PROJET – Dream Nebula, VMWare KPI Partie 2 : Pratique
L’objectif de cette partie est d’expliquer comment déployer l’outil. Toutefois et sans les sources, ce dernier ne sert pas à grand chose. Cependant, si le projet devient communautaire, alors ce dernier prendra tout son sens 🙂
Comme dit précédemment pour GreenRay, il s’agit là d’un Readme dans un format différent du traditionnel fichier txt et du wiki.
Prérequis
Dernier point avant de taper dans le fond du sujet, le déploiement ne se fait que dans un environnement WINDOWS (Workstation ou Server) ayant au minimum la version Powershell 5 d’installer et qui prend en charge les communication TLS1 en version 1.2 minimum.
Bien que pas j’ai automatisé un bon nombre d’installation de dépendances certaines restent tout de même à déployer manuellement. Toutefois, les outils à déployer manuellement concernent la partie exploitation de la donnée qui peuvent et doivent être dissocier de la partie serveur.
Naturellement et bien que cela coule de source, LES PRIVILEGES ADMINISTRATEURS sont nécessaire au premier usage pour l’installation des dépendances (logique non ?).
Back End
Les prérequis sont les suivants :
- Module powershell PSSQLite : Ce dernier est déployé automatiquement par l’application. Toutefois, il est possible d’installer cette dernière manuellement.
- Module powershell PowerCLI VMWare : J’ai à ce jour une version alpha du déploiement automatique du module. Toutefois ce dernier n’est pas intégré dans le projet Dream Nebula, mais dans un projet à part SS_042_VMWareInstalled-PowerCLI. Il sera donc nécessaire de déployer ce dernier manuellement.
Front End
Sur le serveur ou poste qui servira à exploiter les données il sera nécessaire d’installer les dépendances suivantes :
- Drivers ODBC2 for SQLite3
- Microsoft PowerBI (si powerBI utilisé)
- DB3 Browser for SQLite (en option mais pratique pour débugger ou altérer des données dans les tables)
L’installation des divers composants ne représente aucun point bloquant. J’ajoute en fin de ce billet les sources pour télécharger les différents composants. Pour vraiment prendre la main de chacun le processus d’installation est disponible ci-dessous.
L’un des points problématiques à mon sens se porte sur l’origine du site qui n’est pas en HTTPS. Mon expérience de jadis sur la technologie SQLite fait que j’ai dû utiliser ce site. Je n’ai jamais eu de problème.
Oui, j’ai dû chercher dans les mémoires que j’avais rédigé à l’époque…
Pas de difficulté en soi. Il est toutefois opportun de posséder un compte Microsoft…
Toujours en mode enfonçage de porte… C’est pas un copié/collé de l’article précédent ? Chhhhhuuuuuuttttttt
Configuration
Avant de lancer le script, il est nécessaire de faire un tour vers le fichier de configuration contenu dans le répertoire config à la racine du projet. Je vais prendre le temps de décrire chacune des parties de ce fichier.
Le fichier se découpe en 1 partie et 5 sous-parties.
| * Une sous-partie globale qui définit les paramètres du script et de son fonctionnement * Une sous-partie dédiée à la VCSA4 permettant d’établir la connexion à l’API5. * Une sous-partie dédiée à l’export des données au format CSV, reliquat de la version 1 LEGACY * Une sous-partie concernant l’envoie de notification SMTP6, futur feature/bug (rayer la mention inutile) à venir * Une sous-partie dédiée à la base de données SQLite. Faut bien stocker les données quelques parts * Une sous-partie concernant le paramétrage du mode service en tant que tâche planifiée | 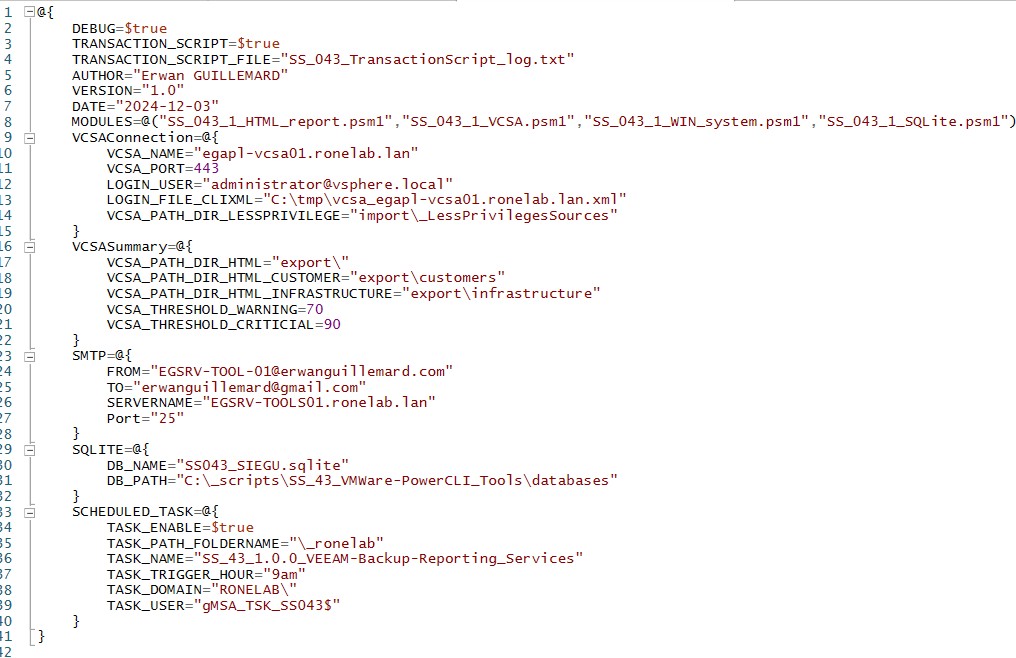 |
Après cette longue énumération rébarbative, regardons en détail chacune des parties et sous-parties. Bandant n’est il pas ? J’avoue que je ne fais pas ch**r du tout car mes deux applications ont le même tronc, socle, base… Vous voyez quoi ? 🙂
J’ai ajouté dans la solution la possibilité d’éditer le fichier directement depuis l’interface console. Par sécurité, j’ai ajouté une fonctionnalité de régénération automatique du fichier en cas de suppression ou de corruption. Hé oui, j’en ai eu marre de me repalucher le fichier de configuration plusieurs fois à la mano…
Avec la compréhension du fichier de configuration, je pense que nous pouvons passer à la suite, soit déployer l’application sur le serveur.
Installation
Comme toujours, je dédie une disque et volume pour mon application, 5Go suffit amplement.
Les raisons sont toujours les mêmes et cela reste un point immuable de mon caractère professionnel. Il est impératif de dissocier le système d’exploitation des applications ou data pour se prémunir de toutes anomalies du système et d’un dépassement d’espace de stockage. Nous générons des logs et nous avons une base de données foutre bleu ! (Pourquoi bleu… Personne n’a jamais su m’expliquer…).
l suffit de déposer le répertoire à la racine du lecteur D:\ ou d’ailleurs puis de définir les paramètres du fichier de configuration. Et puis c’est tout. 🙂
Lancer le script SS_43_1.0.0_VMWare-PowerCLI.ps1 pour réaliser les opérations d’initialisation et vérification des dépendances. On me chuchote dans l’oreillette qu’il faut faire un clic droit Exécuter avec Powershell (en tant Administrateur).
Attention : Seule la première initialisation nécessite les droits d’administrations.
Lors de la première initialisation EN MODE MANUEL (MAIN), les credentials de connexion vous seront demandés dans le contexte de votre machine et de VOTRE session pour générer le fichier CLIXML.
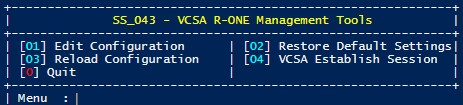 | 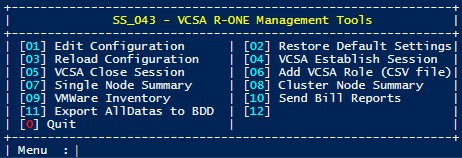 |
Dans la première image, nous constatons la présence de 4 menu.
- [01] Edit Configuration : Permet d’ouvrir le fichier de configuration et de modifier ce dernier.
- [02] Restore Default Settings : Permet de lancer un rappel max ou le sort de magie blanche Vie Max / Vie 2 sur le fichier de configuration pour ressusciter, régénérer celui-ci face au spell UTLIMA que vous avez lancé sur ce pauvre fichier !
- [03] Reload Configuration : Permet de recharger le fichier de configuration et l’ensemble des variables de l’application.
- [04] VCSA Establish Session : Permet d’ouvrir la connexion à l’appliance VMWare à partir des éléments transmis plus tôt.
Si la connexion aboutie, vous devriez voir apparaitre ce même menu avec d’autres options complémentaires.
- [05] VCSA Close Session : Permet de terminer la session en cours.
- [06] Add VCSA Role (CSV File) : Permet de créer le rôle VMWAre avec les bonnes permissions pour l’appliance. Entre nous, je l’ai fait une fois et l’automatiser et bien… c’est chiant… C’est pourquoi, je dois revoir le fonctionnement. Aujourd’hui il est plus simple de le faire manuellement. M’enfin c’est comme ça.
- [07] Single Node Summary : Permet de faire l’inventaire et l’affichage des ressources d’une single node VMWare dans la console. Je reviendrai sur ce point plus tard. 🙂 Un peu de suspense pardi.
- [08] Cluster Node Summary : La même chose que précédemment mais pour une cluster VMWare avec plusieurs nodes 🙂
- [09] VMWare Inventory : Génère les rapports au format HTML. Je présenterai rapidement la chose, mais de mon point de vue, remplacer par les rapports PowerBI.
- [10] Send Bill Report : Envoi les données par mail pour une potentielle refacturation.
Naturellement, si le mode DEBUG est activé et que la redirection des sorties dans un fichier de log également, nous devons avoir en amont les entrées ci-dessous.
Concernant le mode Service, le fonctionnement et partiellement le même sans les fonctionnalités manuelles. En gros et pour faire simple, cela suit simplement le cycle de vie :
- Je vérifie les prérequis pour l’application
- Je m’authentifie à l’appliance
- J’exécute mes requetes
- Je récupère les données et les stocks dans la BDD
- Je me casse Whiskas
Donc normalement notre tache planifiée est là. Je passe encore une fois mon tour sur l’usage et la création du compte gMSA.
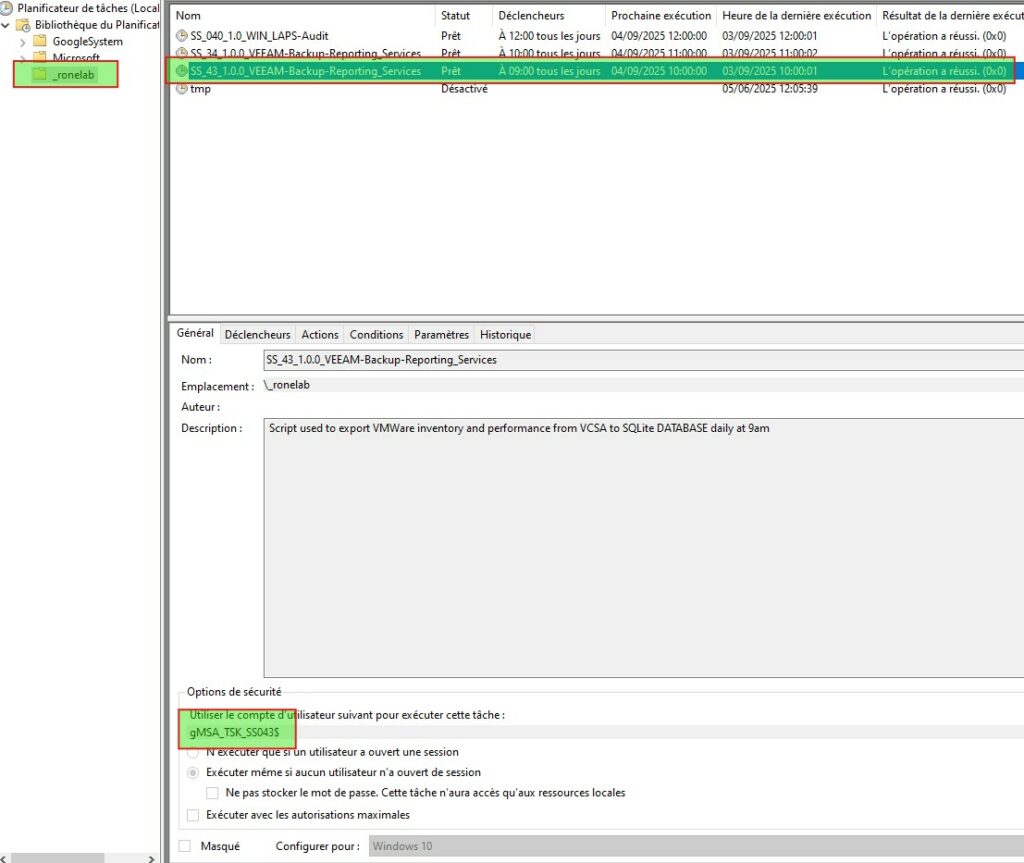
A ce stade, nous avons donc installé l’ensemble des modules (VMware et PSSQLite), déployé la tache planifiée avec le mode service, généré notre BDD et réalisé notre première extraction.
Comme pour GreenRay dans le cas de possible erreur, je rédigerai une quatrième partie KB.
Et maintenant si nous regardions le rendu ?
Exploitation des données, Reporting
Je pense aborder cette partie en 3 axes. Une vue de la console CLI, la vue HTML bien que j’hésite encore sur son sort (Vivre ou laisser mourrir ?) et pour terminer la partie Microsoft PowerBI.
Mais avant toutes choses, ayant passé un peu moins de 300 heures sur le projet, je vous fournit le modèle de liaison de données (MLD) de ma BDD lié à PBI.
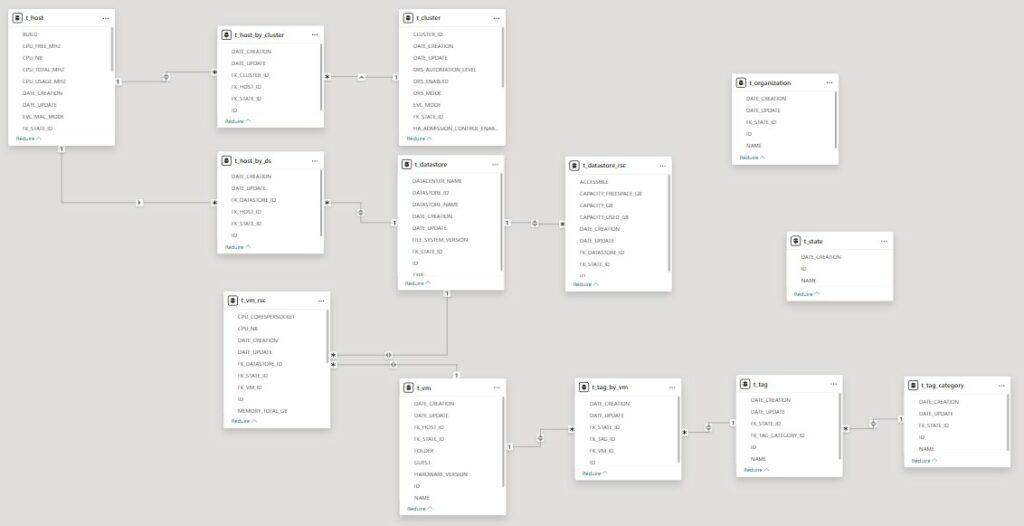
Je ne suis pas satisfait de ma BDD. Il manque un élément crucial. Bien qu’implémenté dans le projet GreenRay, je ne l’ai pas fait ici. Oui, il n’y a pas de log. Ca, voyez vous c’est moche… Aussi moche que Robert HUE au congrès du MEDEF…
Après bien que ce soit SS_043, il est la première graine, la première application vis à vis de SS_034. D’où je crois cet oubli, absence, négligence ou fénéantise de ma part sur la BDD. Pardon SS_043…
CLI View
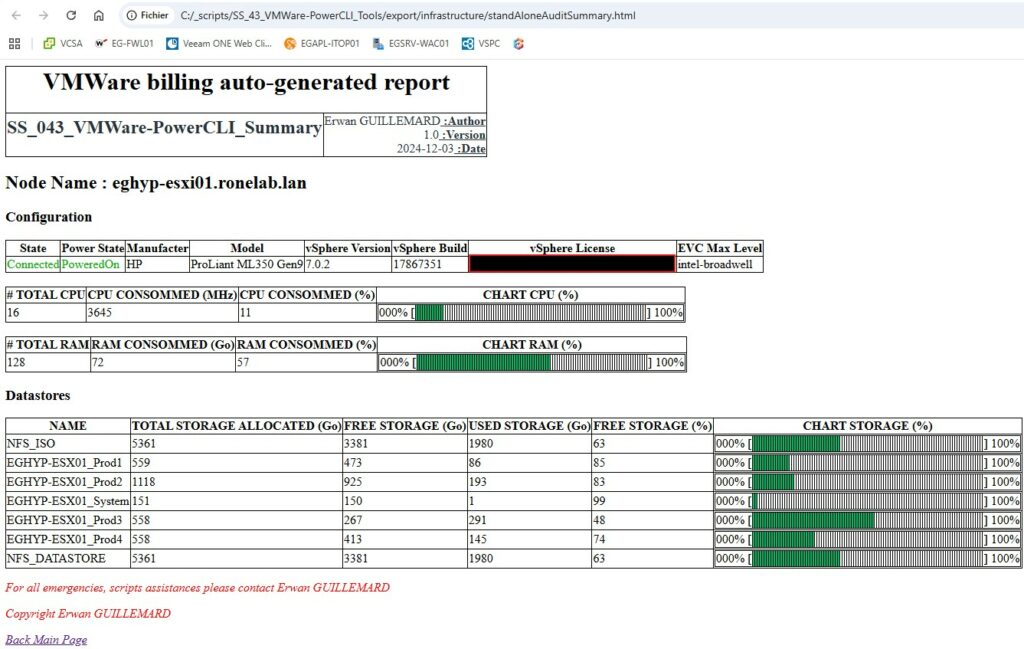
Comme vu ci-haut, j’ai voulu permettre d’un simple petit coup de powershell d’afficher la synthèse VMware d’un node. Sans pour avoir à jongler d’un onglet à l’autre dans l’interface web ESXi ou VCSA.
C’est juste du one shot. Toutefois, je ne pourrais pas montrer de vu CLI d’un cluster. Je vous garantit toutefois qu’il est fonctionnel. Néanmoins, je ne peux partager les données.
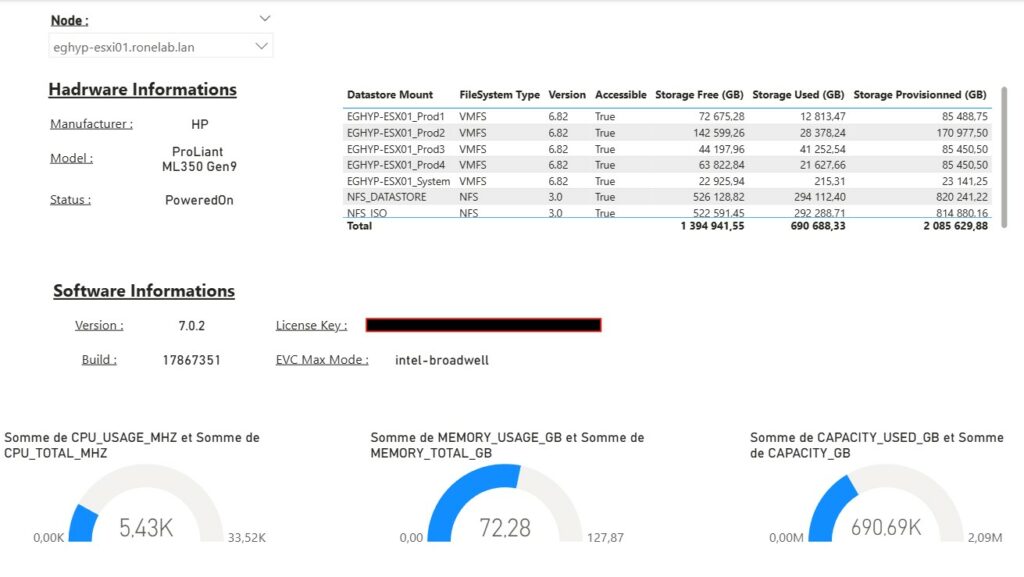
| Bref, si nous appuyons sur [07] Single Node Summary nous afficherions dans notre console une synthèse de notre hote, l’usage CPU, RAM ainsi que l’ensemble de la consommation du stockage de chaque datastore. Par amusement, j’ai même refait l’association des VMNic avec les vSwitchs et les groupes de ports… (Drôle de loisir…). A la base, je voulais savoir si lors d’ajout de ressource je pouvais ou non ajouter une ressource virtuelle sans tomber dans le piège de surallocation. | 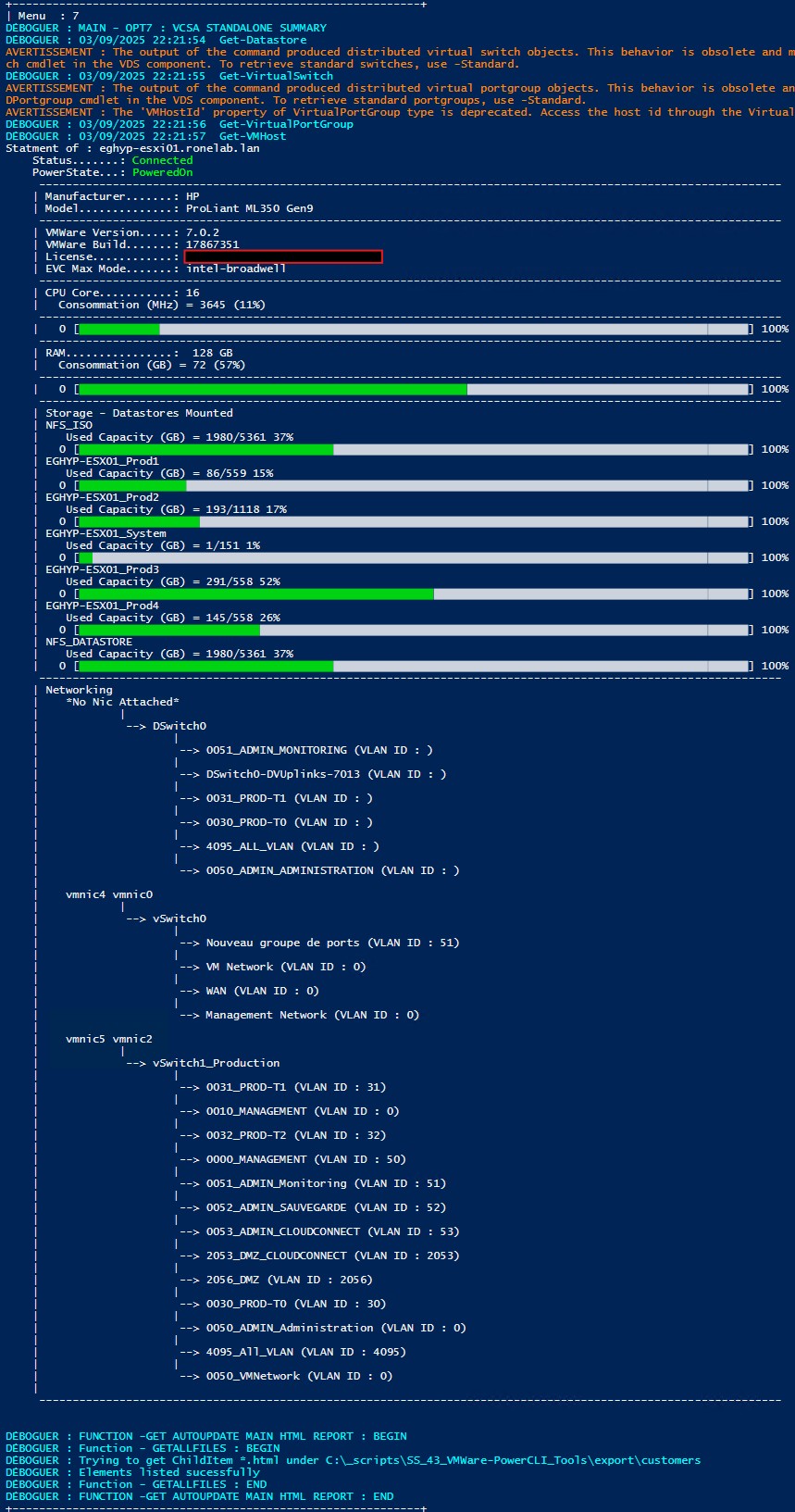 |
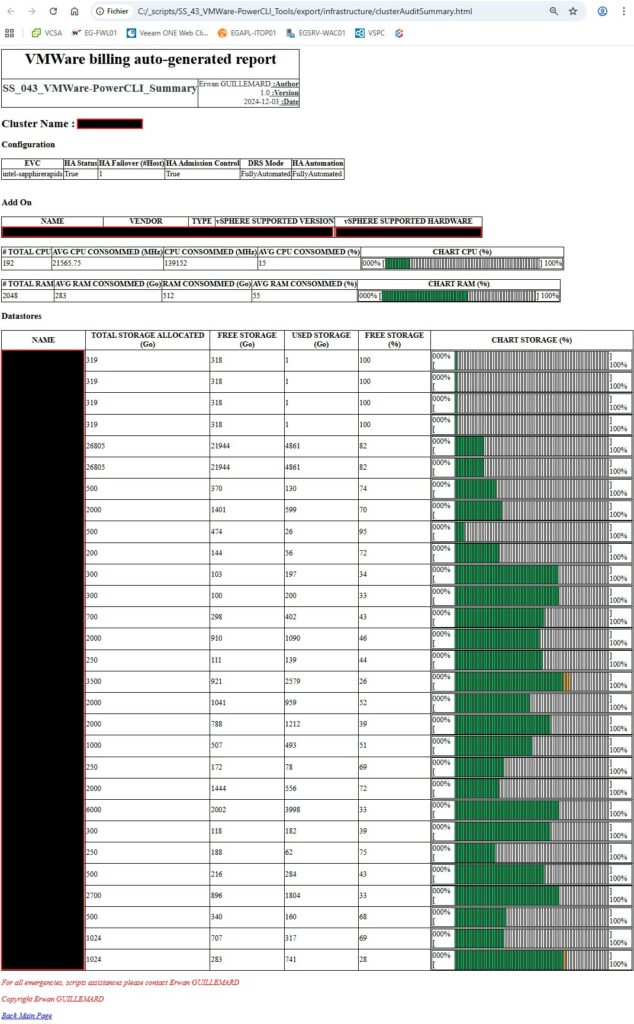
La différence avec la vue cluster ? J’affiche les informations et configurations de HA et DRS. Toutefois, je dois revoir la configuration réseau. L’affichage ne prends pas en compte pour l’instant les DVS11.
HTLM Report
Je partais dans l’idée, dans une entreprise de faire dans un petit serveur web un push des données pour que toutes personnes puissent consulter les données. Voilà pourquoi j’ai généré des fichiers HTML simple qui reprend les informations CLI vu plus haut en ajoutant une vue par bulle/client.
Pour cela il faudra se rendre dans le sous répertorie export :
Cela ouvrira de facto lors de l’ouverture du fichier main.html votre navigateur par défaut. L’ensemble du site est navigable (oui je me suis fait iech avec les liens hypertextes. En plus ils sont dynamiques selon les données recueillis par l’application. J’ai fait un effort !).
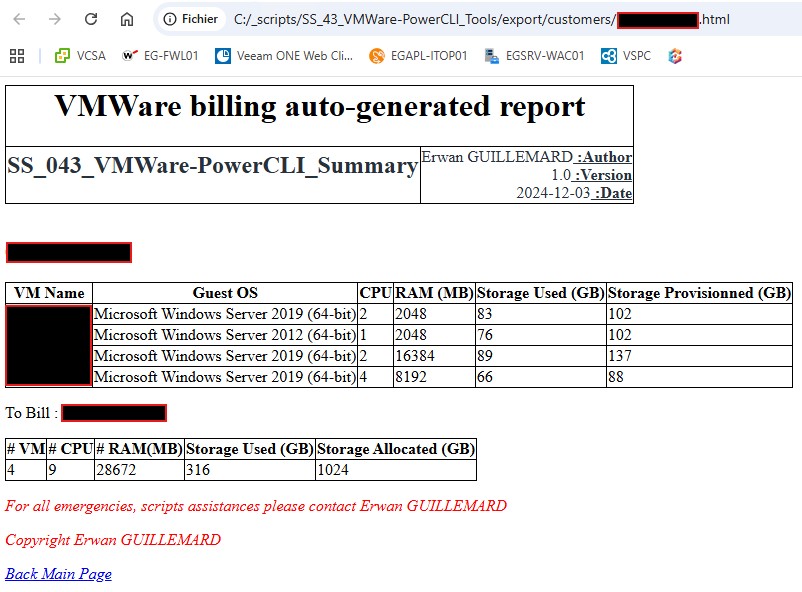
| Nous retrouvons donc la partie infrastructure avec les informations d’inventaire du système puis selon l’infrastructure matérielle une synthèse d’une infrastructure mononode ou en cluster. Ensuite et par bulle, nous avons une synthèse dans l’état actuel des ressources consommés. Pour la suite, je serai malheureusement contraint d’anonymiser certaines données. | 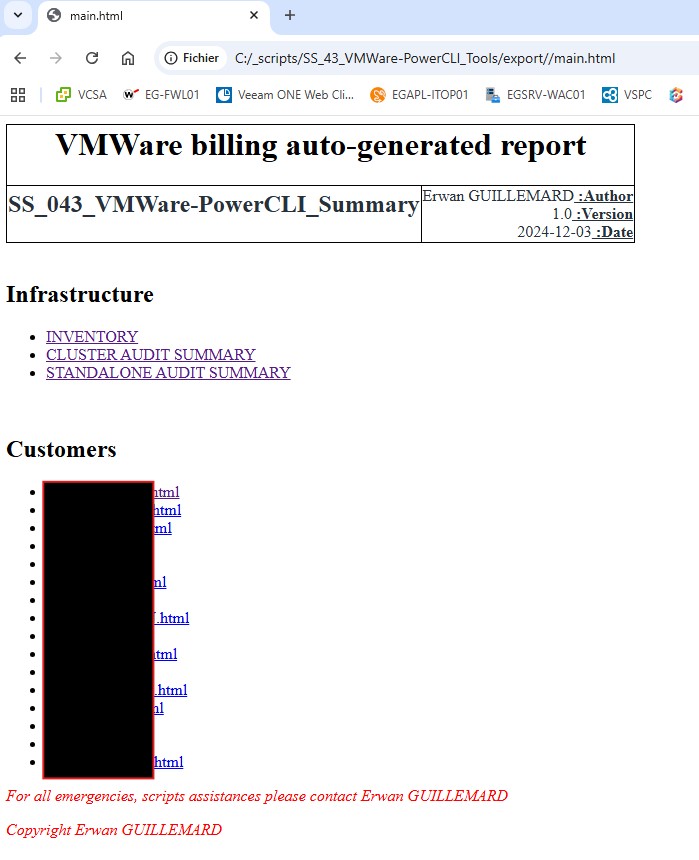 |
Attention : J’ai fait chacune des pages web à la main en mode Notepad++ et ISE. Alors s’il vous plait soyez indulgent.
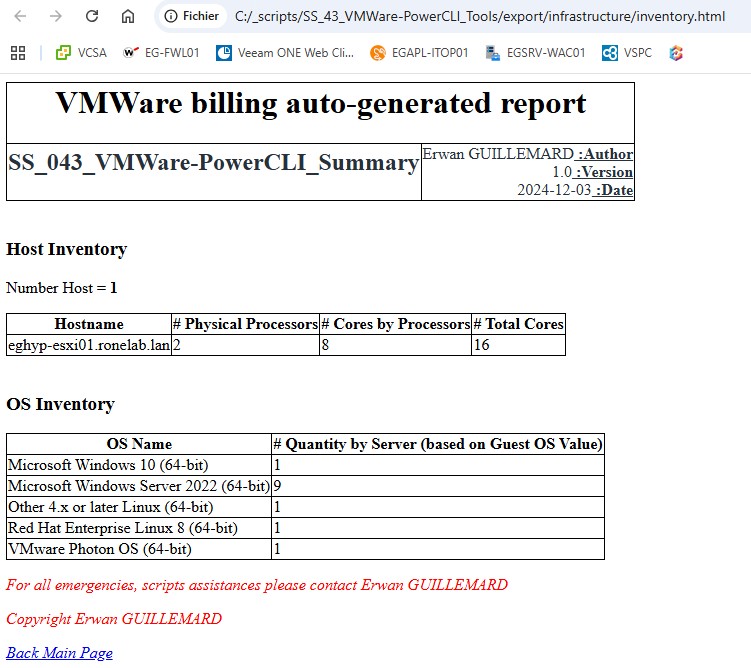
Il reste encore du boulot, j’ai trouvé ça fun et rigolo à développer. M’enfin c’est juste ma spécialité (le gars modeste…). Ma spécialité c’est de réinventer la roue 🙂
PowerBI Report
Là, contrairement aux deux modèles de reporting ci-haut vise un tout autre dimension. Car là nous allons pouvoir élargir notre vision dans le temps en affichant et travaillant sur un historique des ressources.
En des mots plus simple, l’évolution sur 13 mois glissant des ressources. 🙂
Ouvrer le fichier présent dans le répertoire Report.
Une fois ouvert, changer la source de données. Sinon vous allez avoir une erreur ODBC. Naturellement les drivers ODBC pour SQLite ont été installé préalablement sinon c’est la mort assurée…
Depuis l’application PowerBI, Fichier > Options et paramètres > Paramètres de la source de données.
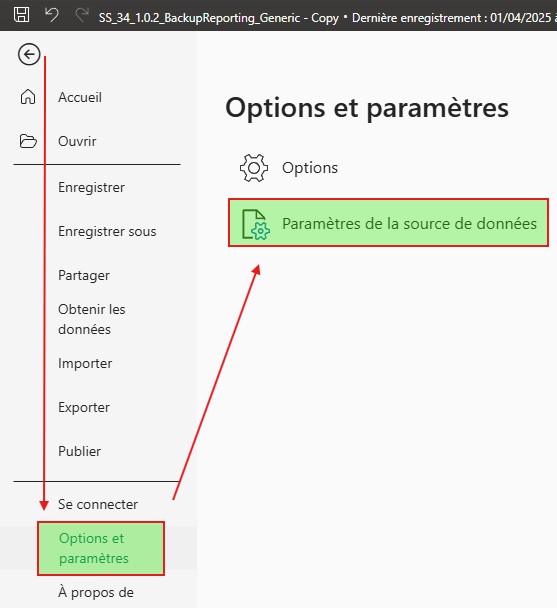
S’affiche à vous la configuration où charger les données. Il y a de forte chance que vous vous retrouviez avec l’un de mes Paths. Changer alors le chemin pour pointer vers votre BDD.
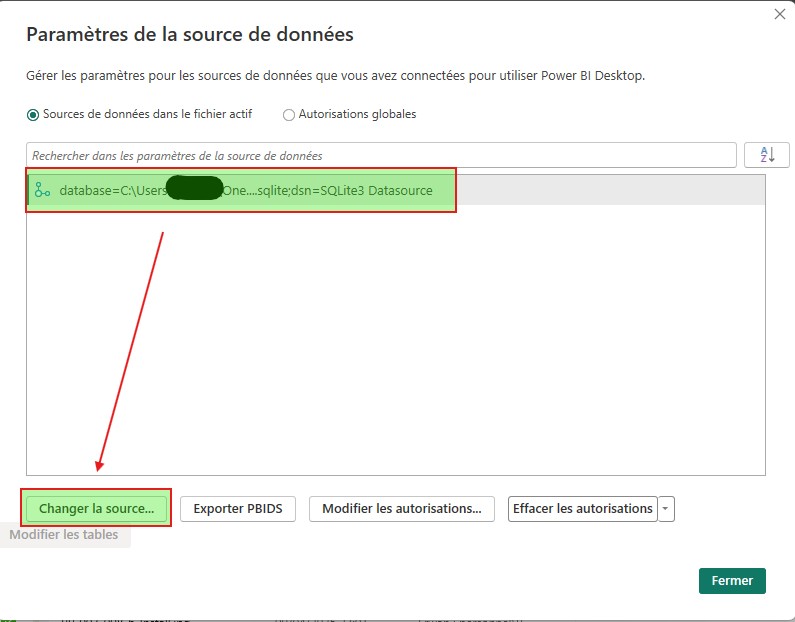
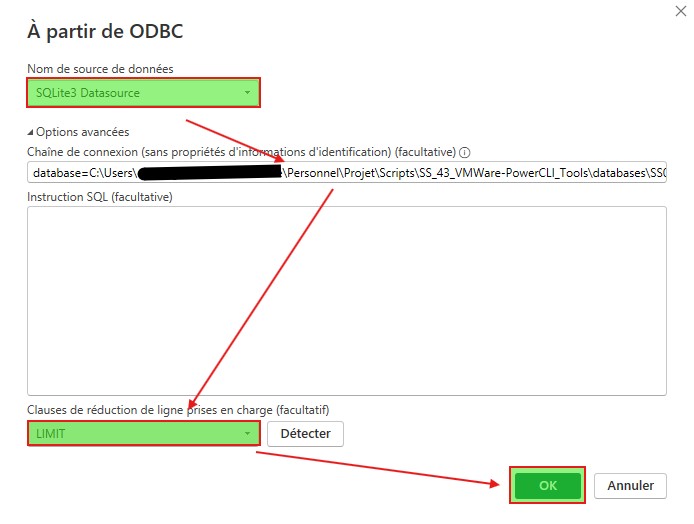
Dans la nouvelle fenêtre qui apparait, en premier lieu sélectionner en source de données SQLite3 Datasource. Modifier le chemin afin que celui soit de la forme database=<path>.
En guise de clause de réduction de ligne, choisissez LIMIT, puis confirmer la modification.
Il ne reste alors qu’à charger, actualiser les données dans le rapport existant.
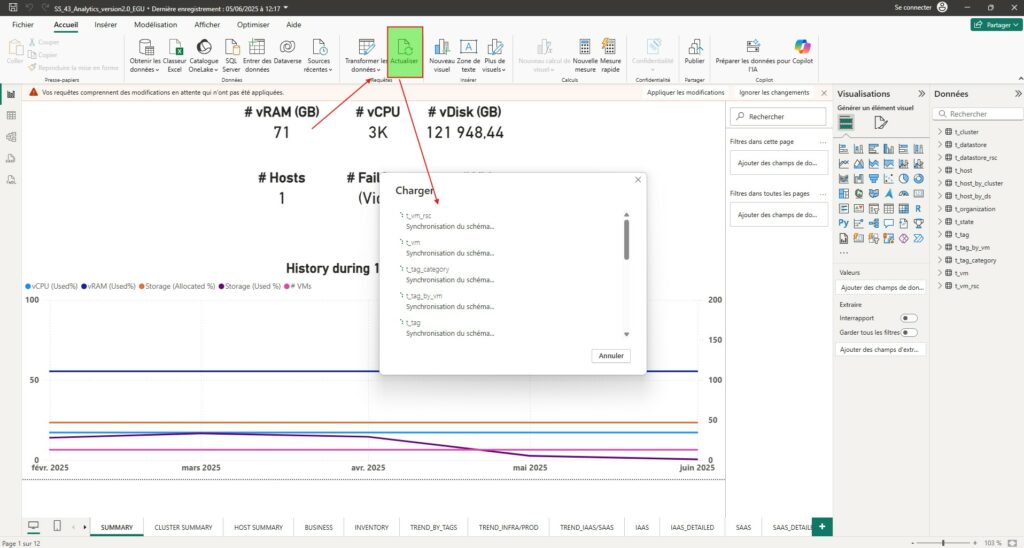
Normalement et il y a peu de chance que ce ne soit pas le cas, vous devriez avoir une multitude de coche vert en face de chaque table vous annonçant que les données ont été chargé avec succès.
Une fois les données actualisées, vous devriez avoir le rendu ci-dessous par défaut. Il vous faudra alors jouer avec les différents filtres et objets de contrôles sur les pages pour coller à vos données.
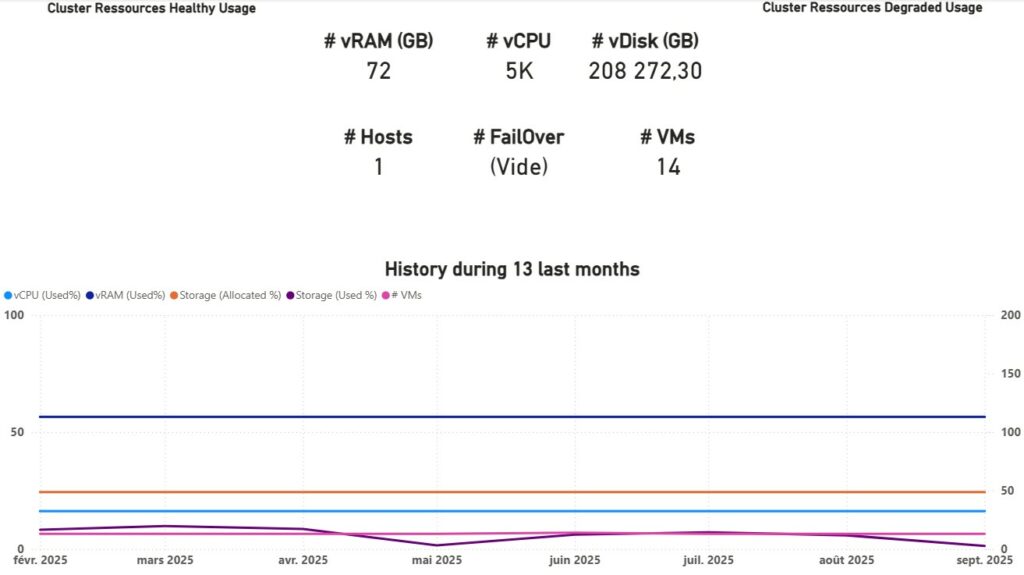
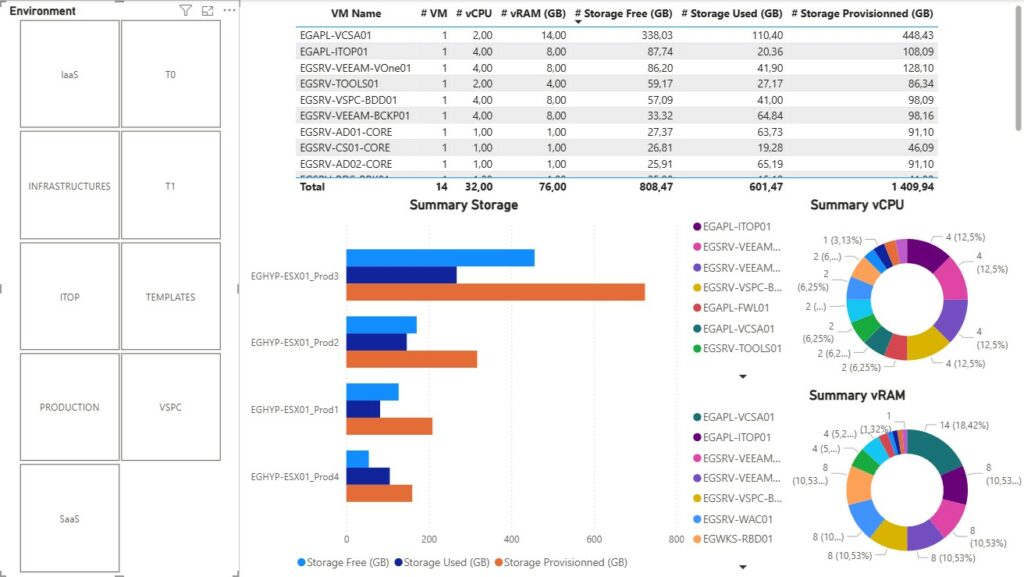
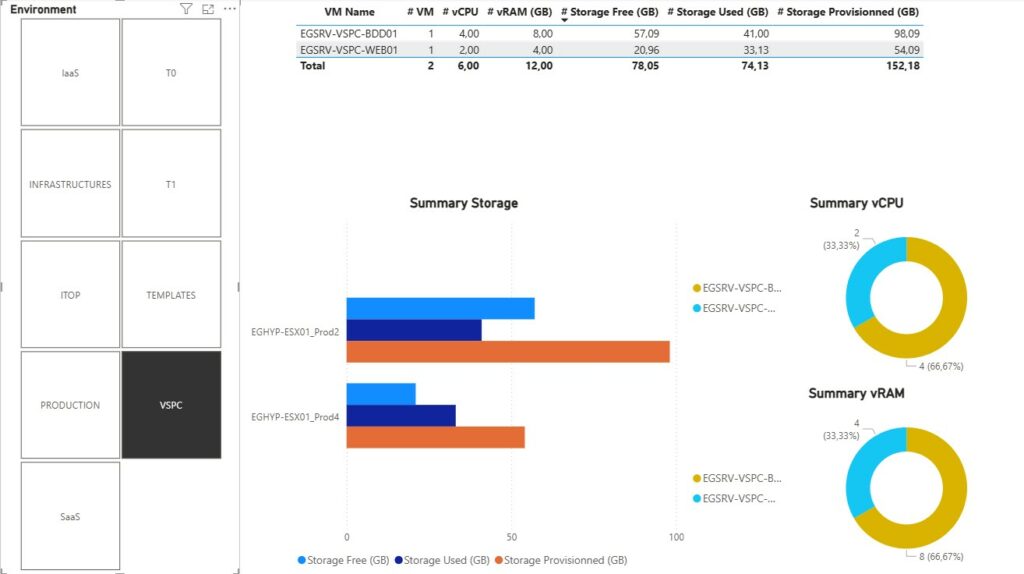
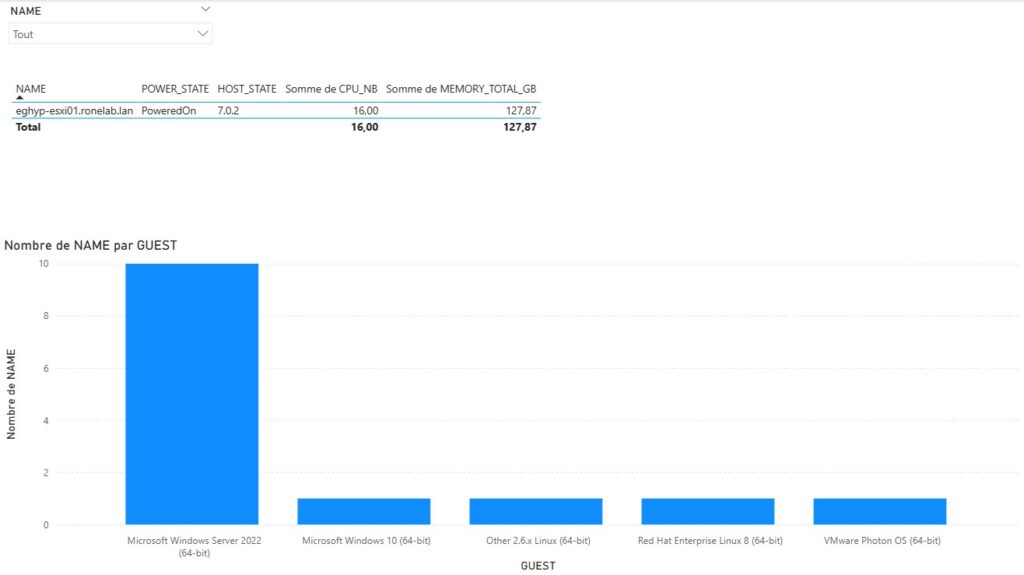
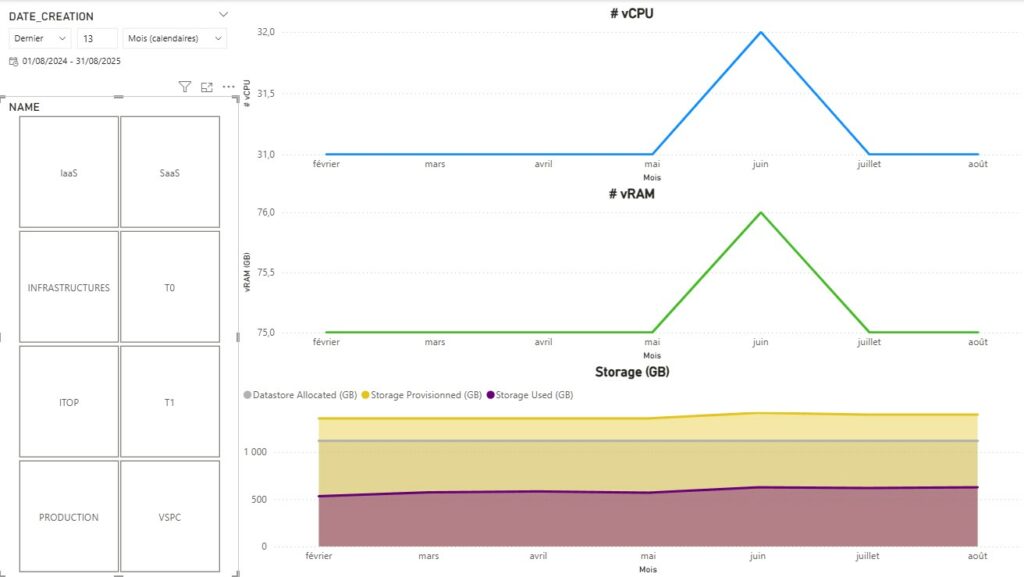
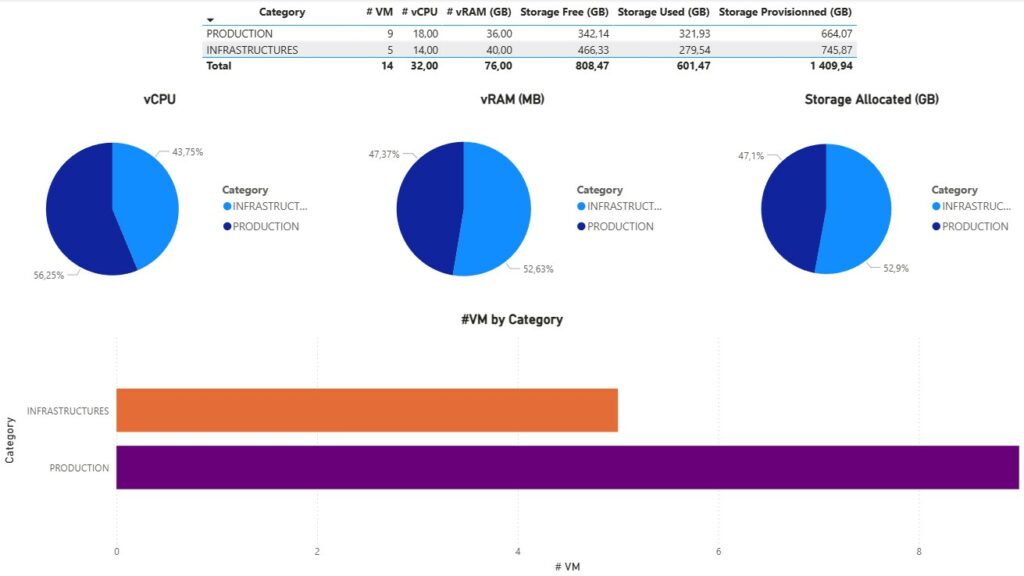
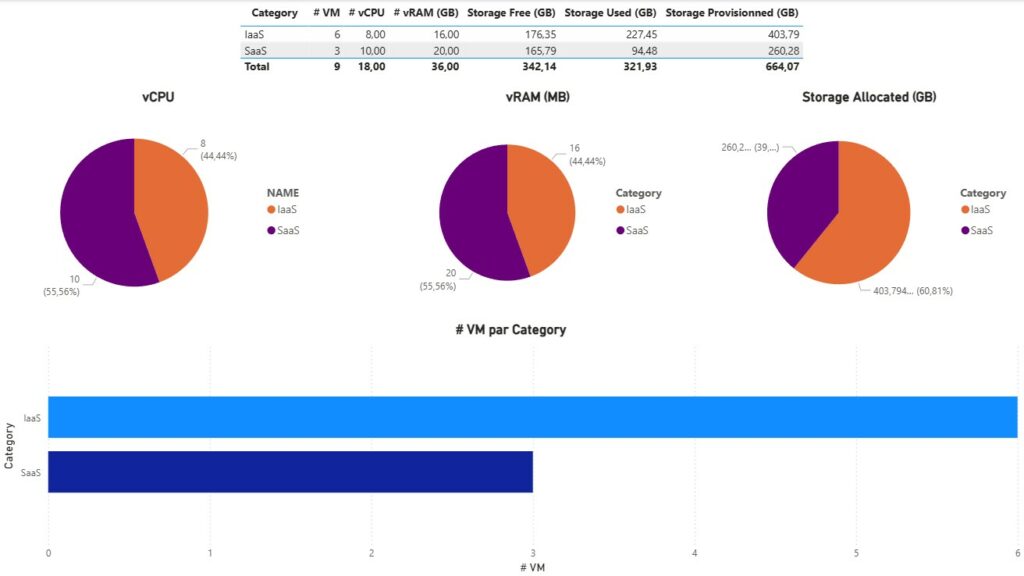
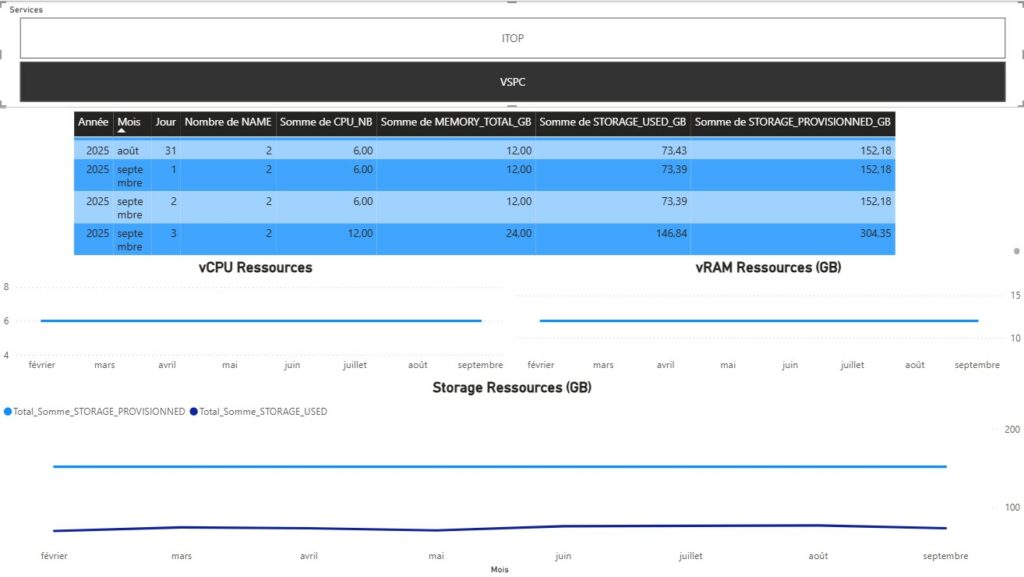
Rappelons nous notre problématique initiale. Je dis nous, mais au final c’est bien à moi de me rappeler ma problématique. Je pense que cette dernière est répondue avec un peu plus de fonctionnalité que prévu.
Ainsi, nous avons une visibilité totale sur l’ensemble du SI et des éléments virtuels qui le composent. Nous pouvons également donner la tendance et l’évolution dans le temps justifiant à la demande interne ou externe d’un potentiel sur ou sous facturation. Elle permet également dans l’application de la bonne licence Microsoft O365 de publier le modèle et donc de partager l’information à d’autres collaborateurs en temps réel.
Certains filtres restent toutefois à adapter selon ce que nous souhaitons afficher ou interpréter. Pour le reste, je vous laisse regarder les différents chevaux de mon carrousel ci-haut.
Comme pour l’article précédent, je pense faire une vidéo de démonstration (que je n’ai pas fait pour l’instant d’ailleurs. Non pas par fénéantise. Mais par épuisement moral. Il faut que je pense à Rosetta, à ressources humaines… Bref, je suis content de ce que j’ai rendu et accouché. Toutefois, il reste encore un peu d’ajustement. Dommage que cela ne puisse être utilisé au quotidien dans ma profession et ce pour des sujets de droit à la propriété intellectuelle.
A ce moment précis de mon second break, il se passe huit mois entre le début des première ligne de code et la fin de rédaction de cet article. Il me fallait terminer ce projet qui je le pense ne doit pas finir aux oubliettes. J’aimerai qu’il puisse à terme rendre service à d’autres SysAdmins et s’adapter à d’autres systèmes, socles de virtualisation.
Sources
- TLS : Transport Layer Security ↩︎
- ODBC : Open Database Connectivity ↩︎
- DB : Database ↩︎
- VCSA : VMware System Appliance ↩︎
- API : Application Programming Interface ↩︎
- SMTP : Simple Mail Transport Protocol ↩︎
- LD : Liste Distribuée ↩︎
- BAL : Boite aux lettres ↩︎
- FQDN : Fully Qualified Domain Name ↩︎
- gMSA : Group Managed Service Accounts ↩︎
- DVS : Distributed Virtuals Switchs ↩︎