PROJET – ITOP, MARIADB & DUMP
Il était une fois, un vendredi 22 février 2019, un jeune responsable informatique qui a décidé de réaliser un changement en production. Jusque-là, les conditions étaient favorables à cette veille de week-end. La semaine ne s’était pas si mal passée, les prémices des premiers rayons de soleil de printemps baignaient l’openspace d’une douce lumière, l’ambiance était chaleureuse.
Mon binôme et moi-même rigolions à quelques blagues potaches de ma part. Tout allait bien. J’enchainais dans notre solution ITSM1 les requêtes SQL2/OQL3 avec des gros mots comme DROP, DROP CASCADE. (Vous le voyez le drame qui arrive ? Iceberg droit devant !
Attention spoiler, ça ne va pas se terminer avec l’anneau dans le volcan !).
Un collègue passe m’avertir qu’il ne peut plus traiter de ticket. Je me souviens lui avoir répondu avec un aplomb digne d’un politicien que c’était normal. Pourquoi s’arrêter en si bon chemin dans l’exécution de mes requêtes, il n’y a pas de message d’erreur ? Tant que je gagne je joue ! xD
J’ai un peu moins rigolé quand deux minutes montre en main le responsable du centre de service m’a indiqué que s’il y a quelques minutes nos collègues ne pouvaient plus s’assigner de ticket, cette fois si, ils n’existaient même plus et ne pouvaient plus sélectionner leur nom sur l’interface WEBUI4.
Pour vous résumer mon état :
Si ça en a le gout, la texture et l’odeur. C’est que s’en est !
Ce n’est pas de moi, mais l’auteur je l’espère se reconnaitra
Avant de poursuivre ce conte digne des frères GRIMM, je souhaite dans cet article vous faire part d’une situation particulière à la limite du critique, de la réflexion pour corriger cette situation et des solutions pour se prémunir d’une potentielle récidive. Chassez le naturel, il revient au goulot…
Prérequis
- SE: RHEL, DEBIAN, UBUNTU
- Apps: bash, crontab, Mariadb/Mysql
- Autres: Au moins une base de données, Apps – MUTT
(Reprise de l’histoire)
Effectivement, j’ai bien « défoncé » quelques tables et jointures. L’application ITSM colonne vertébrale de notre organisation n’est plus fonctionnel. Il est 15h00 et l’ensemble des équipes sont à l’arrêt. Paradoxalement, j’aurai dû continuer de passer des requêtes SQLs car si nous ne pouvions pas traiter les demandes et incidents des utilisateurs, ces derniers pouvaient créer des tickets.
A ce moment, nous avions bien identifié l’origine du dysfonctionnement (1m98, 85 kilos… oui mais pas que). Nous envisagions mes collègues et moi une once d’espoir pour faire machine arrière quant à mes actions sur la base de données.
C’est un peu plus difficile quand j’ai annoncé ne pas avoir noté toutes les requêtes que j’avais exécuté, et que les journaux de logs sont vides.
Pourtant, personne ne doit travailler le vendredi après midi, le vendredi après midi on est bleu. La décision est prise. Il va falloir restaurer la base de données.
Réunion de crise
Récapitulons donc la situation, la production est hors service. Nous ne pouvons pas revenir en arrière, la production continue de tourner et à cette époque nous avions un fonctionnement particulier avec l’un des nos clients pour lequel notre outil ITSM était « master » d’un seconde instance ITSM satellite « slave » avec des synchronisations. Bref, un truc super mais sensible en cas de non respect du cycle de vie des tickets.
En dehors du cas singulier précédent, il faut savoir que dans le fonctionnement de notre organisation, nous avons des engagements de résultats sur le traitements des demandes et incidents (SLA5, OLA6, SLR7 etc).
Revenir en arrière en restaurant la base de données, oui mais sans perdre les tickets et requêtes utilisateurs en cours.
A quelle heure pouvons nous donc restaurer la BDD ? Encore une fois c’est là où le bât blesse. Nous n’avons pas de dump de la base… (Nous voici donc au volant d’une voiture qui roule à vive allure, nous pensons que tout va bien puis que d’un coup nous découvrons que l’assurance n’est pas à jour. Que l’ensemble des témoins du tableau de bord s’allument tous comme un sapin de Noël et que les freins vont surement lâchés.)
Nous décidons de contacter l’éditeur qui malheureusement ne peut rien faire pour nous dans le contexte et arrive à la même conclusion que nous. La restauration en date de la veille et inéluctable.
Nous réalisons toutefois un export de l’ensemble de toutes les requêtes créés, modifiées entre le matin même de 06h00 à 18h00 sur l’environnement ITSM de production ainsi que sur l’environnement ITSM satellite du client, puis coupons les services. De mémoire, cela représentait un volume de 300 tickets environ.
Excès de confiance
Pourquoi cette situation ? Pourquoi ce changement n’a-t-il pas été soumis à un CAB ? Si vous avez pris un peu le temps de lire d’autres articles ou de lire ma présentation, je suis quelqu’un de malchanceux marqué du signe du chat noir ascendant Pierre RICHARD (mais je le vis bien je vous rassure). Nous avions initialement mon collègue et moi pour objectif « d’alléger » notre base de données de production. C’est pourquoi, dans le cadre du contrat de support et d’assistance avec l’éditeur, après une analyse commune, nous avions établit une liste de requête précise.
Toutefois et par prudence, il était impératif de tester sur notre environnement de test/préproduction à ISO périmètre de l’environnement de production les dites requêtes. Chose qui a été réalisé par mes soins sans rencontrer la moindre complication ou dysfonctionnement. Le résultat est positif, tous les voyants sont verts. Pourquoi ne pas appliquer les modifications sur l’environnement de production ?
C’est là, que ça ne va pas. L’environnement de préproduction ne fonctionne pas à ISO périmètre de l’environnement de production. Ce dernier est sans cesse sollicité se qui n’est pas le cas de l’environnement de préprod. (C’est diabolique). Et donc, l’application des requêtes ont générés d’autres erreurs. L’outil ITSM m’a gentiment proposé de corriger les dîtes erreurs. Je suis donc sortie allégrement du contexte de mon changement sans m’en rendre compte.
Je pensais maitriser mes actions et n’ais à aucun moment pensé qu’il s’agissait d’un changement ! Il a suffit d’un excès de confiance. Pour mettre à genoux l’organisation (rien de bien dramatique en soi quand nous voyons aujourd’hui l’impact d’un crypto, ce n’est pas du tout le même impact).
Mais vous savez même si la chat et noir, il a toujours quelques poils blancs dans son pelage 🙂 L’incident tombant un vendredi, il nous reste le week-end pour trouver une solution.
Plan d’actions
C’est incroyable de se dire que l’action d’un individu à impacté l’ensemble des services et nécessité cinq collaborateurs de trois services différents. Néanmoins, personnes n’a été malveillant à mon égard à ma grande surprise. Nous étions une équipe face, un bloc face à l’incident en cours.
Nous avions donc défini le plan d’action suivant :
- Restauration du serveur de base de donnée à la veille dans un environnement isolé
- Réalisation du dump de la base de données
- Exportation de la base de données
- Désactivation de l’appareillage entre l’ITOP master et le satellite (slave)
- Importation de la base de données sur l’environnement de production
- Réalisation des mêmes actions côté ITOP satellite
- Réactivation de l’appareillage entre les deux ITOP
- Reprise des requêtes côté satellite depuis le fichier CSV exporté plus tôt
- Reprise des requêtes côté master depuis le fichier CSV exporté plus tôt
Sur le papier cela sonnait bien. Et pourtant encore nous allions buter sur deux points bêtes. C’est toujours quand nous sommes dans l’embarras (pour ne pas dire dans la m***e) que nous nous rendons compte de la réalité des choses.
- A l’époque, dans une console VMWare (version 5.5 de mémoire) il était ardu de taper certains caractères spécifiques. Nous avons buter pendant 30 minutes pour saisir le caractère « @« .
- Lors de l’import d’un dump existant ITOP, lors de l’application d’un setup il est nécessaire de supprimer l’intégralité d’une table VIEWS. Nous ne le savions pas à l’époque… (J’ai dans mes tablettes un article en cours à ce propos). Nous ne sommes pas SysDBA, mais nous avons tout de même réalisé le STATMENT qui va bien. (Malgré tous ces péripéties, ils t’ont laissé faire du SQL ? Non je vous rassure j’étais sous tutelle 🙂 ).
Reprise des données
La diversité des tickets et les différents paramètres des ces derniers allaient rendre difficile l’automatisation de réimport des requêtes. Il ne suffit pas de reprendre les tickets, il est nécessaire de leurs appliquer un « stimulus » afin que les notifications, SLA, le cycle de vie etc s’appliquent. L’éditeur nous avait prévenu quelques heures auparavant qu’il allait falloir user d’huile de coude.
J’ai eu à cœur d’assumer ma faute et de porter la responsabilité de cet échec. Si mon binôme n’était pas disponible samedi pour m’aider il l’était dimanche. Toutefois, j’ai fait tout ce qui était possible pour qu’il n’ait rien à faire.
Sur les 300 et quelques tickets, il aura dû en traiter une vingtaine et c’est je crois toujours 20 de trop. A grand coup de copier/coller, 270 tickets il faut compter à peu près 19h. (J’ai oublié de préciser que ma femme m’a mis un savon le soir comme quoi il est interdit de faire des changements le vendredi, blablabla. J’ai encore le souvenir de la voir partir le samedi soir avec ces copines et revenir tôt le dimanche matin. Ca fait ne me rajeunit pas).
Dénouement et fin
Le lundi matin, tout était de nouveau fonctionnel. Le week-end a été long et les heures de sommeil rares. Toutefois, « la bêtise » était assumée. Un nombre incalculable de « Je suis désolé », « Veuillez accepter mes excuses » auprès de mes collègues ont eu lieu. Il me semble que cela les a plus agacé que l’incident en lui même. (Effectivement le gars qui se là joue Les 120 journées de Sodome c’est usant).
Le plus beau, restera qu’aucun de nos clients n’a remarqué l’incident et le changement des SLAs de quelques heures. Si quelques interlocuteurs clients l’ont remarqués ils n’ont pas demandés plus de compte que cela.
Un REX8 a eu lieu en comité et nous avons su pointer les points qui devaient être améliorer. Le plus gros étant de s’assurer au moins un dump de la base de données entre deux points de sauvegarde. Oui mais comment faire et surtout par où commencer.
Réflexion
A la suite de la petite histoire ci-haut, qui commence mal mais qui se termine plutôt bien. L’une des premières questions que je me suis posé est qu’est ce que propose ITOP ? Est ce que la solution embarque un système de sauvegarde, de dump de base de données ?
La réponse est oui ! Mais ça ne me convient pas !
Mais il est jamais content se type. Il y a des solutions mises en place par l’éditeur dans sa solution et ça ne lui convient pas. Je le vois déjà écrire « Oui je veux pas réinventer la roue, mais… ». Tu serais pas un SysAdmin frustré par hasard ? Qu’est ce qui a ?
Pour le coup le contexte est différent. Si nous reprenons l’architecture 2-tiers (Apps – iTOP), nous avons d’un côté notre serveur web et de l’autre notre serveur de BDD. Jusque là pas de problème.
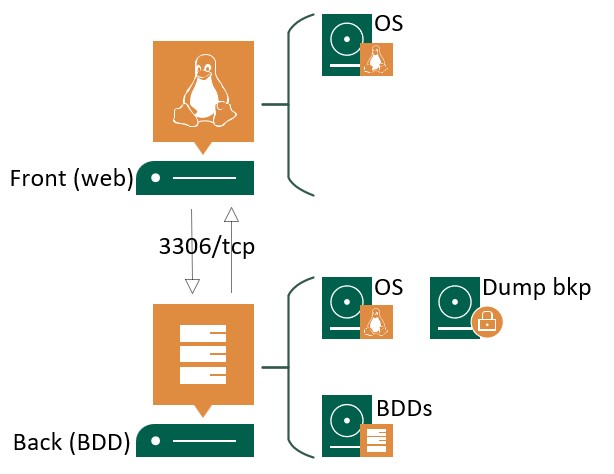
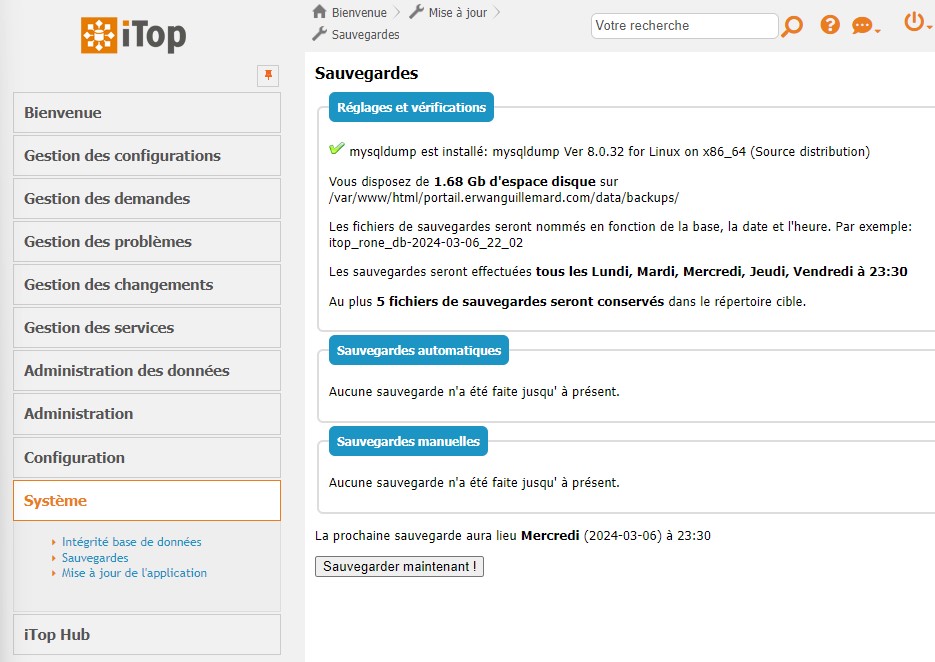
Ce qui me gène dans l’outil mise à disposition pour COMBODO, c’est que le stockage des dumps se fait du côté où est exécuter la commande mysqldump. Soit côté Front et donc stocké dans le répertoire web itop (/var/www/html/portail.erwanguillemard.com/data/backups/).
En quoi ça te gène ? En réalité il y a plusieurs points.
- Espace disque : Il existe un risque de saturation de l’espace de stockage du serveur web et de la partition /var/. La saturation de la partition (ou du disque) peut (plutôt va) rendre inaccessible le portail web. (Tu connais les hardlinks ?)
- Sécurité : Stocker les dumps de la base de données de production sur le serveur front publié vers l’extérieur représente un risque en cas d’intrusion donc de vulnérabilité et de vol de données dans le pire des cas
- Granularité : Possible uniquement de ne garder que 5 points de rétentions du lundi au vendredi à partir de 23:30.
- Mécanisme : Ce dernier est propre à ITOP est non pas une couche hors de l’application. Que se passe-t-il si le front reboot lors de la tâche de backup ou si le réseau est indisponible, si l’application est indisponible ?
Donc si nous te comprenons bien, la fonctionnalité est naze ? Non, loin de là. Au contraire, je trouve que c’est une excellente fonctionnalité car elle permet pour les petites bases de données de réaliser un dump dans les meilleurs délais et de ne pas avoir à se connecter directement au serveur backend. De plus, il est possible de réaliser une restauration directement depuis le portail ITOP (webui).
C’est à partir de ce constat que j’ai décidé d’écrire ma lettre au Père Noël (ou Saint Nicolas suivant notre situation géographique).
Petit Papa Noël,
J'ai été bien sage en ce début d'année 2019 même si j'ai fait une petite boulette. Afin de ne pas reproduire cette bêtise, je souhaiterai avoir une solution qui réalise les points suivants :
* Un outil qui réalise 2 dumps par jour ou plus (automatisation)
* Un outil qui envoi un mail en cas de succès ou d'erreur du dump
* Un outil qui puisse avoir une fonctionnalité de dump manuel
* Un outil qui soit GENERIQUE et s'adapte à n'importe quelle base de données MySQL/MariaDB.
* Un outil qui fonctionne sous GNU (RHEL et DEBIAN) en bash.
Merci Père Noël, je t'aime tu es le meilleur.
Bisous,
ErwanHélas, je n’ai toujours pas eu de réponse à ma lettre. A croire que ma « boulette » n’était pas si petite que ça… Ce n’est pas grave…
Allez, on est pas des manches, on se relève les manches et… BANZAÏ !
Merci Groland
Configuration et installation du Script
Bien qu’initialement, l’outil que j’ai développé venait répondre à un besoin professionnel, la version présentée dans cette article a pour seul lien que le contexte et a été développé, testé sur mon temps personnel.
Lecture du script
Comme toujours nous positionnerons le script à la racine du système de notre serveur SGBD dans un répertoire à part avec des droits spécifiques. L’objectif étant de toujours garantir un niveau de sécurité suffisant et d’éviter une escalade potentielle des droits.
J’insiste sur ce point, l’ensemble des actions ci-dessous sont à réaliser sur le serveur backend.
$ sudo mkdir /script
$ sudo mkdir /script/SS_015-LINUX_MYSQL_DUMP-BDDEditez le fichier ou copiez le fichier suivant : SS_015_E_LINUX_MYSQL_DUMP-BDD.sh
A ce jour le fichier en version E est construit de la manière suivante :
- Les constantes
- Une fonction vérifiant les prérequis
- Une fonction réalisant le dump de la base de données
- Une fonction assurant la rotation des fichiers de dumps suivant le nombre de points de rétention définit
- Une fonction pour préparer le mail
- Une fonction d’envoi de mail
- Une fonction pour forger le mail en html
Je vous propose de parcourir ensemble le script, fonction par fonction. L’objectif étant de partager ce bout de code et peut être pouvoir le soir me coucher en me persuadant que quelques parts, sur le SI d’une organisation ce bout de code, maigre contribution personnel fonctionne… Laissez moi un peu rêver ou alors dites vous que vous m’en vendez (du rêve naturellement) !
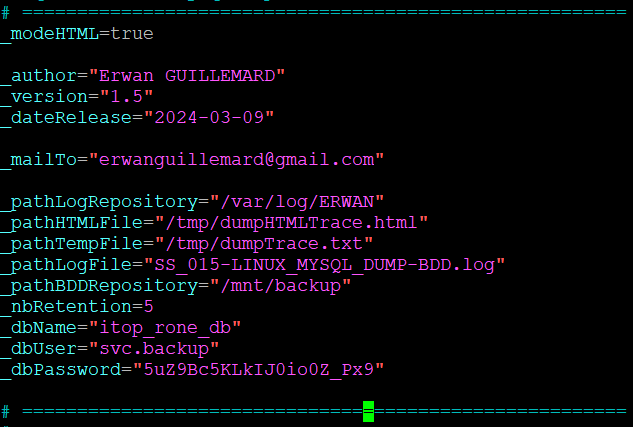
Les noms des variables sont normalement explicites. Pour éviter toutes ambiguïtés :
- _modeHTML : Pour avoir des bô rapport en HTML
- _author : Pour afficher dans le rapport le nom du créateur
- _version : Pour la version du script
- _dateRelease : Pour la date du script (dernière modification)
- _mailTo : Contient l’email du destinataire qui va être spamé de mail
- _pathLogRepository : Emplacement où seront stockés les logs à chaque exécution du script.
- _pathLogFile : Nom du fichier de log
- _pathBDDRepository : Emplacement où seront stockées les dumps
- _nbRetention : Nombre de dump à conserver
- _dbName : Nom de la base de données concerné par le traitement
- _dbUser : Nom du compte Mariadb/MySQL qui sera autorisée à réaliser le dump de la BDD
- _dbPassword : Mot de passe du compte renseigné précédemment
Cette fonction à pour objectif de vérifier et de contrôler que toutes les conditions nécessaires au bon déroulement du script soient présentes.
- Création du répertoire de log si absent
- Création du fichier de log si absent ou différent
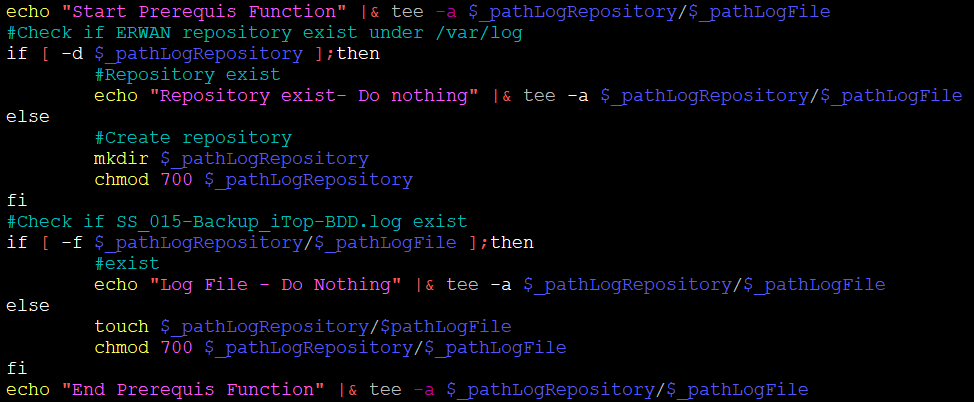
- Création du répertoire des dumps 1/2 et 2/2 journalier

Si et seulement si les conditions sont présentes alors le script fera appel à la fonction suivante dumpCreate.
« J’ai une question bête ? C’est quoi ta variable $codeArg et la commande tee ? »
Il est important de se rappeler « il n’y a pas de question bête, il n’y a que des réponses stupides« .
Lorsque j’ai écrit ce bout de code il y a 4 ans, je souhaitais offrir la possibilité de réaliser l’automatisation des dumps mais de garder la possibilité de lancer manuellement un dump sans à avoir à taper la commande mysqldump, le login et le mot de passe.
De ce fait, si nous appelons le script :
- Sans argument : Réalise un dump de la base de données à l’instant T
- Avec argument (MidDay ou MidNight) : Réalise un dump de la base de données dans un répertoire spécifique. A son intérêt si appelé dans une tâche planifiée.
La commande tee offre un avantage car elle permet de retourner l’affichage d’un terminal dans un fichier. Ce qui permet de voir ce qui se passe lors de l’exécution du script et de garder une trace de l’ensemble des actions. D’un côté cela reste plus lourd dans la syntaxe que le traditionnel 2>&1 qui ne gère que le stdout et stderr. Probablement qu’aujourd’hui je ferai différemment.
Nous rentrons dans le vif du sujet. Je réalise le dump de la base en deux temps.
- Export du dump .sql
- Compression du dump .sql en .gzip
Toujours en prenant en compte l’argument passé lors de l’appel du script pour positionner le dump dans le bon répertoire. Dans le cas contraire, le dump sera écrit à la racine du répertoire contenant les dumps.
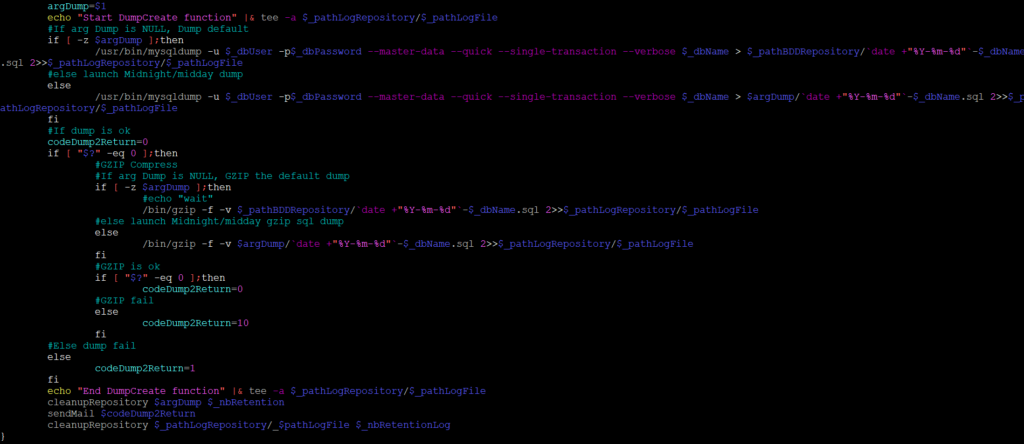
Dans cette fonction, les commandes les plus intéressantes sont bien entendu les commandes mysqldump et gzip.
Pourquoi faire en deux temps alors qu’il est tout à fait possible de réaliser ces deux actions en une seule commande ?
Excellente question pour laquelle je ne me souviens plus pourquoi j’ai fait ça. Peut-être pour le plaisir de chercher midi à quatorze heures que sait où mon côté néophyte ?

Nous précisons l’utilisateur qui va réaliser le dump de la BDD (attention au permission sur la base) ainsi que son mot de passe -u $_dbUser et -p$_dbPassword. L’option –master-data permet de se positionner si une réplication SQL est se place sur la dernière position. L’option –quick est utile dans le cas de BDDs importante. Cela va permettre de récupérer les lignes d’une table, ligne par ligne, plutôt que de récupérer l’intégralité de toutes les lignes et de les garder en mémoire avant de l’écrire. L’option –single-transaction qui est à mon sens l’option la plus importante de notre ligne de commande puisque cette option permet de réaliser le dump de notre base de données à chaud sans verrouiller les tables ni bloquer l’application. Pour faire plus simple, cela permet de garantir la consistance des données de notre DUMP. L’option –verbose est quant à elle compréhensible. Nous indiquons la BDD dont nous souhaitons réaliser le dump $_dbName, redirigeons l’ensemble des flux dans le répertoire adéquate puis l’ensemble des flux dans notre fichier de log.

La compression est plus simple puisque nous appelons la commande gzip en indiquant que nous voulons de la verbe et que nous allons forcer la création de l’archive. Comme pour la commande précédente, nous redirigerons l’ensemble des flux dans notre fichier de log.
Et donc si nous souhaitons faire cette opération en une fois ?
Il suffirait de faire un pipe des deux commandes.
$ sudo /usr/bin/mysqldump -u $_dbUser -p$_dbPassword --master-data --quick --single-transaction --verbose $_dbName > $argDump/`date +"%Y-%m-%d"`-$_dbName.sql 2>>$_pathLogRepository/$_pathLogFile | /bin/gzip -f -v $_pathBDDRepository/`date +"%Y-%m-%d"`-$_dbName.sql 2>>$_pathLogRepository/$_pathLogFileJe ne l’ai toutefois pas testé. Donc à vérifier, mais il n’y devrait pas avoir de raison que ça ne fonctionne pas.
Il y a toutefois une variation entre le commande présente dans le wiki de COMBODO et ma commande. Je ne précise pas les arguments –opt, –default-character-set=utf8, –-add-drop-database. Pourquoi cette prise de liberté soudaine ?
L’option –opt est activé par défaut et si nous ne référons au manuel mysqldump, cette commande est un raccourcie de plusieurs autres commandes. Dans notre cas et si l’installation de MySQL/MariaDB a été effectué comme dans un précédent article , la question ne se pose pas. A l’inverse, nous ne spécifions pas l’encodage des caractères –-default-character-set. Cela pourrait nous porter préjudice. Néanmoins et par défaut si ce dernier n’est pas spécifier, mysqldump utilisera le type utf8mb4. On ne va pas se mentir, je ne suis pas super à l’aise sur le sujet. Si ce n’est que l’utf8mb4 est plus récent que le format utf8 et prend en charge les emojis etc. Par expérience, tous les dumps que j’ai dû réimporter jusqu’à présent ont été réalisé sans spécifier le type d’encodage utf8. Je n’ai pas constaté d’erreurs ou de dysfonctionnements. Moralité, je vais me mettre au diapason. (D’un côté faut être un peu c*n pour dire j’ai RTFM mais j’ai pas appliqué les recommandations de l’éditeur…).
Je vois déjà certains SysAdmins ou Dev se dire « Nan le gazié il est pas sérieux avec son _nbRetention, il a pas osé faire une fonction de rotation de ces fichiers .sql/.gzip ?! » Et bien désolé de vous décevoir, la réponse est bien un énorme OUI, j’ai osé.
Pourquoi ? Simplement pour me demander comment ferai je si je devais me passer de logrotate. Et le cas échéant, j’ai appris quelques choses d’autres et j’ai donc un as dans ma manche si je dois faire une rotation de fichier un jour sans logrotate.
(Comme déjà dit plusieurs fois, il est important de savoir se perdre de temps en temps.)
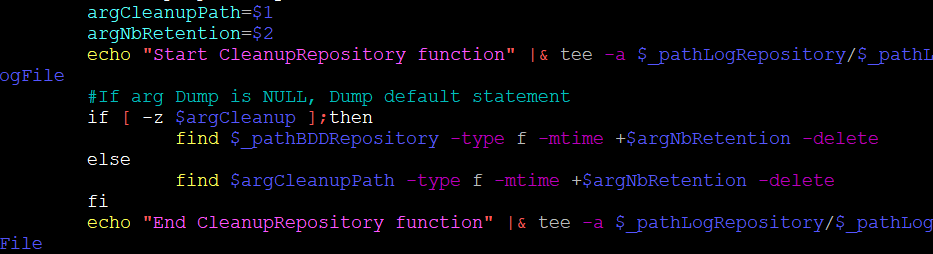
La commande find permet de lister l’ensemble des éléments sur un critère. Dans notre usage, nous souhaitons lister tous les éléments (fichiers réguliers) d’un des répertoires contenant nos Dumps -type f dont la dernière modification est inférieurs au nombre de point de rétention -mtime +$argNbRetention. (Notons que cela s’exprime en jour donc 5 x 24heures). Les fichiers ne répondant pas au critère sont supprimés -delete.
Je passe mon tour sur les trois dernières fonctions qui sont ennuyeuse au possible et qui pour moi n’apportent aucun intérêt dans le projet. Puisque cela concerne l’envoi d’un mail de notification de succès ou d’échec de l’archivage ou de la réalisation du dump.
Qui dit notification mail, dit serveur de messagerie (Apps – MUTT).
Nous contrôlons les droits sur le fichier afin de s’assurer que ce dernier est bien en 700 pour root:root.
$ sudo ls -ahl /script/SS_015-LINUX_MYSQL_DUMP-BDDDans le cas contraire, il sera nécessaire de réaliser les opérations adéquates.
Configuration du cron
Perso, je souhaite avoir un delta de 6 heures maximum en cas de panne et donc (attention largage de gros mots dans deux secondes) dans RTO9 de 1 heure ! Généralement, les entreprises travaillant de 8h00 à 18h00 du Lundi au Vendredi, nous allons automatiser nos dumps à 12h30 et à 18h30 sur les mêmes jours. Libre à chacun de faire comme il le souhaite. (Attention toutefois si vous avez des jobs de sauvegardes en parallèle des dumps car les SEs n’aiment pas ça, ni le matériel d’ailleurs les I/O10 un univers passionnant).
# vim /etc/crontab
Ainsi, chaque Lundi au Vendredi à 12h30 en tant que root, le script stocké sous /script/SS_015-LINUX_MYSQL_DUMP-BDD/SS_015_E_LINUX_MYSQL_DUMP-BDD.sh avec l’argument MidDay viendra générer un dump de la base de données compressée sous l’emplacement de stockage par défaut /midday/. Il sera de même à 18h30 mais avec l’argument MidNight, sous l’emplacement /midgnight/.
Configuration des logs
Si vous avez déjà déployé l’un de mes outils, vous devez déjà avoir la configuration de rotation des logs pour le contenu du répertoire /var/log/ERWAN.
Dans le cas contraire, éditez un fichier de rotation.
$ sudo vim /etc/logrotate.d/rone_scripts/var/log/ERWAN/SS_015-LINUX_MYSQL_DUMP-BDD.log {
daily
rotate 7
copytruncate
missingok
notifempty
}
Configuration de la BDD
Euh… Je veux bien que tu parles de backup, de dump, de SQL toussa toussa. Mais qu’est ce que vient faire la configuration de la BDD dans cet article ?
Je répondrai à cette question par une question me chuchote mon avocat.
On lance le dump avec quel compte, le root ?
Effectivement, vu sous cette angle c’est moche. Qui peut le plus peut le moins. Mais le risque est de ne pas exposer d’avantage notre système et de maitriser autant que faire se peu les utilisateurs et les privilèges qui leurs sont associés.
Alors nous allons créer un compte dédié pour la sauvegarde de nos bases MariaDB/MySQL. (D’ailleurs saviez vous que le Dauphin de MySQL est une dédicace à la fille ainée de son fondateur et qu’à la suite de son rachat par SUN puis ORACLE, il dédiera l’Otarie à sa fille cadette ? Non ? Et bien voilà, nous mourrons moins c*n ce soir).
# mysql -u root -p[(none)]> CREATE USER `svc.backup`@'localhost' IDENTIFIED BY '5uZ9Bc5KLkIJ0io0Z_Px9';
[(none)]> GRANT LOCK TABLES, SELECT, PROCESS, SHOW VIEW, TRIGGER ON *.* TO 'svc.backup'@'localhost';
[(none)]> FLUSH PRIVILEGES;

Dans les grandes lignes, nous créons notre utilisateur SQL (on pense à changer éventuellement le nom du user et le mot de passe), rien de bien compliqué. Ce qui nous intéresse en revanche se sont les permissions que nous attribuons à notre utilisateur :
- LOCK TABLES : Parce que nous utilisons l’argument single-transaction pour la consistance de la BDD
- SELECT : Pour dump les tables
- PROCESS : Dans le cas où nous viendrions à utiliser l’argument no-tablespaces. Dans notre cas pratique, inutile mais peut-être pas pour d’autres BDDs.
- TRIGGER : Pour dumps les tables TRIGGER de notre BDDs. Comme pour l’option ci-dessous, ça serait dommage de ne sauvegarder qu’un bout de notre BDD. Ca serait comme faire une soirée raclette mais en ne touchant pas au plateau de charcuterie. Aucun intérêt de faire une soirée raclette/dump.
- SHOW VIEW : Pour sauvegarder la table des VIEWS. Dans notre cas, nous les supprimerons si nous devons réaliser un dump de la BDD iTop. Toutefois, nous voulons un backup complet en cas d’avarie.
Allez, fermons notre connexion SQL et passons à l’étape suivante. La princesse Peach nous attend, à moins que ce ne soit Peggy du Muppet Show. Je les confonds toutes les deux.
Configuration du script
Il sera nécessaire avant la configuration du script de dédié un disque pour nos dumps (comme indiqué plus haut). L’une des grandes questions étant oui mais comment définir l’espace de stockage afin de ne pas faire de surallocation de ressources ?
Il est toujours difficile d’apporter une réponse empirique à cette question. J’ai pour habitude de partir sur la formule suivante :
DiskSize (Go) = (BDDSize (Go) * AVG Compression Rate * NBRetentionPoints) * 30 %
Par exemple, si nous partons des données suivantes pour un total de deux jobs automatisés par jour sur 5 jours avec un taux de compressions de 46% et que notre BDD fait 2 Go :
DiskSize (Go) = (2 Go * 0,46 * (2*5)) * 1,3
DiskSize (Go) = 11,96 Go
Il nous faudrait donc un disque dédié de 12 Go. Nous avons prévu une marge de 30% d’espace de stockage afin de ne pas avoir d’alerte relative à notre supervision et saturer notre espace disque. Nous n’avons ainsi pas la nécessité d’étendre tous les deux jours ou quatre matins notre partition.
Attention à l’évolution de notre base de données dans le temps. Si cette dernière « gonfle » rapidement, il sera nécessaire d’engager les actions adéquates.
Optionnellement, si vous réalisez une sauvegarde de votre machine (ce qui est vivement recommandé) par une solution tierce (VEEAM, HYCU etc) vous aurez votre nombre de point de rétention de sauvegarde en dump plus votre notre de point de rétention max définit dans notre script. Cela nous fait une bonne assurance.
Pour la suite, je considère donc que nous avons monté un disque de 12 Go sous /mnt/backup/.
Les droits sur le répertoire /mnt/backup doivent être 700 pour l’utilisateur root:root. N’oublions pas qu’en dehors de la sauvegarde, nous avons un autre backup de notre BDD. Il est donc logique de ne faire confiance à personne d’autre que root.

Editons notre script et modifions les variables suivantes.
$ sudo vim /script/SS_015-LINUX_MYSQL_DUMP-BDD/SS_015_E_LINUX_MYSQL_DUMP-BDD.sh- _mailTo : préciser l’adresse qui va recevoir les rapports de dump deux fois par jour.
- _pathBDDRepository : préciser le répertoire racine créé précédemment qui va contenir nos sauvegardes /mnt/backup.
- _nbRetention : Le nombre de point que vous avez définit dans notre formule. Vous pouvez l’augmenter ce dernier ou le diminuer à votre guise. Tant que l’espace de stockage arrive à suivre, pas de problème.
- _dbName : Le nom de la database dont nous voulons réaliser le dump.
- _dbUser : Le compte SQL dédié uniquement à la réalisation des dumps.
- _dbPassword : Le mot de passe du compte SQL ci-haut.
Et le reste, pas touche, sauvegarder les modifications.
Bon, plus qu’à tester.
Test, Let’s the Rock of Begins
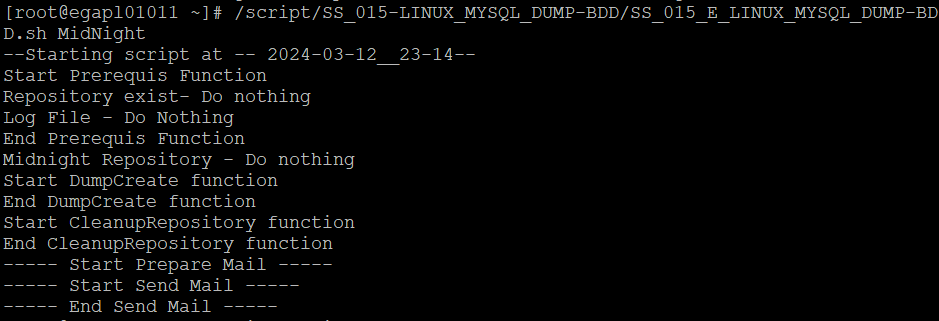
Afin de vérifier que tout va bien nous allons exécuter un dump manuellement et simuler l’automatisation d’un dump.
# /script/SS_015-LINUX_MYSQL_DUMP-BDD/SS_015_E_LINUX_MYSQL_DUMP-BDD.sh
#/script/SS_015-LINUX_MYSQL_DUMP-BDD/SS_015_E_LINUX_MYSQL_DUMP-BDD.sh MidNight
Normalement si nous avons bien fait les choses, nous devrions avoir dans notre console le retour suivant :
Si nous laissons tourner notre script 24 heures, nous devrions avoir la structure suivante dans notre répertoire /mnt/backup
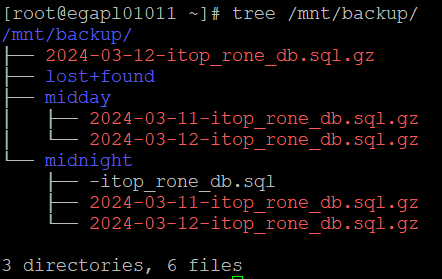
Nous pourrions supprimer un sous répertoire, ce dernier sera recréé lors de la prochaine exécution du script dans le contrôle des prérequis. 🙂
Au début, je voulais joindre en pj le fichier de log. Mais tant que nous n’avons pas une grosse BDDs ça passe, après c’est plus délicat. Je dois faire des efforts dans ce sens pour mieux gérer la verbosité de mes journaux je crois.
Néanmoins, nous pouvons faire une tour dans le répertoire de log et consulter l’ENSEMBLE de toutes les actions réalisées par le script.

Soit en petit échantillon.
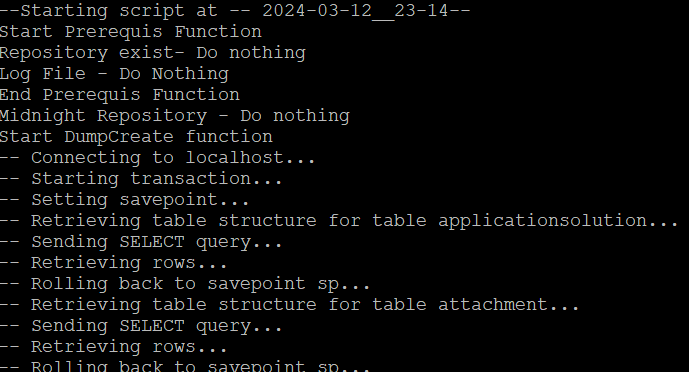 | 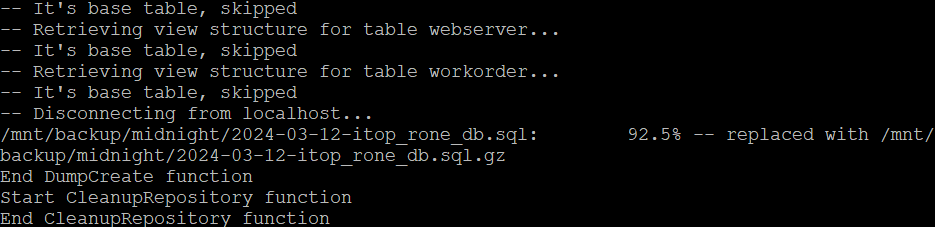 |
Et pour terminer, le plus important car nous ne sommes pas en permanence sur notre terminal putty, le petit mail nous informant du bon succès des opérations.
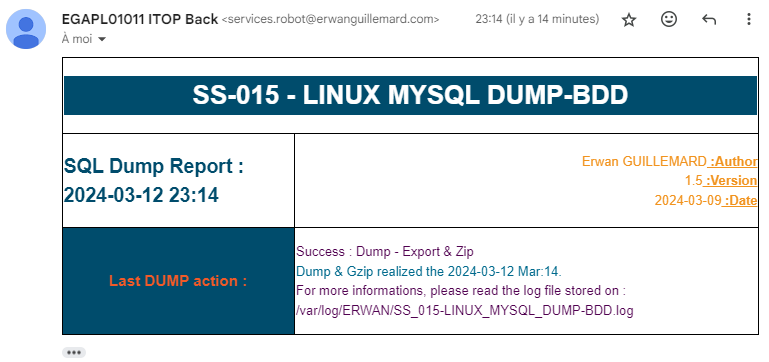
GitHub
Le code source ? C’est par là => LIEN (Licence GNU).
Conclusion
Il n’y a rien de pire que l’excès de confiance dans la profession d’AdminSys. A la différence des chirurgiens et autres médecins qui sont en dessus des divinités, l’AdminSys se voit vite revenir à la réalité. Je pense et s’est ce que mes mentors m’ont inculqués, peu importe la tâche nous devons être en permanence vigilant.
C’est avec ce genre de situation que nous prenons pleinement conscience des manquements sur nos systèmes d’informations et qu’il est nécessaire de trouver des solutions palliatives, payantes ou homemade (bancales la plus part du temps mais qui font ce que nous attendons).
Dans mon cas et pour revenir à la situation initiale, je pense avoir répondu à ma problématique d’indisponibilité des données entre deux points de sauvegarde (24h). Mais c’est encore loin d’être parfait. La solution est générique certes, mais elle pourrait tellement être optimisée, factorisée et simplifiée.
Pourtant nous ne sommes pas allés au bout de ce projet. Et j’avoue que j’étais partagé pour aborder ce point. Je traiterai ce dernier dans un autre billet. Mais ce que nous devons garder à l’esprit c’est que nous avons un dump de notre base de données SQL (que ce soit, ITOP, ZABBIX ou autres applications), qu’est ce qui nous dit que le contenu de notre dump est intègre et fiable ? Il faudrait réimporter ce dernier dans un environnement de test et recetter le dump. Ainsi la boucle serait bouclée et nous validerions notre processus de reprise de données à partir d’un dump de bout en bout. Cela viendra s’inscrire dans le PAS11 de notre application, organisation.
Le mot de la fin :
Il était une petite requête, pirouette cacahouète. Il était une petite requête qui a fait une grosse boulette.
Pirouette, pas de caouhète. Vous passez en week end studieux sans apéro…
Erwan GUILLEMARD
Source
- FIND
- GZIP
- ITOP – DataBackup (v3.X)
- ITOP – DataBackup (v2.7.X)
- MYSQLDUMP – master-data
- MYSQLDUMP – quick
- MYSQLDUMP – single-transaction
- MYSQLDUMP – minimum privileges
- TEE
- ITSM : Information Technology Service Management ↩︎
- SQL : Structured Query Language ↩︎
- OQL : Object Query Language ↩︎
- WEBUI : WEB User Interface ↩︎
- SLA : Service Level Agreement ↩︎
- OLA : Operational Level Agreement ↩︎
- SLR : Service Level Requirement ↩︎
- REX : Retour d’EXpérience ↩︎
- RTO : Recovery Time Objective (différent du RPO Recovey Point Objective) ↩︎
- I/O : Input / Output ↩︎
- PAS : Plan d’Assurance Sécurité ↩︎