également les classiques opérateurs de comparaisons (Equals, Not Equals, Contains, Starts/Ends with…) par rapports à une valeurs.
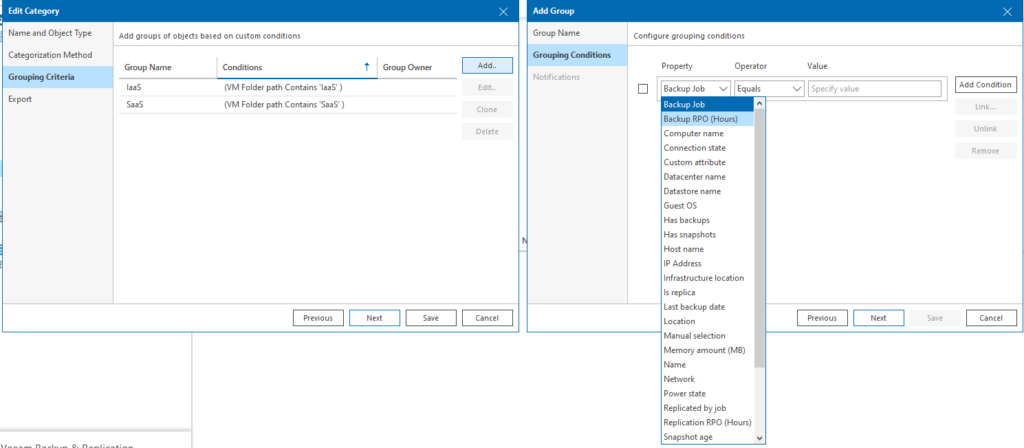
Comme vu ci-dessus, j’ai choisi ici d’identifier l’ensemble des VMs contenu dans les VM Folder qui contiennent les noms IaaS et SaaS. Il faudra comprendre VM Folder au sens VMWare du terme lors de la création d’un dossier dans la vue VMs & Templates de notre VCSA naturellement.
Contrairement au cas de catégorisation précédent, je vais choisir de créer les tags vSphere. Ainsi, les ressources (VMs) qui se trouvent sous le répertoire parents IaaS se verront identifiés comme un type IaaS. Il en sera de même pour le type SaaS.
C’est là que le sujet commence à devenir intéressant. Car comme évoqué plus tôt, nous commençons à travailler la donnée de notre infrastructure en donnée financière.
Quels est la part de notre infrastructure consommée et allouée à nos services BaaS, SaaS, IaaS, ect… Quels est la part de notre SI allouée à son fonctionnement et la production ?
Je vois dans déjà dans le fond de la salle les yeux pétillants des DAFs, DCs et autres dirigeant d’entreprises. Oui, nous SysAdmins nous savons vous faire faire des économies et apporter un vrai valeur ajoutée <3. (Je développerai ce point dans la conclusion).
Je crois que c’est la méthode de catégorisation que je préfère car elle permet de faire presque tout ce que l’on souhaite. Cette vue est orientée « développeur » (le style old school VisualBasic).
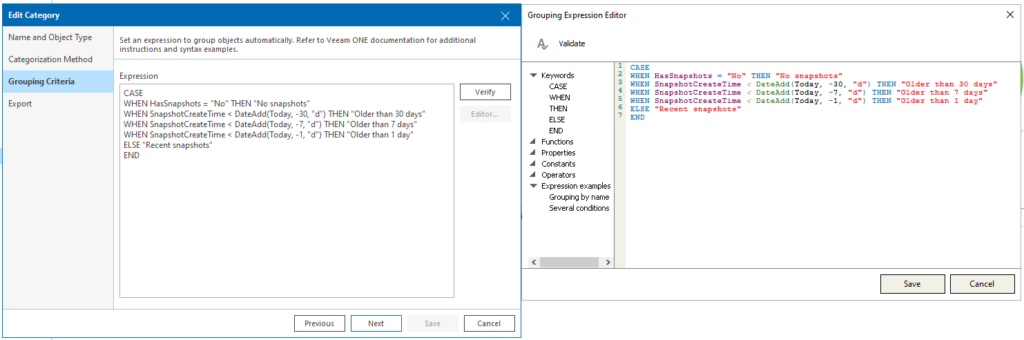
Ci-dessous, un exemple avec la catégorie VMs with Snapshots qui va selon la date des snapshots nous offrir une vue et métriques sur les snasphots présent si c’est la durée de vie de ces derniers est inférieurs à 1 jour, 7 jours, 30 jours. Dans cet usage, cela permet au SysAdmin d’avoir une granularité sur une tâche bien distincte et dans certaines situations maintenir le curseur sur ce qui est acceptable ou non.
Au-delà de cette possibilité, il est également possible de gérer (créer, pas supprimer hein) les tags vSphere de manière dynamique selon l’évolution de l’infrastructure de notre arborescence VMs & Templates. Ainsi, admettons que nous créons une nouvelle bulle SaaS ou IaaS sous cette même infrastructure, l’ensemble des ressources qui se trouvent sous ce dernier sera identifié comme IaaS ou SaaS et du nom du répertoire. Pratique donc par la suite de sortir des indicateurs de ressources et de faire une facturation à la carte (refacturation interne ou facturation à un client final).
Pour bien comprendre l’intérêt des tags vSphere générés par VEEAMOne, pourquoi ne pas se lancer un petit RVTools des familles ? 🙂
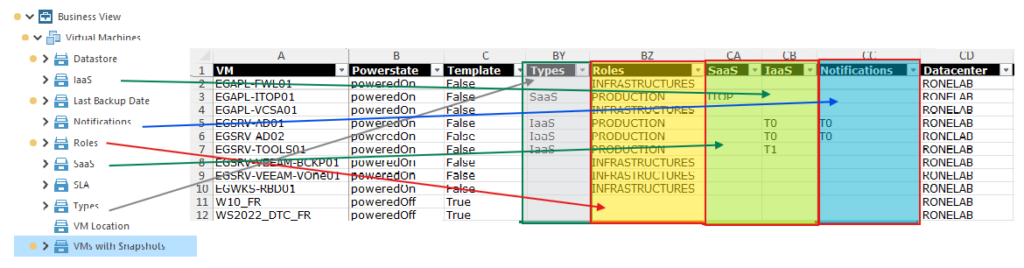
C’est un coup des Indiens Lucky Luke, il y a des flèches partout !

Au delà de mon humour douteux (ainsi que mon admiration pour Terence Hill quand j’étais jeune garçon), nous avons là un outil puissant. La création des tags par catégorisation au délà du client et de la solution VEEAMOne est exploitable dans VMWare. Donc, il va nous être possible avec de l’huile de coude et un peu de rigueur d’établir des métriques et rapports sur l’évolution d’une bulle, d’un service. Et pourquoi pas établir un outil de capacity planning ? Tout devient possible.
J’avais pour projet de créer une petite application sur un moteur SQLite ou MariaDB un outil de suivi des ressources sur 13 mois glissants. Malheureusement, pour moi il faut faire du web…
Oui, on sait, c’est une étape traumatisante de ta vie. Tu ne voudrais pas débuter une thérapie et arrêter de nous briser les noix avec ça ?
Oui, promis je vais y penser. Mais au délà du traumatisme, il faut du temps et difficile de me cloner (et je ne suis pas certain que cela soit une bonne chose). Toutefois et dans le cadre professionnel, j’ai développé un fichier excel qui fait le taf mais comme tous fichiers excel, ce dernier ne connait que son maitre. C’est pour ça qu’une petite application web serait sympa. Et je crois qu’il est important de souligner que les fichiers excel pour faire tout et rien. C’est has been maintenant car il faut faire du PowerBI… Je pense que je ferai un article là-dessus quand j’aurai redéveloppé une solution plus simple (en gros sans code en VB et des formules de 5 km de long).
J’ai déjà bien abordé le sujet des tags. Il y a néanmoins une chose importante à savoir sur l’utilisation de ces derniers. L’application des tags vSphere (création) peut prendre un temps certain c’est pourquoi il faut être patient (selon la documentation cela peut prendre jusqu’à 3 heures et plus selon la taille de l’infrastructure). De plus il sera nécessaire de se rendre dans la console WEB pour réaliser une collection des données.
Par défaut cette dernière est définit quotidiennement à 03:00 AM.
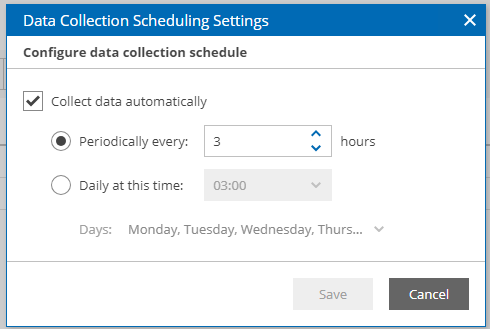
J’ai personnellement modifié cette dernière pour qu’elle se lance toutes les 3heures. Attention à vos performances. Il est également possible de lancer une collecte de données manuellement.
VEEAM Report
La partie Report se passe sur le client Web (https://monVEEAMOne.contoso.lan:1239). Une fois connecté, c’est dans la partie Dashboard et Reports que nous allons avoir les outils les plus pertinents.
Dashboard
Dans le tableau principal, nous allons retrouver les catégories par défaut. Il sera toutefois possible d’ajouter des « tuiles » avec des vues personnalisées. Je trouve que les tuiles présentes suffisent largement à mon activité. Je pense qu’il est important de présenter chacune d’entre elles. Pourquoi ? Parce qu’il est facile de ne pas comprendre les informations présentées et de passer à côté de métriques et d’éléments qui faciliterons la prise de décision technique et financière. 🙂
Sans grande surprise, nous retrouvons ce que nous avions déjà vu précédemment dans VEEAM BR dans la rubrique Analytics. Normal puisque VEEAMBR vient chercher les métriques dans VEEAMOne qui vient lui aussi les chercher dans VEEAMBR.
La boucle est bouclée.
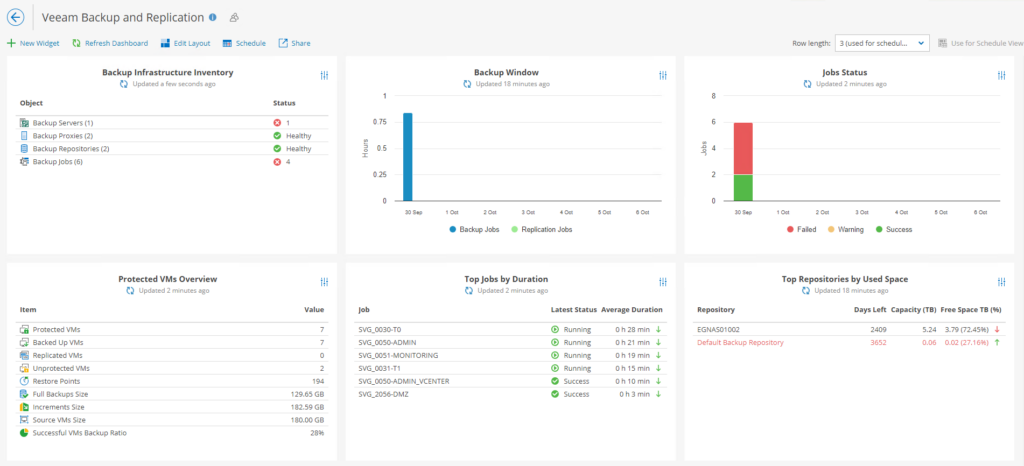
Blague à part et j’adore le phénomène démo. J’ai la majorité de mes jobs qui ne passent pas. Cela se retranscrit dans mes charts. A moi de résoudre le problème.
Merci qui ? Merci Jacquie et … Non un peu de sérieux ! Merci VEEAM One <3
Comme pour la partie précédente, nous retrouvons également cette partie dans la console VEEAM BR.
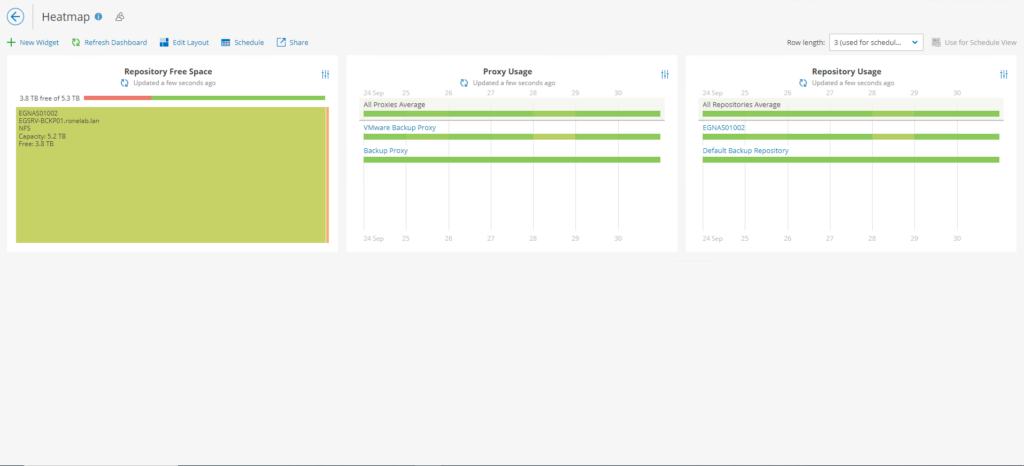
Si la première partie de l’accordéon concernait les jobs et l’état des jobs, là nous sommes plus sur les performances et usages des différentes ressources de l’infrastructures VEEAM. La notion de dégradée sera utilisée de vert à rouge selon l’usage et la sollicitation des différents composant VEEAM.
J’avoue que cette vue n’est pas bien parlante dans mon cas car je ne possède pas de Cluster VMware.
Toutefois, cette vue va permettre d’afficher les tendances de notre cluster concernant l’utilisation des différentes ressources. Parfait pour identifier les pics et évolution du SI sur une période.
L’une de mes vues favorites. Pourquoi ? Car elle indique et offre une visibilité totale de l’état de vie de notre SI. L’évolution du nombre d’avertissements ou d’erreurs critiques.
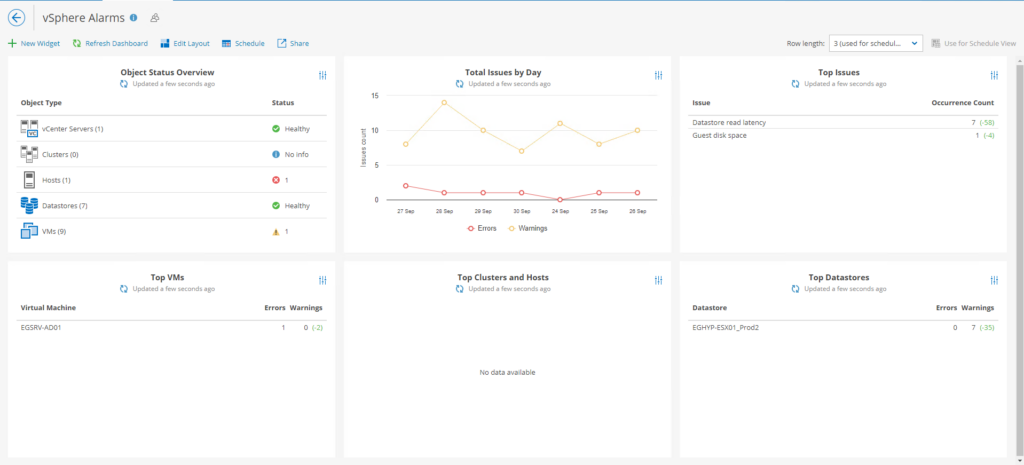
Au déla des métriques quantitatives, ces métriques sont identifiées par catégories. Ce qui facilite grandement et facilement les actions prédictives vis à vis d’une panne d’infrastructure logique ou physique.
Nous retrouvons comme dans la tuile numéro 3 – vSphere Trends le même constat aussi triste soit-il dans mon cas. Pas de cluster, pas de métrique…
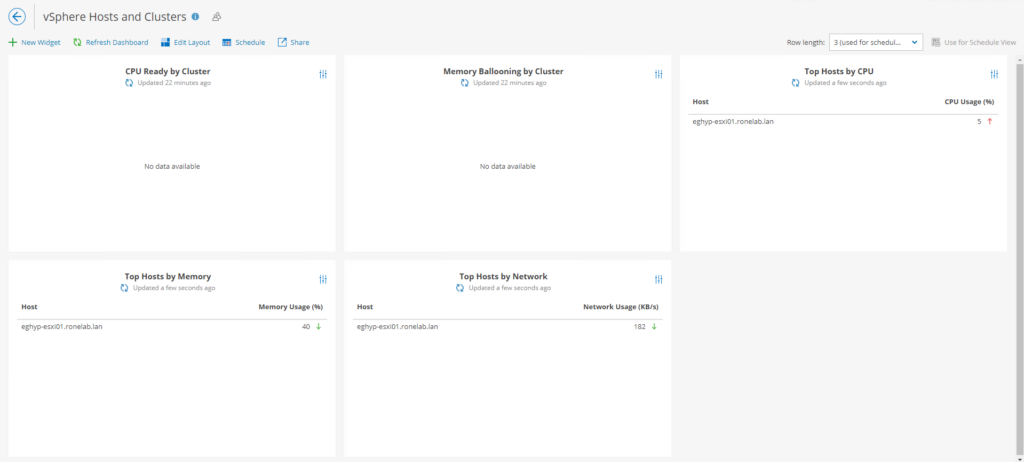
Ce qui n’est que partiellement vrai. Puisque nous constatons dans cette vue la tendance de consommation à la hausse ou à la baisse des ressources d’un hôte VMWare ou d’un cluster. Cela peut donc se traduire par, à la hausse ou en sous-évaluation de l’infrastructure et un besoin de renforcer cette dernière. A la baisse, une infrastructure surévaluation de l’infrastructure vis à vis de son usage quotidien.
Dans la logique, je dirai que nous devons tendre vers une constante en acceptant un léger taux de variation et non à une fonction croissante, décroissante.
Un incontournable ! Pour les nostalgiques des ayatollahs de l’exploitation à travers les RVTools. Nous retrouvons l’évolution des datastores à la hausse comme à la baisse sur l’espace disponible. La visibilité des vmdks quant à l’espace consommé et l’espace disponible. La latence des différents datastores (impeccable pour la prédiction d’un disque qui va lâcher), les IOPS pour chaque datastore.
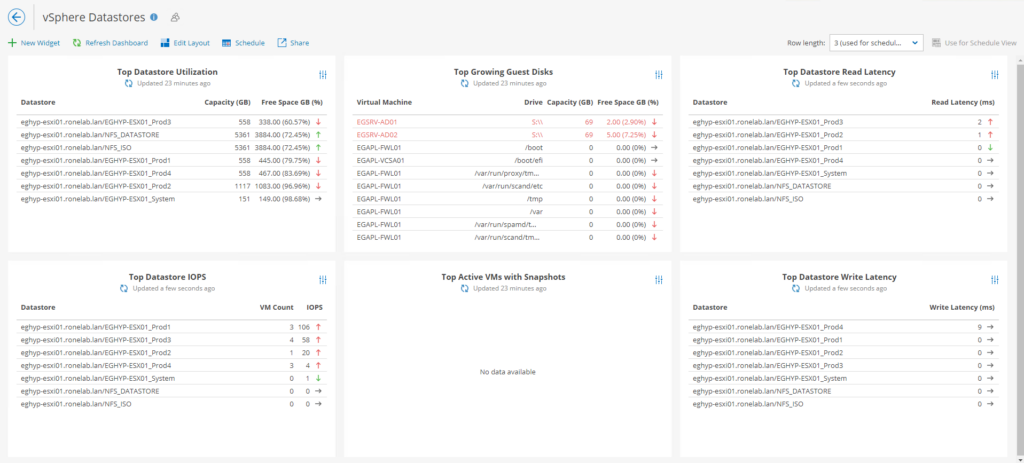
Que dire de plus. C’est merveilleux, c’est extra !
J’ai l’impression de me répéter… Après les datastores et la partie hosts & clusters, maintenant c’est au tour des virtuals machines.
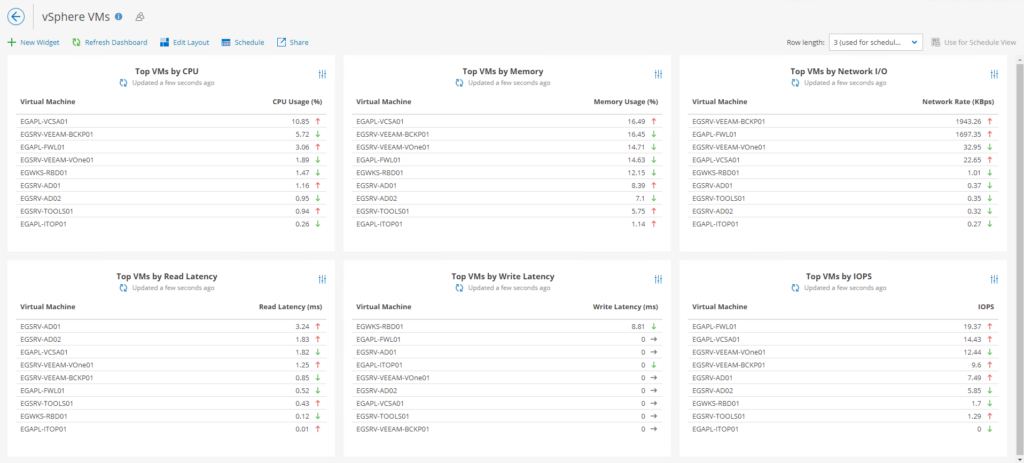
Cette fenêtre permet d’identifier assez rapidement si une VMs nécessite l’ajout de ressources supplémentaires ou une surallocation. Elle permet également dans un certain contexte d’orienter un potentiel dysfonctionnement de type hardware, ou software (mauvaise configuration d’une application métier par exemple comme ça au hasard).
De nouveau un petit coup de pouce sur les ressources disponibles et sur les ressources consommées.
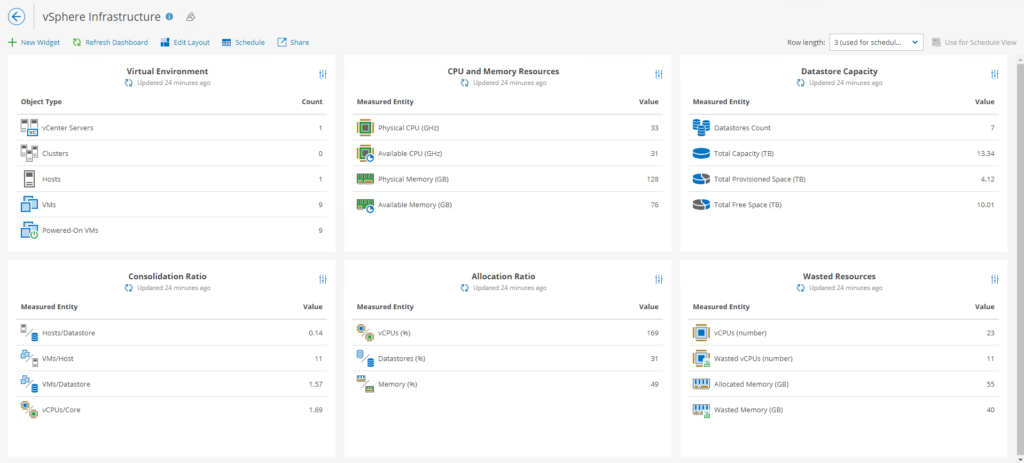
Parfait pour éviter l’overprovisionning, le balloning 🙂
La vue crainte par les SysAdmins, DSI et DAF.
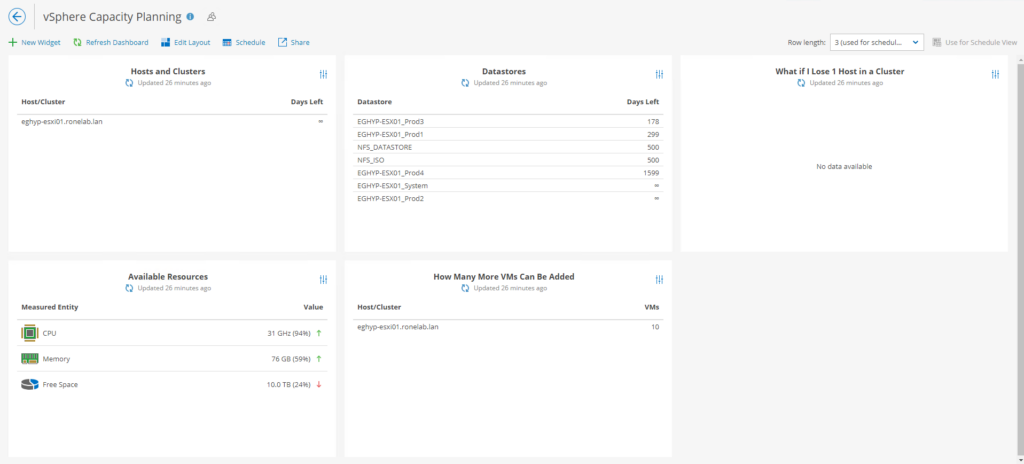
Cela correspond à partir des tendances d’usage en une projection de la durée de vie de l’infrastructure et donc de son renouvellement ou de sa consolidation en ajoutant des ressources supplémentaires.
En gros :
Exprimer le besoin, Présenter le devis, Faire valider l’investissement, Obtenir le chèque signé, Mettre en production les ressources. Simple non ? :p
Pour le reste, il suffit d’un peu d’imagination et d’établir les métriques que l’on souhaite obtenir et pourquoi pas générer les rapports et se les faire envoyer dans notre boite mail ?
Le conseil que je donnerai, c’est de se perdre dans le choix des possibles qu’offre VEEAMOne et de garder en tête « Est ce que cela m’apporte une valeur ajoutée business et technique ?« . Si c’est le cas alors vous êtes, nous sommes sur la bonne voie 🙂
Report
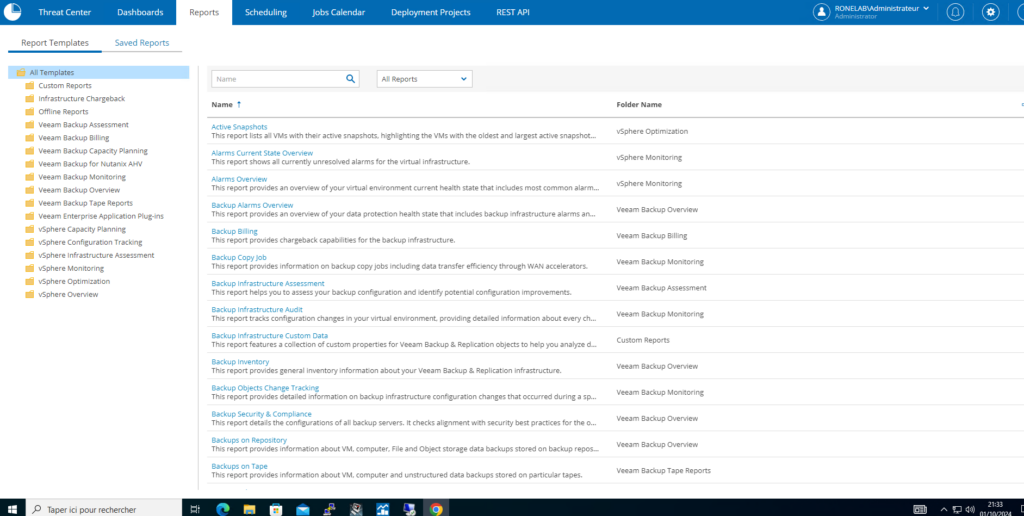
La fonctionnalité du Report et de générer des rapports. Merci Capt’aine Obvious…
Oooooh ba si on ne peut plus rigoler… Pour faire simple nous allons être dans la capacité de générer des rapports précis sur des thématiques précises :
- Charge de l’infrastructure
- Facturation VEEAM Backup
- Supervision VEEAM Backup
- Optimisation vSphere
- Capacity Planning
- …
Il suffit de regarde l’interface.
Prenons deux exemples. L’un orienté pour le business et l’autre pour la technique.
Admettons que nous souhaitons vérifier ce que nous devrions facturer à un client des bulles T0 et T1 mensuellement. Et que le cout de la sauvegarde est de 24,79€ du TB.
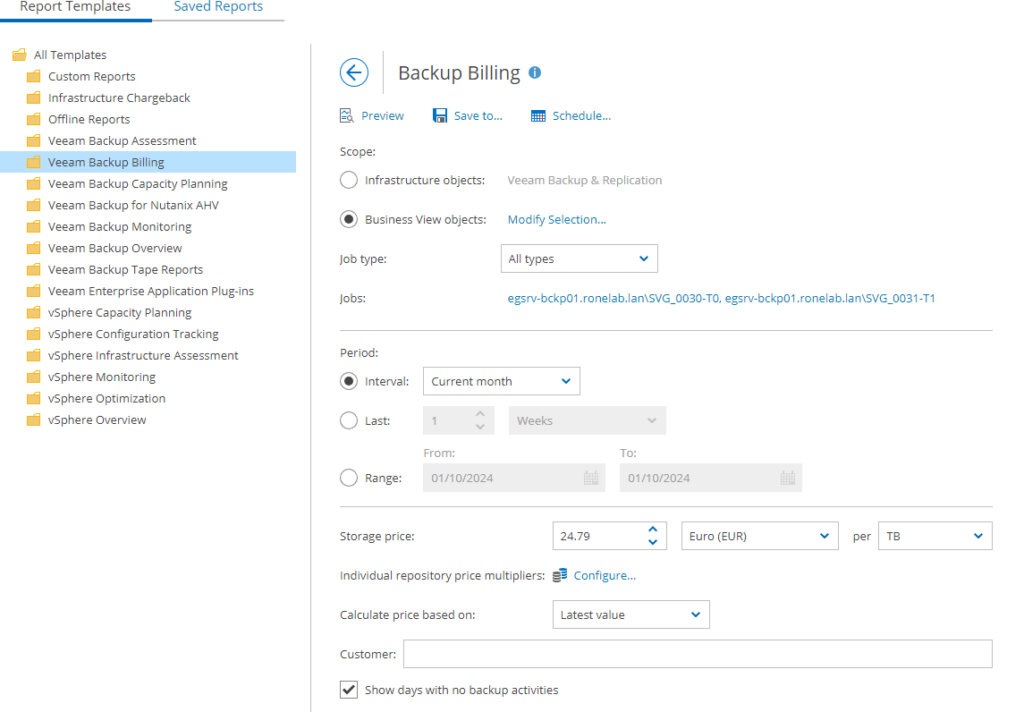
Nous configurons les paramètres en sélectionnant nos différents tags T0 et T1 ainsi que les jobs concernés. Nous précisons la période sur le mois en cours. Puis nous cliquons sur Preview en haut à gauche.
Et tadam ! Voilà notre rapport (sur deux pages).
| Page 1 | Page 2 |
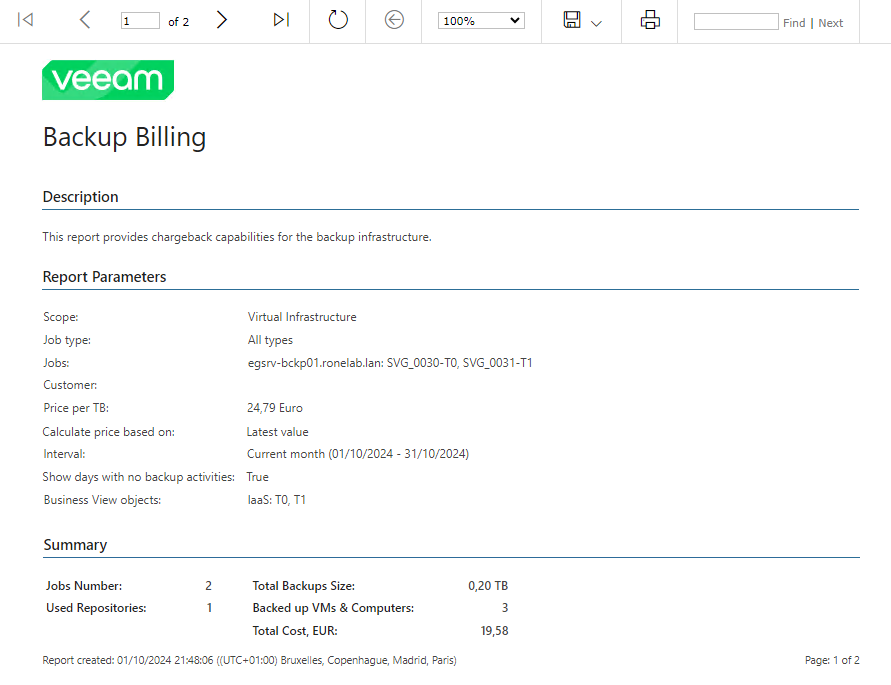 | 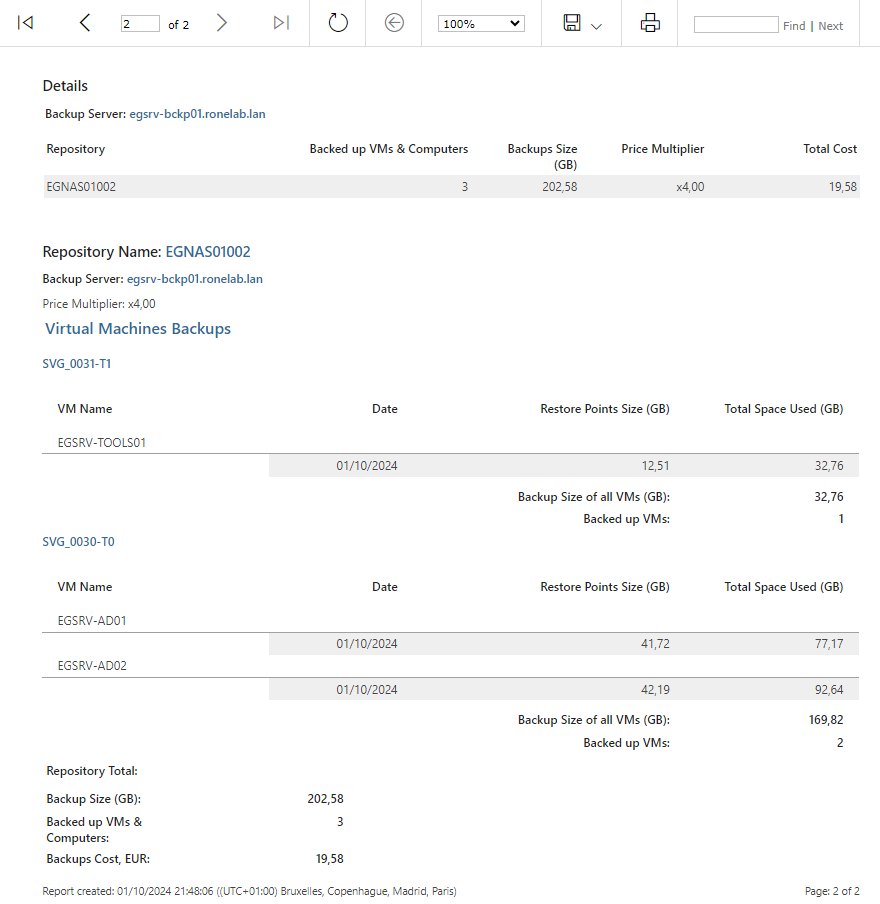 |
Franchement, que demander de plus ? Nous avons même inclus le cout de notre repository (multipliant le cout par 4). Et nous voilà avec le cout pour le mois en cours. A oui nous sommes le 01 Octobre…. J’ai peut-être eu la main lourde sur le prix unitaire au TB 🙂
Bref, pas mal pour mettre en évidence le ROI12 <3
Nous allons vérifier par le biais d’un rapport que nos ressources allouées sur notre infrastructure ne sont pas sous/surprovisonnées. Dans le cas contraire, il faudra engager ou non des actions.
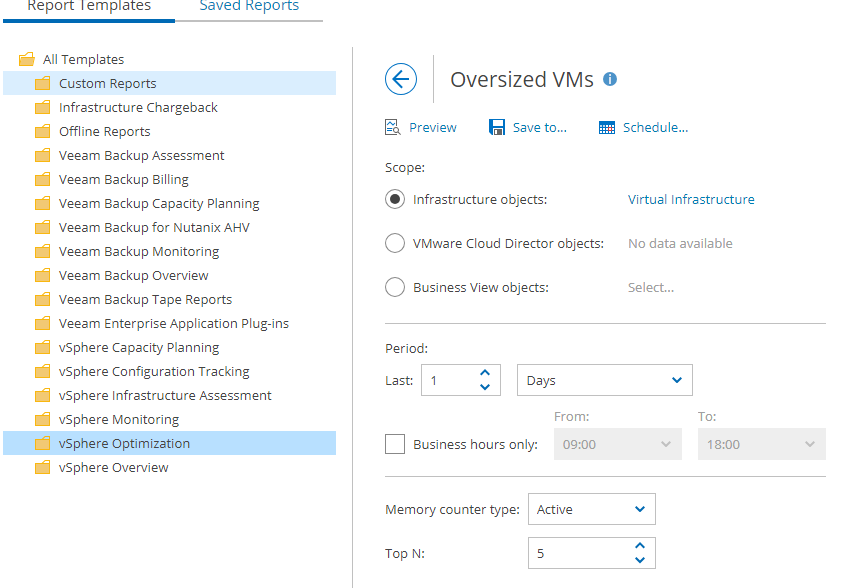
On valide une nouvelle fois sur Preview, puis on tourne trois fois sur sa chaise de bureau.
| Page 1 | Page 2 | Page 3 |
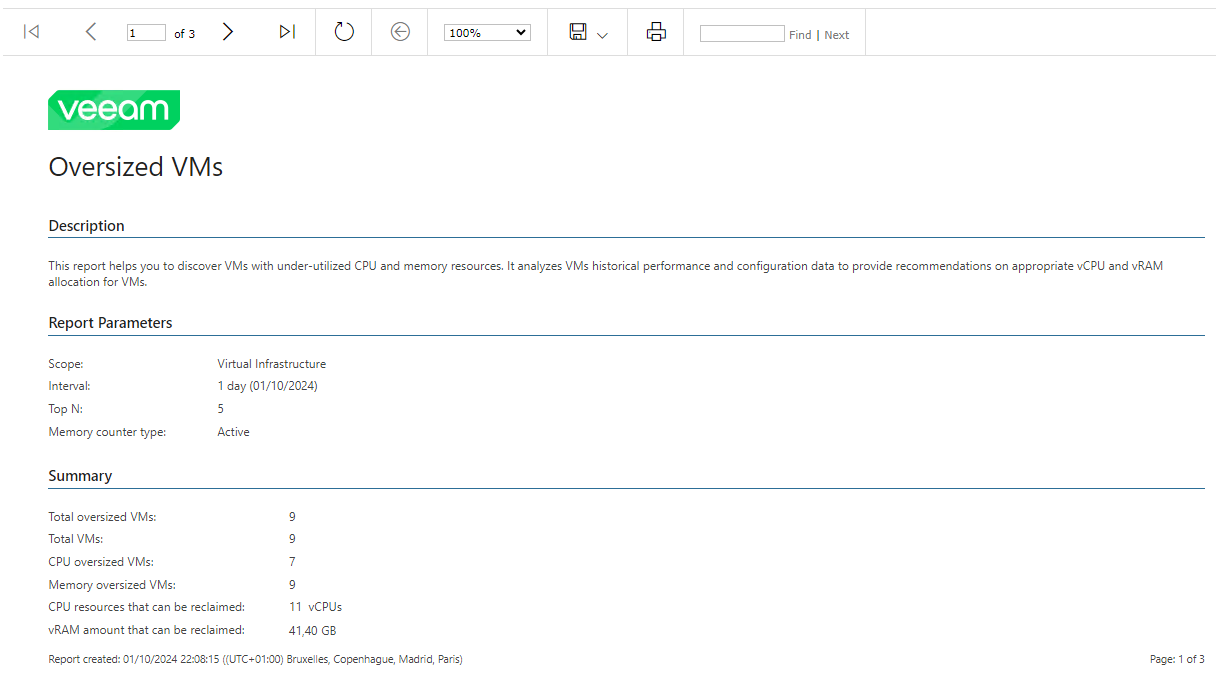 | 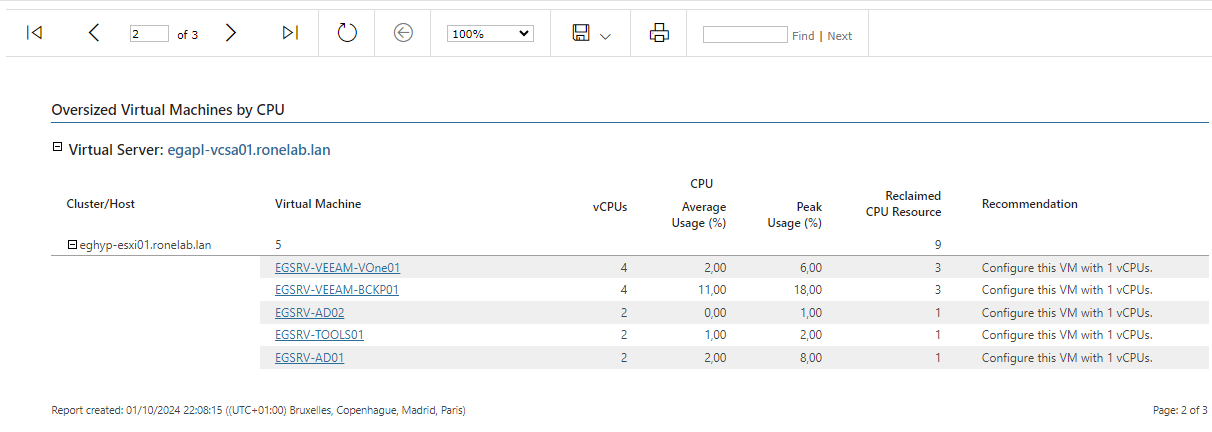 | 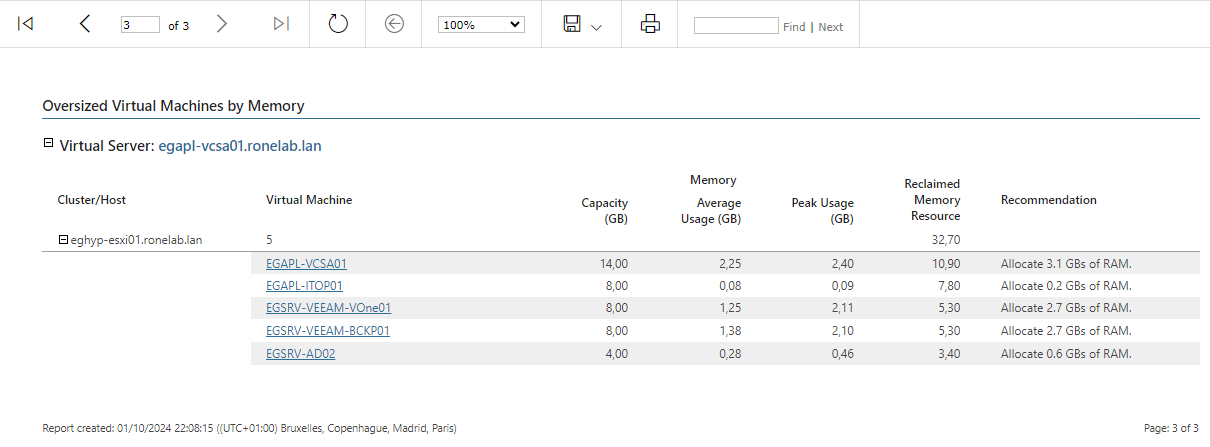 |
Alors c’est super nous pouvons faire des économies en réduisant considérablement les ressources !
Tout doux bijoux !
Ce ne sont que des recommandations, il ne faut pas prendre tout pour argent comptant. L’évaluation est une moyenne et viens prendre en compte les piques de suractivités. Mais ce n’est pas pour autant qu’il ne faut pas réfléchir. Dans le cas de mon lab, les ressources se (je ne sais pas si je peux me permettre cette expression… Allez… Vous ferez mon procès ultérieurement) touchent ! Mais si nous ciblons une heure bien précise (genre sauvegarde par exemple) les recommandations ne seront pas les mêmes. Il est également important de bien faire attention au paramètre de génération du rapport.
Le rapport sera différent si nous considérons le compteur de vRAM en « Active » et « Consumed ».
Pourquoi avoir pris ces deux exemples ? Tout simplement pour montrer la dimension économique et technique de la supervision. Dans un monde de brut où nous licencions au vCPU, il est important de maitriser l’allocation des ressources. Il est également important de ne pas mettre en péril son organisation quant à la sauvegarde vis à vis de son activité tout comme mettre celle-ci en péril parce que cette dernière représente un cout certain.
Dans un contexte particulier de Service Provider (Fournisseur de Service), il est également important d’avoir un curseur le plus juste possible entre la facturation client et le service délivré sans offrir des ressources sans le vouloir et vendre à perte.
Les rapports, c’est la vie.
Conclusion
La supervision et l’ensemble des outils qui sont mis à disposition par VEEAMOne permettent d’unifier et de rendre la Technique au service de l’administration et de la stratégie financière. Une telle synergie ne doit pas être négligée et doit être mis en place.
De par mon expérience de responsable informatique auprès des clients que j’ai accompagnés, l’informatique et la gestion du SI sont toujours trop onéreux. Menant souvent à l’accumulation à terme d’une dette technique conséquente qui devra être acquitter plus tard. L’erreur qui est faite à ce moment par le responsable informatique est de ne pas avoir présenté les choses sous le bon angle.
Mais alors qu’est ce que le bon angle pour éviter la traditionnelle tragédie racinienne ou choix cornélien ?
Je pense que pour répondre à cette question, il faut que le Responsable Informatique prenne de la hauteur pour présenter le SI sans aborder de terme technique pour commencer et présenter des métriques ainsi que des projections sur l’évolution du SI.
Je fais un aparté, sans déco**é une fois, j’ai un DG qui a explosé en réunion à la suite de la prononciation du mot switch xD. La personne qui avait énuméré le mot a dû donner une définition. Chose qu’il a fait en parlant de commutateur… Le DG a explosé de nouveau. Mon collègue à côté fini par intervenir (avant un nouvelle intervention de la personne en interne) en expliquant « c’est une multiprise réseaux ». Le DG a compris sans problème. 🙂 Aparté terminé.
De rapprocher ce dernier sur l’activité de l’organisation et de définir les axes d’évolutions possibles. Un plus serait de soutenir un budget prévisionnel ainsi qu’un plan d’amortissement. Présenter de cette façon en tenant compte du besoin et de l’activité de l’organisation va faciliter les décisions et permettre à la direction d’avoir une vision claire de son informatique. Mais pour en arriver là, il est nécessaire de savoir ce que nous souhaitons surveiller et interpréter. N’oublions pas que si les diseuses de bonnes aventures lisent dans les boules de cristal, les membres de la direction lisent dans les fichiers excels et les SysAdmins dans les logs. <3
Je pense qu’il est donc primordiale d’utiliser VEEAMOne (non je n’ai toujours pas d’action chez VEEAM) pour répondre aux besoins du quotidien d’un SysAdmin ainsi que pour la stratégie d’une organisation. Il faut cependant de la rigueur et ne pas se disperser dans les catégorisations et l’élaboration des rapports. L’objectif étant de maitriser son SI, se prémunir des pannes et de garantir une stratégie d’investissement financier.
VEEAM ? One ! Raviolis ? Je relance avec une requête CIM. Je contre avec un arbre ! Dommage, il y avait un DAF en diagonal. Aïe Aïe Aïe, votre SI va chercher son solde de tout compte. Mais vous gagnez un pins de Marlène SCHIAPPA. Alors heureux ?
Erwan GUILLEMARD
Sources
- VEEAM One : Guide
- VEEAM One : Guide – Ports
- VEEAM One : Supported Virtualization Platforms
- VEEAM One : Supported VEEAM BR
- VEEAM One : Supported System
- VEEAM One : Sizing
- ITOP
- RVTOOLS
- MO : Mode Opératoire ↩︎
- VBR : VEEAM Backup et Réplication ↩︎
- VCC : VEEAM CloudConnect ↩︎
- VCSA : VCenter Server Appliance ↩︎
- RTFM : Read The Fucking Manual (please 🙂 ) ↩︎
- RBAC : Role Based Access Control ↩︎
- ESXi : Elastic Sky X Integrated ↩︎
- IHM : Interface Homme Machine ↩︎
- SNMP : Simple Network Management Protocol ↩︎
- ITSM : Information Technology Service Management ↩︎
- API : Application Programming Interface ↩︎
- ROI : Return On Investisment ↩︎
À L.LU , mon étoile, le plus parfait des sciences.