Cahier 1 : Network Disaster
Cet article s’inscrit dans le projet de compilation de mes « mémoires » personnels quant à toutes mes expériences professionnelles. Ces derniers ont pour objectifs de présenter une situation et d’apporter les conclusions à ces différentes expériences ainsi que les axes d’améliorations.
Volontairement, aucuns noms, sociétés, marques, lieux et dates ne seront cités.
H+0h00min – Réveil douloureux
Samedi, 8h30 du matin. Le téléphone professionnel vibre sur ma table de chevet (qu’est-ce qu’il fout là, d’abord). Deux appels manqués, trois notifications de messageries instantanées. Avant même de décrocher, je sais que la journée va être compliquée tout comme mon réveil.
Je décroche. Mon collègue et directeur d’agence m’informe que plusieurs remontées clients nous informent que notre plateforme d’hébergement n’est plus disponible.
Il n’en faudra pas plus. Les mots « clients », « hébergement » et « plus disponible » ont remis la machine en marche. Ma « cafetière » (comprendre mon cerveau) tourne à plein régime et hurle tel le moteur diesel qui n’a pas eu le temps de chauffer suffisamment. J’informe mon collègue que je dois vérifier et réaliser d’urgence un diagnostic. Nouveau point de situation dans 30 minutes au plus tard.
Dans la plus simple des tenues, les cheveux en bataille j’attaque un diagnostic (Tu as vraiment besoin de rentrer aussi loin dans le détail ?).
- Plus d’accès à la plateforme par la voie normale
- Plus de mail à partir d’une certaine heure
- Côté FAI1, rien à signaler
- Accès sur l’infrastructure de secours par la voie d’urgence
- Plus d’accès aux équipements, isolation de l’environnement de secours
H+0h30min – Diagnostic
Diagnostic effectué. Il y a une anomalie sur notre infrastructure réseau ou de calcul (comprendre infrastructure serveur). Nous sommes aveugles. Nous devons intervenir physiquement sur site. Retour auprès de mon N+1 pour établir le constat. Nous devons intervenir urgemment sur site. L’intervention est validée.
L’équipe sera composée de deux personnes, lui et moi. Nous avons et avions l’habitude de travailler ensemble. Chacun sait ce qui doit être fait.
Nous nous donnons rendez-vous sur le site du siège à 9h45. Le temps de nous préparer et de mon côté prendre tous équipements, ressources matérielles qui pourraient être utile.
Je dis au revoir à ma petite tribu en leur annonçant que je n’ai aucune idée de l’heure à laquelle je vais rentrer (super excuse pour ne pas faire les corvées hebdomadaires, quoi que j’aurai préféré les corvées).
De son côté, mon collègue informe le président ainsi que les autres membres de la gouvernance de l’incident en cours et de la criticité de ce dernier.
H+1h15min – Plan & route
Après une douche à l’arrache, je passe au siège de notre organisation récupérer le carton de fourniture dédié à nos équipements en production. Dans l’attente de mon « taxi », je m’autorise un café double, double expresso serré (manger les grains de café et les chiquer reviendrait au même) tout en établissant la liste des scénarios possibles d’avaries ainsi que toutes les solutions réalisables.
Pas le temps de finir mon café, que nous voilà reparti. La journée s’annonçait mal et ça semblait se confirmer puisque le GPS nous préconisait un itinéraire de substitution à l’itinéraire normal. Peut-être lié à un trafic dense ce weekend là ? Allez savoir…
Durant le trajet comme tout bon fataliste que je suis je présente les pires scénarios potentiels :
- Perte du cluster de production
- Perte du réseau
- Perte de l’ensemble de l’environnement
Toutefois je vis mieux la situation que ce que je le pensais. Même si l’éternel optimisme de mon collègue vient à dédramatiser la situation que je véhicule. Je crois et suis même certain que cette qualité de relativisme est un nécessaire indispensable pour un être un bon leader. Un N+1 se doit d’être exemplaire et d’ouvrir la voie.
Le désespoir est une forme supérieure de la critique. Pour le moment nous l’appellerons bonheur.
Léo Ferré – La Solitude
Bref, notre tandem à toujours fonctionné, pourquoi douter ?
En chemin, je déclenche l’astreinte de notre prestataire et partenaire. Par le plus grand des hasards, nous connaissons bien la personne d’astreinte il n’y a pas de problème pour l’intervention, nous le contacterons à 5 minutes de notre arrivée sur site.
H+2h45min – Arrivée sur site et… STOP !
Après une bonne heure et demie de route (itinéraire de substitution oblige), nous arrivâmes sur site. J’avais informé notre correspondant 5 minutes avant notre arrivée. Tous semblaient rouler.
Je présente mes habilitations auprès du poste de contrôle en introduisant mon binôme non habilité. Douche froide, « On ne passe pas » (hasard ou pas j’ai intérieurement ri de la situation). Les agents de sécurité nous ont informé d’un incident sur le site qui venait de se produire et nous nous pouvions donc pas intervenir dans le DC. Plus précisément, le TGBT2 venait de prendre feu…
Là concrètement ça la fout mal.
- Nous ne pouvons pas accéder au DC à la suite de l’avarie électrique en cours
- Nous ne pouvons pas identifier la panne présente sur notre infrastructure
- Notre hébergeur et partenaire est bloqué au même niveau que nous
- Nous ne pouvons éteindre l’infrastructure (si quand bien même elle est disponible) à distance
Après un rapide échange avec la sécurité, l’agent d’astreinte, nous devons attendre l’intervention d’ENEDIS. Au vu de la criticité et de la loi des séries (pour ne pas dire d’emmerdement maximum), nous engageons notre partenaire et nous les mesures nécessaires. (Je vous avais dit que j’étais frappé d’infortune ?)
Notre PDG n’en revient pas, la PDG de notre fournisseur interviendra physiquement sur le site 10 minute après l’information de cette nouvelle. Ce qui est, je pense, une nouvelle fois gage d’implication et de qualité de service auprès de nous ainsi que de l’ensemble de leurs clients. Parenthèse ouverte, les clients trouvent toujours que les services sont trop onéreux, mais dans ce genre de situation ils sont heureux d’avoir ce niveau de prestation, d’implication et de sérieux. Ceux qui maintiendraient le contraire, je ne leurs souhaite au grand jamais d’être confronté à une situation similaire sans avoir ni le son, ni l’image de ce qui se trame… Fermons la parenthèse.
Nous sommes donc contraint par cette nouvelle péripétie de tuer le temps. Nous allons déjeuner, le rétablissement des services est estimé entre 30 et 90 minutes.
H+3h15min – Du gras et du froid
D’accoutumé, je préfère un repas réconfortant. Intervention loin et technique équivaut à une pinte et un plat riche. Dans le contexte que nous vivons cela se résumera à du sucre, du gras rapidement. En un mot et un seul, FAST-FOOD.
Je vous laisse devinez qui est tombé sur la borne qui ne fonctionne pas ? Qui a un burger froid ? Bref. Nous mangeons. Toujours dans la réflexion de ce qui peut se produire sur notre système d’information. Difficile de changer de sujet pour ma part et ce malgré les efforts de mon collègue.
Le téléphone sonne nous informant que j’ai gagné au loto. Ah non faut pas déconner non plus ! Le téléphone sonne m’informant que nous pouvons accéder au datacenter et que l’alerte relative au TGBT est sous contrôle.
J’ai raccroché le téléphone. Top à la vachette, 10 minutes après nous étions de nouveau sur site (et en respectant le code de la route).
H+3h45min – Du bruit et des cellules grises
Nous sommes en place. Nous entrons dans le DC3. Pour partager le sentiment qui me traverse. Imaginez vous à Noël, enfant avant de découvrir vos cadeaux sous le sapin. Inversez le sentiment et vous avez mon ressenti. Mon cœur n’est plus dans ma cage thoracique, il gambade dans le hall d’entrée, 50 mètres plus loin.
Le DC est ok. La température est normale, les alimentations normales. Les baies sont ok, notre baie est ok. Mais ça siffle dans notre baie.
Pour qui sont ces serpents qui sifflent sur vos têtes ?
Jean Racine
C’est parti pour le check up des équipements, ce n’est pas normal.
Et toi qu’est que tu regardes en premier chez une femme ? Bah je sais pas je ne regarde que des baies info…
Ma grosse crainte, c’est le crash du cluster de serveur. Mais ce dernier visuellement indique que l’ensemble des serveurs sont sous tension et fonctionnent. Le cluster de firewall est ok. Par contre le réseau c’est « weird » comme le dirait un gars d’outre manche…
Nous avons une infrastructure réseau spécifique qui n’est pas standard sur les « petites » infrastructures. Généralement pour une PME avec juste un hyperviseur ou une infrastructure HA4 avec une baie de stockage, nous avons un stack de switch de couche 2. Dans le cas d’infrastructure hyperconvergée ou importante, nous sommes plus sur des switchs datacenter couche 2, couche 3 voir couche 4. Soit au minimum 2 switchs spines, et 2 switchs leafs.
(En gros, ça donne l’architecture classique ci-dessous)
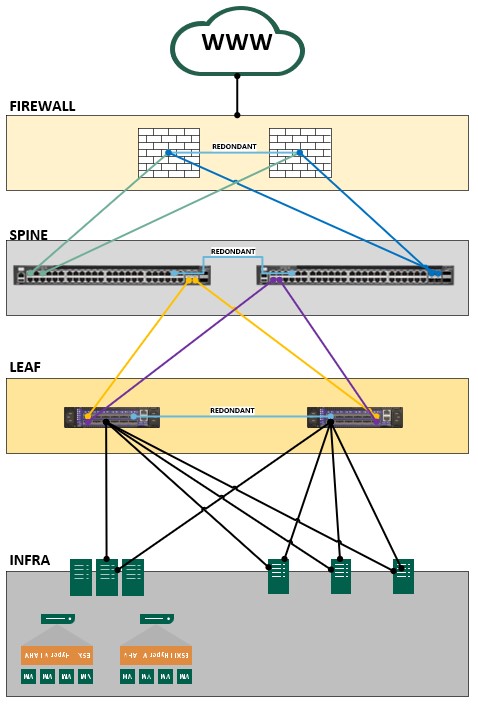
Et c’est là qu’il semble avoir un problème. Les deux switchs spines sont en orange, les deux leafs sont ok. Naturellement les deux types de switchs sont résilients l’un de l’autre.
Premier diagnostic : La panne se situe au niveau des spines. L’infrastructure continue de se voir par commutation au niveau des leafs mais n’ont plus accès à la partie supérieurs soit le wawa (www) et les firewalls. Certes, mais qu’est ce qui se passe vraiment ?
Si je sais bien une chose avec les équipements réseaux, c’est qu’il est INDISPENSABLE pour un TECHNICIEN ou SYSADMIN d’avoir un câble et adaptateur CONSOLE/SERIE (le message est clair je pense avec l’usage de majuscule). Malheureusement, la loi des séries s’abat encore sur ma tronche. Mon adaptateur USB/Série n’est pas reconnu ni compatible avec WIN11. Hello darkness, my old friend… Bon mon collègue à un poste en WIN10. Il sauve la mise.
Il se connecte sur le premier switch. L’affichage du terminal ne nous indique rien de bon… La ROM5 semble avoir lâchée. Les blocks et les cylindres propres au stockage interne sont perdu, plus de partition. Nous décidons de reboot le premier switch. Si ça sifflait, là maintenant ça hurle ! Le terminal console est complétement perdu. Le boot de l’équipement est complétement hors service et boot en boucle.
Le premier switch est mort, vive le switch. Passons au second spine.
En console de nouveau, les mêmes retours sur le terminal. Afin de valider l’interprétation, nous demandons l’avis de notre prestataire. Il valide nos craintes. La ROM semble bien HS.
Le second switch est mort, vive le switch.
(Ce qui se résume sur le plan architecture par le schéma suivant)
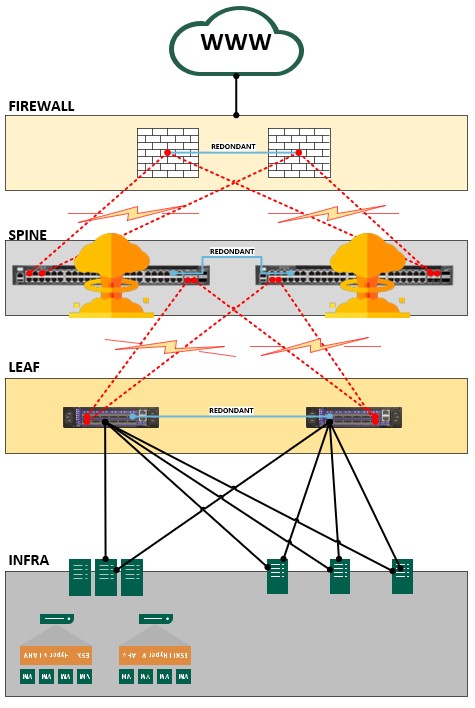
Conclusion, les deux switchs spines sont mort car les deux roms ont lâché. Cela ne m’étonne pas et ça arrive. La probabilité est quasi inexistante pour ne pas dire nulle, mais c’est le cas. Les deux équipements ont le même âge et sont proches par leurs numéros de séries. Mais ce n’est pas grave, les équipements sont sous garantie avec GTR 4h, 24/24 – 7/7j.
Mais c’est beau d’avoir une garanti, mais faut il encore l’avoir déclenchée et savoir comment elle fonctionne… C’est toujours dans les situations d’urgence que nous nous rendons compte que ça coince. Et spoiler, ça va coincer !
Nous appelons le support constructeur au US. Ce dernier nous informe qu’il n’y a pas de problème mais que nos équipements ne sont PLUS sous garantie.
Popop qu’est ce que tu nous racontes ! J’ai passé un BL et je me suis fait ch**r à le faire toussa toussa.
Pour moi s’est bien parti à notre fournisseur. Notre interlocuteur américain (si je synthétise) nous répond qu’il n’y a pas de problème pour intervenir, mais qu’il nous faut la facture comme preuve du renouvellement de la garantie.
Je vous le donne en mille, où est notre applicatif métier ? Sur l’infrastructure qui n’est pas joignable (lol, xptdr comme nous le dirait le millénials qui sommeil en moi).
Et c’est parti pour le grand plongeon dans nos boites mails à base de recherche de:X, objet:Y, a:Z ect. Comme ça ne suffit pas, nous demandons au PDG de se rendre au siège pour trouver le document papier. Nous dérangeons d’autres collaboratrices… Bref après une bonne heure nous arrivons à la conclusion que :
- Le devis nous l’avons
- Le bon de commande nous l’avons
- La facture nous ne l’avons pas
- Le montant relatif au renouvellement de garantie n’a jamais été débité
Vous la voyez la douille ? 🙂 (J’en ris maintenant, mais je ne rigolais pas du tout à ce moment).
Lors du rencontre avec ce fournisseur, il nous avez été dit la fameuse phrase « Vous pouvez m’appelez de jour comme de nuit, je vous répondrai !« . Et bien c’est ce que nous avons fait. Une fois, deux fois, trois fois sans résultat. Je viens d’un milieu professionnel et personnel où lorsque l’on donne sa parole, on l’a tiens. Quelle déception que cela se perde… Toutefois nous avons un autre contact chez ce fournisseur (qui nous a tenu le même spitch). Deux appels et nous avons un retour. Le contact comprend notre situation mais ne peut malheureusement rien faire car cela n’est pas dans son périmètre. Le contact regarde tout de même ce qui est envisageable de son côté pour éclairer notre lanterne et nous aider. (SPOILER, il n’y aura pas de retour car l’information ne lui ait pas accessible. Mais nous avons pu compter dessus et c’est déjà pas mal vu notre contexte).
Résumons, la situation. Nous avons deux équipements hors service. Une extension de garantie qui n’est pas valide. Nous avons identifié la panne, mais sans solution de remplacement des équipements défectueux.
H+4h45min – Tandem, Collaboration et Champollion deuxième langue
Nous voilà donc dans une impasse. De l’autre côté, l’incident survenu en parallèle du notre mais décorrélé de toutes incidences nous a permis d’éviter un arrêt total de notre cluster et surtout la présence de la présidente de notre fournisseur ainsi que de l’opérateur d’astreinte.
Ces derniers viennent s’informer de notre situation et si nous avons soldé notre panne. Nous leurs expliquons la situation et indiquons que nous réfléchissons à la meilleure porte de sortie possible.
Je me souviens de l’échange de regard entre nos partenaire qui en un regard se sont compris. S’en est suivi un « Nous pouvons peut-être vous aider ? Qu’est ce qu’il vous faut comme équipement ? ».
Cette proposition tombe à point nommé. Toutefois et dans ma nature pessimiste, je me dis que les équipements anciennement fonctionnels sont tellement spécifiques (marque, modèle non dans nos standards avec des performances élevées etc) que ça ne fonctionnera pas. Mon collègue ainsi que notre prestataire ne sont pas de cet avis. Il faut tenter.
- Qu’est ce qu’on a perdre ? Rien, ça ne fonctionne plus de toute façon
- Qu’est ce qu’on a à gagner ? Ca refonctionne mais en dégradé dans le pire des cas.
Nous acceptons donc la proposition et nous voilà avec deux switchs d’une marque et modèle différents. Problème, je ne suis pas à l’aise avec cette marque d’équipement. Le réseau reste le réseau, mais les commandes de configuration varie d’une constructeur à l’autre, du firmware et des modèles dans une même gamme (CISCO != HPE Procurve != ARUBA CX != MELLANOX != DELL et nous pourrions continuer…). Bien que maintenant nous arrivons à une certaine standardisation des configurations avec ce que l’on pourrait appeler des équipements CISCO Like.
Je pense maintenant avec le recul que cette situation de crise a été intéressante pour l’opérateur d’astreinte autant que nous.
Comment reprendre la configuration puisque les deux équipements sont HS ?
Je suis malchanceux certes, mais prévoyant. J’ai dû omettre précédemment un point important lors du diagnostic. Nous disposons d’une dernière sauvegarde des configurations lorsque nous avons réalisées la dernière modification. Mais pour être certains de la véracité de la configuration, j’ai réussi à sauvegarder la configuration des deux équipements avant de les redémarrer et de perdre la main dessus. Prudence est mère de sureté dirait l’autre.
Nous nous organisons. D’un côté l’opérateur va configurer les équipements. De l’autre, je lui dicte chaque ligne du fichier de configuration et nous adaptons la configuration. Un peu comme CHAMPOLLION avec la pierre de rosette pour passer du hiéroglyphe au grecque.
Sans plan ça a du être galère ? Comment être certains que l’interface N va sur l’équipement X dans le subnet Y en marqué (tagged) et dans le subnet Z en native non marqué (untagged) ?
L’un de mes anciens managers (et mentor), responsables du service avait établi une sérigraphie physique de chaque équipement, de chaque interface. C’est long à faire, c’est fastidieux à maintenir et demande beaucoup de rigueur. Toutefois et cela a été démontré à cet instant précis, nous avons gagné un temps monstrueux pour reprendre la configuration.
La sérigraphie, couplée aux différents plans d’adressage nous ont été d’une grande aide et salvateur en plus des connaissances de l’infrastructure dans la cafetière qui me sert de cerveau.
Je rédige rapidement un pseudo plan de changement d’urgence eCAB6 dans un notepad impliquant les actions de migration et les tests de vérifications qui en découlent.
H+5h45min – Commutera ou Commutera pas ?
En moins d’une heure la configuration des deux équipements étaient reprise sur les équipements de substitution à l’exception de certaines options. Nous avons réalisé une sauvegarde préalable car nous savons que nous allons devoir ajuster la configuration. Et ça serait stupide de prendre une heure de taf de nouveau dans la vue.
Retour dans la salle serveur. Je vous parlerai plus bas de mon pire ennemi, la climatisation.
Là, tout n’est qu’ordre et beauté, Luxe, calme et volupté.
Charles Baudelaire, L’invitation au voyage
Dans notre cas je dirais plus
Là, tout n’est que lumière et néons, froideur, bruit et volupté (quand même faut pas déc****r).
Erwan Guillemard, L’invitation au changement d’urgence
Le bruit des climatisations et des ronronnements de tous les équipements rend difficile les échanges mais nous y arrivons.
Nous installons les équipements, puis attaquons le plan de changement rédigé quelques minutes plus tôt.
- Interconnexion des nouveaux équipements avec les LEAFs Switchs
- Vérification d’accès aux ressources d’infrastructures
- Test de HA des équipements temporaires SPINEs Switchs
- Bascule de tous les équipements interface par interface
- Test de bon fonctionnement
Et bien St Thomas aurait été là, il en aurait eu pour son argent et il aurait pu constater que ça commute ! St Thomas, saint patron des informaticiens ? Et bien NON ! Il existe un Saint Patron des informaticiens et c’est St Isidore. #NoFake Je mourrai moins c*n ce soir (la petite mort ça compte ? :p )
Hormis une petite boucle réseau au début et quelques rares ajustements sur certaines interfaces notre infrastructures est de nouveau disponible.
Les équipements réseaux supportent la charge.
H+6h45min – Allo, églantine ici mirabelle
Nous validons avec les équipes opérationnelles nous ayant fait remonter l’incident impactant leurs clients que tout est rentré dans l’ordre.
Les tests réalisés ensemble confirme le succès de l’opération.
H+7h00min – Remerciement et Retour
Nous étions tous satisfait des résultats de ce travail collaboratif. Le retour à la normal de nos services nous soulageaient autant que notre partenaire.
La fatigue nous retombait dessus progressivement, personne n’a été épargné. Nous avons chaudement remercié la présidente ainsi que l’opérateur d’astreinte de leurs actions, investissements quant à l’assistance à la résolution de notre incident critique.
Nous nous séparons, NOX ayant déjà bien entamée sa course.
H+9h00min – Fin du road trip
Le trajet du retour a été difficile. Le travail intense de la journée, la stratégie, l’adaptation face aux divers aléas, la communication, le stress qui retombent accentuent la fatigue. Toutefois, nous débriefons de l’incident sur la route du retour et notons les points positifs, négatifs. Nous évaluons le risque de la solution temporaire et du plan d’action à engager le lendemain et le Lundi suivant.
J’annonçais déjà la rédaction d’un REX7, pour ne pas perdre une once d’information et d’expérience de cette journée.
A jouer les Cassandres, je finis par croire que je suis Cassandre. Mon collègue me fait relativiser sur ce point, même s’il reconnait à demi-mot que la loi des séries c’est bien appliqué.
Arrivé à la maison, j’ai repris la place que j’avais laissé 9h00 plus tôt et paradoxalement j’ai bien dormi.
Conclusion
Il est je crois sensible de travailler avec des technologies équipements ou solutions qui sont à la marge de nos habitudes quotidiennes. Il est nécessaire de pratiquer constamment pour « maitriser » son infrastructure. Avec du recul, je me suis rendu compte que d’une version à l’autre des firwmares du même model de nos équipements, la configuration ne pouvait pas être repris simplement. Donc si nous avions eu à remplacer les deux équipements hors service, nous n’aurions pas pu rétablir les services rapidement. Je préconise donc de sélectionner des équipements sur lesquelles nous avons une expérience bien assise et où la configuration puisse être reprise rapidement et cela même avec une version différente de firmware.
Nous savions que les équipements devaient être remplacé prochainement, mais même avec une souscription d’extension de garantie, la situation nous a montré que nous pouvons être dans une voie sans issue The way is shut.
C’est là l’un des risques que chaque SysAdmin possède. Avoir une garantie ou assistance mais ne la déclencher que lorsque l’on rencontre une avarie, et se rendre compte que ça ne fonctionne pas, ça fait mal (Un coup de pied dans les b****s serait limite plus agréable.). Il faut être vigilant sur ce point lors de la souscription ou reconduction. Au-delà du confort, il convient de mesurer le rapport bénéfice, risque et de définir le RTO8 et le RPO9 que l’organisation que nous représentons s’autorise.
Le choix de ces partenaires et prestataires est crucial. Il faut une relation de confiance et ne pas hésiter à les challenger. Car c’est dans ce genre de situation que nous sommes content d’avoir une main tendue, Relève la gueule, je suis là, t’es pas seul. Il en est de même pour l’organisation interne. Dans cette situation, les rôles se sont distribués naturellement et face à l’incident nous étions une équipe et nous ne sommes pas tomber dans l’individualisme. La communication et la fréquence de cette dernière est importante. Donner de la visibilité sur l’incident en cours sans noyer d’informations les destinataires mais sans non plus négliger ces derniers.
L’un des points salvateurs de tous SysAdmin, c’est la rigueur. La sauvegarde des configurations des équipements actifs à chaque modification et de manière périodique doit être inscrit dans le PAS10. Il est je pense impératif d’avoir les documentations à jour de son système d’information. Le petit plus reste la sérigraphie des équipements réseaux.
Le mot de la fin :
Je commute en infogérance et relance une chenille dans le couloir. Tu..Tu..Tu..Tu ne peux..Tu..Tu. Vous avez une boucle sur votre réseau et c’est pas du BabyLiss.
Erwan Guillemard
- FAI : Fournisseur d’accès internet ↩︎
- TGBT : Transformateur Général Basse Tension ↩︎
- DC : Data Center ↩︎
- HA : Hight Availability ↩︎
- ROM : Read Only Memory ↩︎
- eCAB : Emergency Change Advisory Board ↩︎
- REX : Retour d’EXpérience ↩︎
- RTO : Recovery Time Objective ↩︎
- RPO : Recovery Point Objective ↩︎
- PAS : Plan d’Assurance Sécurité ↩︎