PROJET – Green Ray, VEEAM Reporting Partie 2 : Pratique
C’est la première fois que je vais rédiger un bout d’article de la sorte. L’objectif étant de décrire l’installation et déploiement de la solution.
A quoi bon me direz vous si je ne donne pas accès à l’outil ? Ce à quoi je répondrai et si je décide de donner accès à ce dernier ? Il y a un petit effet UNO/CONTRE UNO <3
Au-delà de l’aspect, il s’agit surtout d’établir un mode opératoire différent du bon vieux README.txt, ou du moins faire en sorte d’avoir un MO1 qui a de la gueule.
Prérequis
Dernier point avant de taper dans le fond du sujet, le déploiement ne se fait que dans un environnement WINDOWS (Workstation ou Server) ayant au minimum la version Powershell 5 d’installer et qui prend en charge les communication TLS2 en version 1.2 minimum.
Bien que pas j’ai automatisé un bon nombre d’installation de dépendances certaines restent tout de même à déployer manuellement. Toutefois, les outils à déployer manuellement concernent la partie exploitation de la donnée qui peuvent et doivent être dissocier de la partie serveur.
Naturellement et bien que cela coule de source, LES PRIVILEGES ADMINISTRATEURS sont nécessaire au premier usage pour l’installation des dépendances (logique non ?).
Back End
Les prérequis sont les suivants :
- Module powershell PSSQLite : Ce dernier est déployé automatiquement par l’application. Toutefois, il est possible d’installer cette dernière manuellement.
La commande des plus classique, Get-InstalledModule pour lister les modules présents sur le système.
> Get-InstalledModule -Name PSSQLite
Toujours vérifier en amont la disponibilité du module dans la liste des repos et lancer l’installation. Il est possible de filtrer et d’installer une version spécifique.
> Find-Module -Name PSSQLite
> Install-Module -Name PSSQLite
Front End
Sur le serveur ou poste qui servira à exploiter les données il sera nécessaire d’installer les dépendances suivantes :
- Drivers ODBC3 for SQLite3
- Microsoft PowerBI (si powerBI utilisé)
- DB4 Browser for SQLite (en option mais pratique pour débugger ou altérer des données dans les tables)
L’installation des divers composants ne représente aucun point bloquant. J’ajoute en fin de ce billet les sources pour télécharger les différents composants. Pour vraiment prendre la main de chacun le processus d’installation est disponible ci-dessous.
L’un des points problématiques à mon sens se porte sur l’origine du site qui n’est pas en HTTPS. Mon expérience de jadis sur la technologie SQLite fait que j’ai dû utiliser ce site. Je n’ai jamais eu de problème.
Oui, j’ai du chercher dans les mémoires que j’avais rédigé à l’époque…
 |  |
 |  |
 |
Pas de difficulté en soi. Il est toutefois opportun de posséder un compte Microsoft…
 |  |
 |  |
 |  |
Toujours en mode enfonçage de porte…
 |  |
 |  |
 |  |
Configuration
Avant de lancer le script, il est nécessaire de faire un tour vers le fichier de configuration contenu dans le répertoire config à la racine du projet. Je vais prendre le temps de décrire chacune des parties de ce fichier.
Le fichier se découpe en 1 partie et 6 sous-parties.
| * Une sous-partie globale qui définit les paramètres du script et de son fonctionnement * Une sous-partie dédiée à la VSPC5 permettant d’établir la connexion à l’API6. * Une sous-partie dédiée à l’export des données au format CSV, reliquat de la version 1 LEGACY * Une sous-partie concernant l’envoie de notification SMTP7, futur feature/bug (rayer la mention inutile) à venir * Une sous-partie dédiée à la base de données SQLite. Faut bien stocker les données quelques parts * Une sous-partie concernant le paramétrage du mode service en tant que tâche planifiée |  |
Après cette longue énumération rébarbative, je pense que nous pouvons regarder en détail chacune des parties et sous-parties.
J’ai ajouté dans la solution la possibilité d’éditer le fichier directement depuis l’interface console. Par sécurité, j’ai ajouté une fonctionnalité de régénération automatique du fichier en cas de suppression ou de corruption. Hé oui, j’en ai eu marre de me repalucher le fichier de configuration plusieurs fois à la mano…
Avec la compréhension du fichier de configuration, je pense que nous pouvons passer à la suite, soit déployer l’application sur le serveur.
Installation
Dans l’idéal, j’aime à dédier un disque de 5Go pour l’application.
Pourquoi ? Encore cette traditionnelle question que nous enfant de 3 ans avons posés sans cesse à nos ainés et que nous subirons à notre tour plus tard que nous soyons ou non parent… J’en veux pour preuve séance tenante 🙂
Pour la bonne et simple raison que cela permet de dissocier de la partie système de l’application et également de se prémunir d’un dépassement de stockage comme nous avons une base de données.
Il suffit de déposer le répertoire à la racine du lecteur D:\ ou d’ailleurs puis de définir les paramètres du fichier de configuration. Et puis c’est tout. 🙂
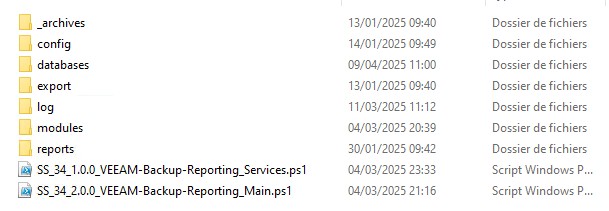
Lancer le script SS_34_2.0.0_VEEAM-Backup-Reporting_Main.ps1 pour réaliser les opérations d’initialisation et vérification des dépendances. On me chuchote dans l’oreillette qu’il faut faire un clic droit Exécuter avec Powershell (en tant Administrateur).
Si le mode DEBUG est activé et que la redirection des sorties dans un fichier de log également, nous devons avoir en amont les entrées ci-dessous (oui il y a des améliorations Hé Nanani Hé Nanana…).
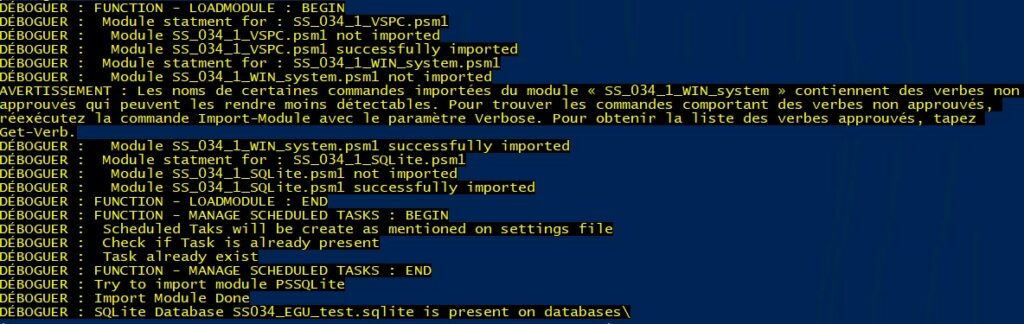
Ce qui est cool avec la partie rédaction c’est qu’à ce moment je me rends compte que je n’ai pas réalisé la mise à jour de l’interface CLI13… L’option pour lancer l’application se fait en appuyant sur la touche 7. Oui promis, je corrige l’interface prochainement 🙂

Là je suis honnête, il y a quelque chose que je ne comprends pas bien et je pense que cela est dû à un problème de contexte. Je m’explique.
| En exécutant le code directement dans une console, ce dernier retourne le résultat attendu sur le plan applicatif mais je n’ai pas de trace de débogage. A l’inverse, si j’exécute le même code dans la console ISE14 (après avoir saisie l’option 7 du menu contextuel, j’obtiens les sorties ci-contre. Rien de méchant en soit mais bon c’est moche… | 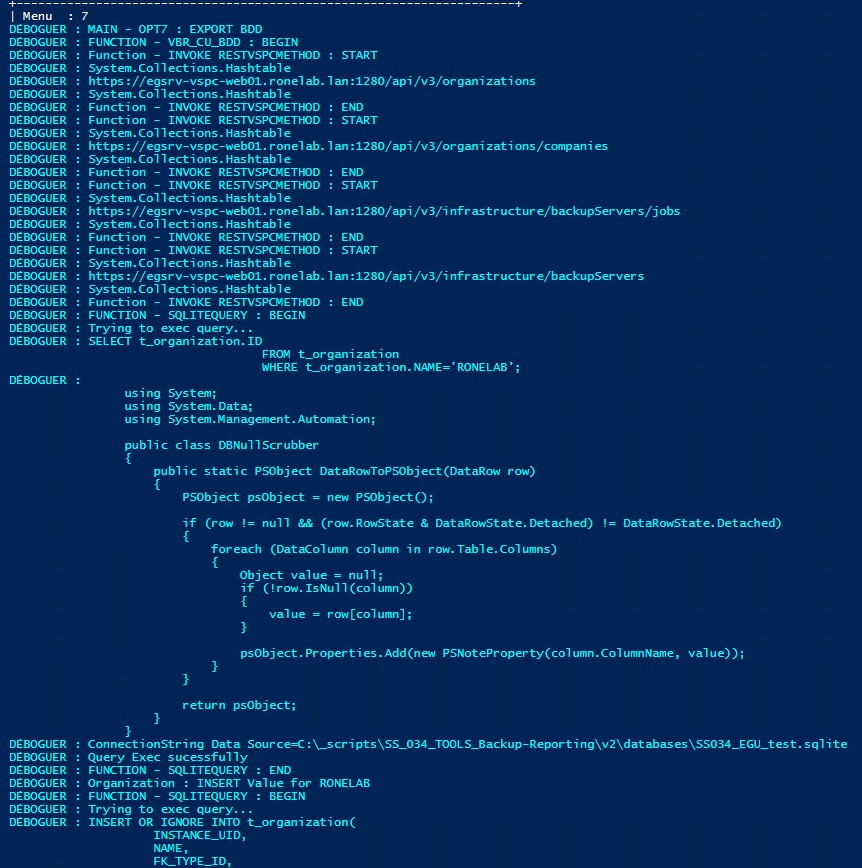 |
Nous avons donc lancer notre script pour la première fois, nous pouvons clôturer l’application en appuyant sur la touche 0.
Normalement et si l’ensemble des prérequis ont été réalisés, nous avons :
- Installé le module PSSQLite
- Déployé la tache planifiée avec le mode service
- Réalisé la première extraction de notre environnement VSPC et générer notre BDD
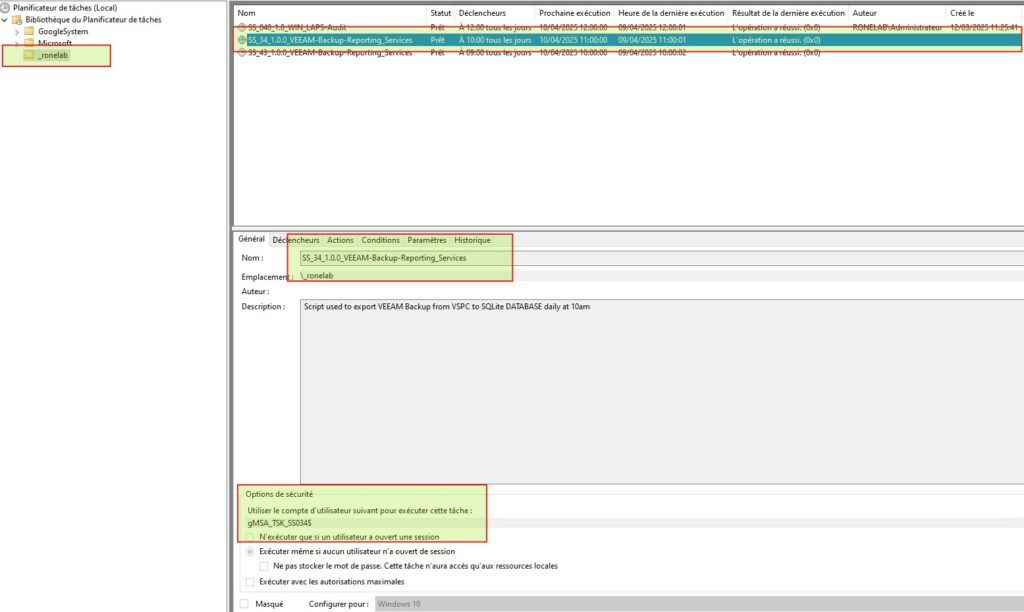
Il est possible que des erreurs remontent. Cela peut être dû à plusieurs possibilités qui nécessite un diagnostic. Toutefois, il est possible de corriger certains points. A l’avenir une Partie 4 KB serait intéressant à développer.
Bref, si la tâche planifiée branle de la cafetière vous pouvez modifier cette dernière ou bien la supprimer. Dans tous les cas et si les paramètres sont corrects dans le fichier de configuration, lors de la prochaine exécution manuelle du script la tâche sera recréée.
Il est possible lors de la connexion à la VSPC en API que le script retourne une erreur. Cette erreur est dû au certificat autosigné. Ce point est abordé dans l’article VSPC.
Exploitation des données, Reporting
Comme abordé dans la partie précédente, il est tout à fait possible de définir votre propre modèle de reporting en venant interroger la BDD SQLite.
- Excel
- Homade Web Apps
- PowerBI
- etc
Je vous jure que pour une fois, je me suis dit que j’allais me mettre au WEB pour requêter ma BDD. Puis finalement, ayant opté pour une BDD SQLite, j’ai vite constaté que mon seul petit être ne suffirait pas à tout gérer dans un temps raisonnable (plus de 400 heures sur le projet tout de même) c’est pourquoi je me suis tourné vers l’outil Microsoft PowerBI.
Je fournis un modèle déjà tout fait avec les liaisons inter-table (MLD15 si je ne dis pas de bêtise).

- En Bleu la partie dédiée à la gestion des Licences des produits VEEAM
- En Vert la partie dédiée à VEEAM Backup et Réplication
- En Orange la partie dédiée à VEEAM Backup For Microsoft O365
D’après l’un de mes proches amis dans le monde l’IT je suis un grand malade d’avoir poussé jusque-là. M’enfin, comme pour les cons, nous sommes tous le malade/con d’un autre. 🙂
Ouvrer le fichier présent dans le répertoire Report.
Une fois ouvert, changer la source de données. Sinon vous allez avoir une erreur ODBC. Naturellement les drivers ODBC pour SQLite ont été installé préalablement sinon c’est la mort assurée…
Depuis l’application PowerBI, Fichier > Options et paramètres > Paramètres de la source de données.
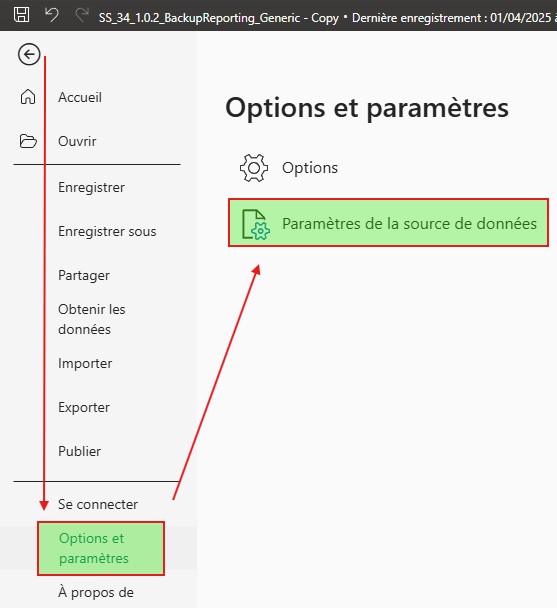
S’affiche à vous la configuration où charger les données. Il y a de forte chance que vous vous retrouviez avec l’un de mes Paths. Changer alors le chemin pour pointer vers votre BDD.
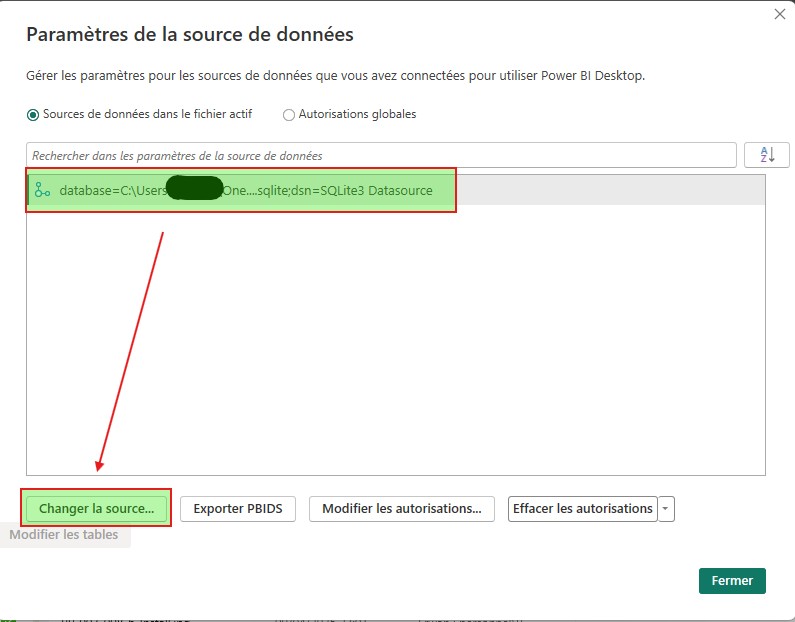
Dans la nouvelle fenêtre qui apparait, en premier lieu sélectionner en source de données SQLite3 Datasource. Modifier le chemin afin que celui soit de la forme database=<path>.
En guise de clause de réduction de ligne, choisissez LIMIT, puis confirmer la modification.
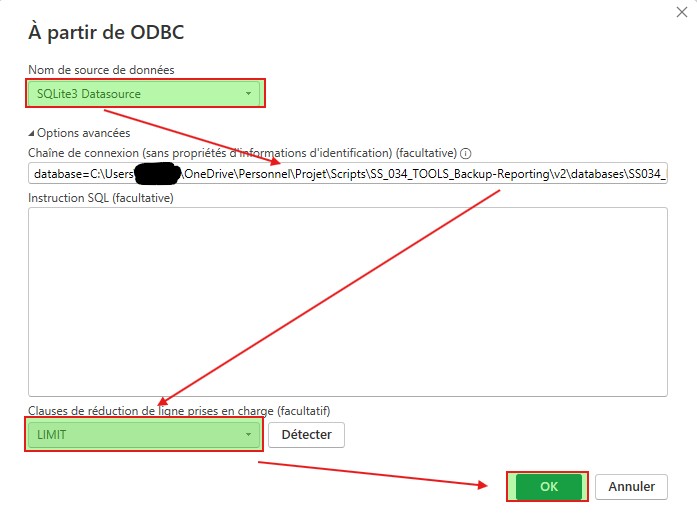
Il ne reste alors qu’à charger, actualiser les données dans le rapport existant.
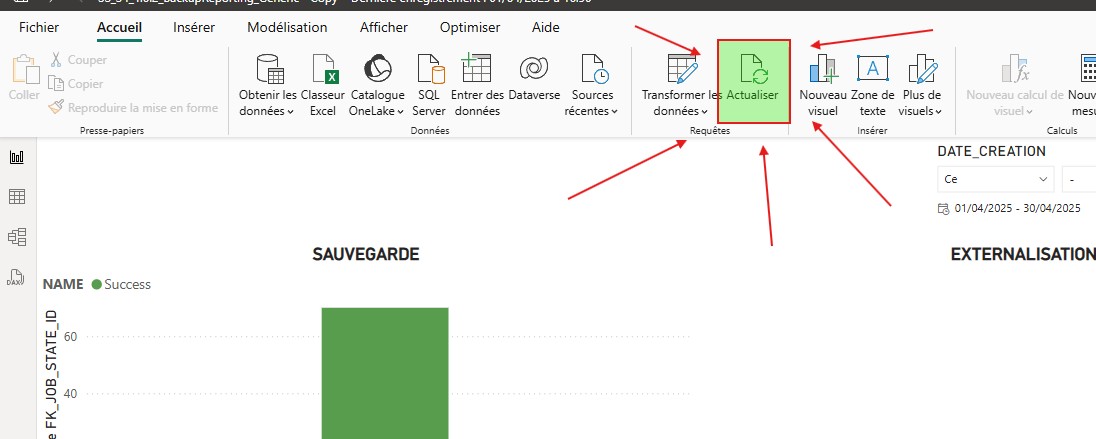 | 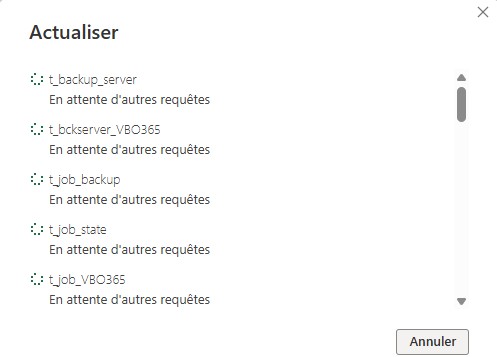 |
Normalement et il y a peu de chance que ce ne soit pas le cas, vous devriez avoir une multitude de coche vert en face de chaque table vous annonçant que les données ont été chargé avec succès.
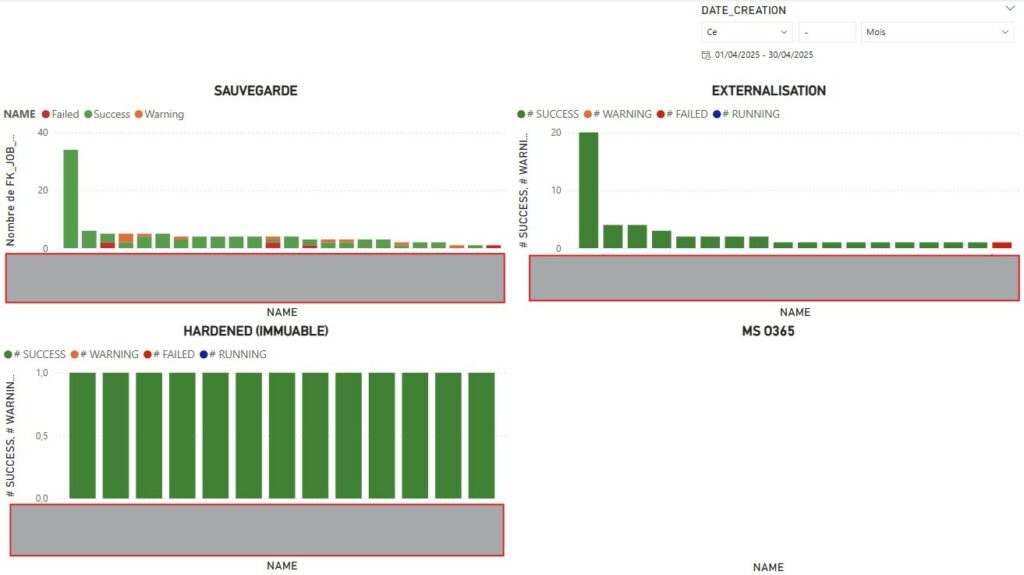
Une fois les données actualisées, vous devriez avoir le rendu ci-dessous par défaut. Il vous faudra alors jouer avec les différents filtres et objets de contrôles sur les pages pour coller à vos données.
 Simulation Data
Simulation Data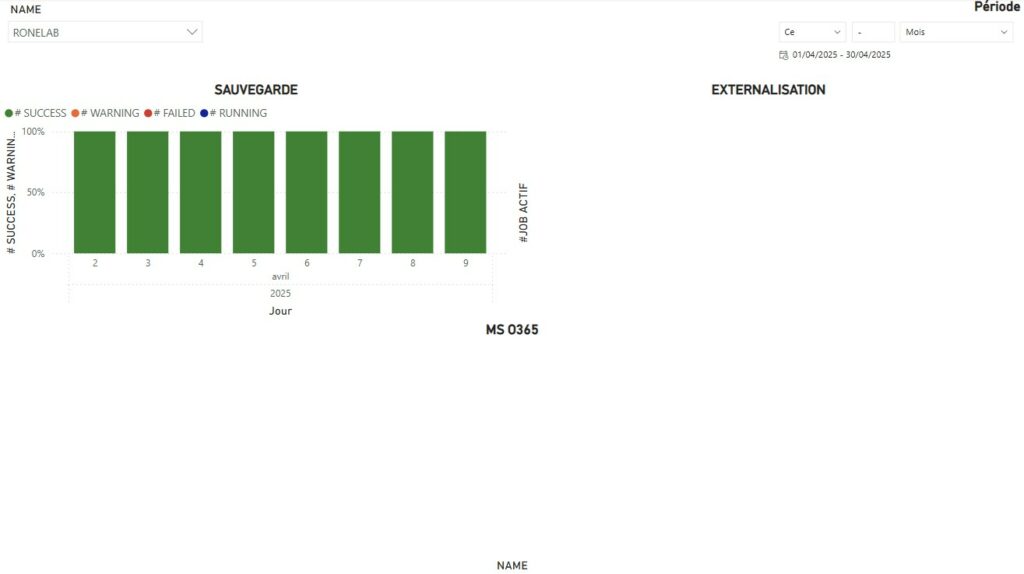 Global View
Global View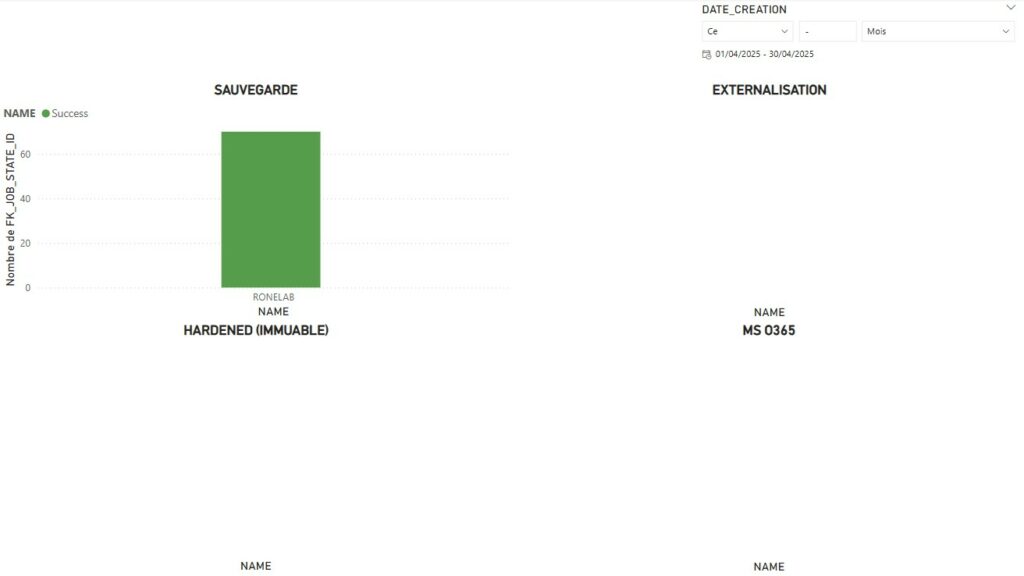 Global View By Customers
Global View By Customers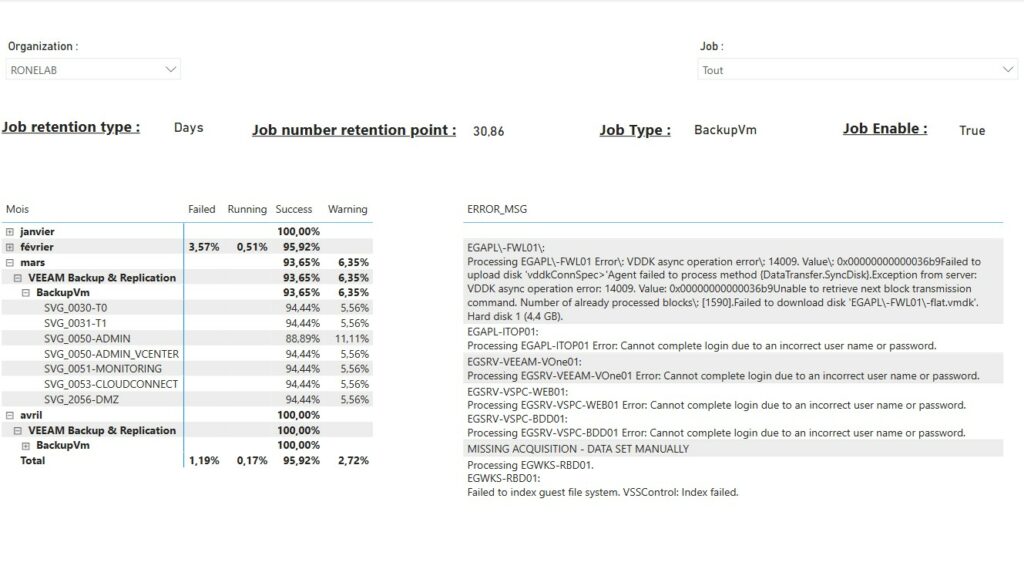 Summary
Summary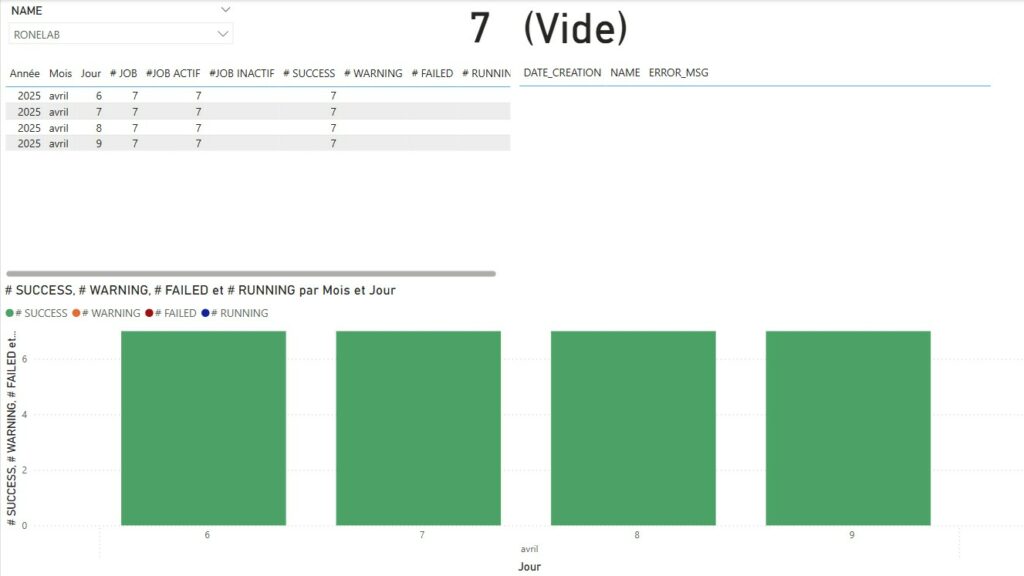 Current Week
Current Week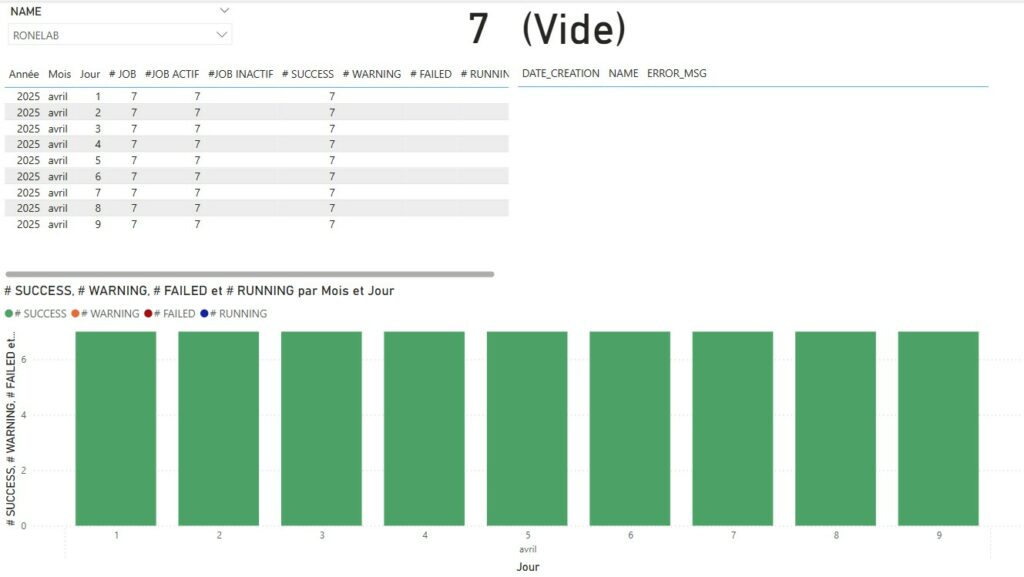 Current Month
Current Month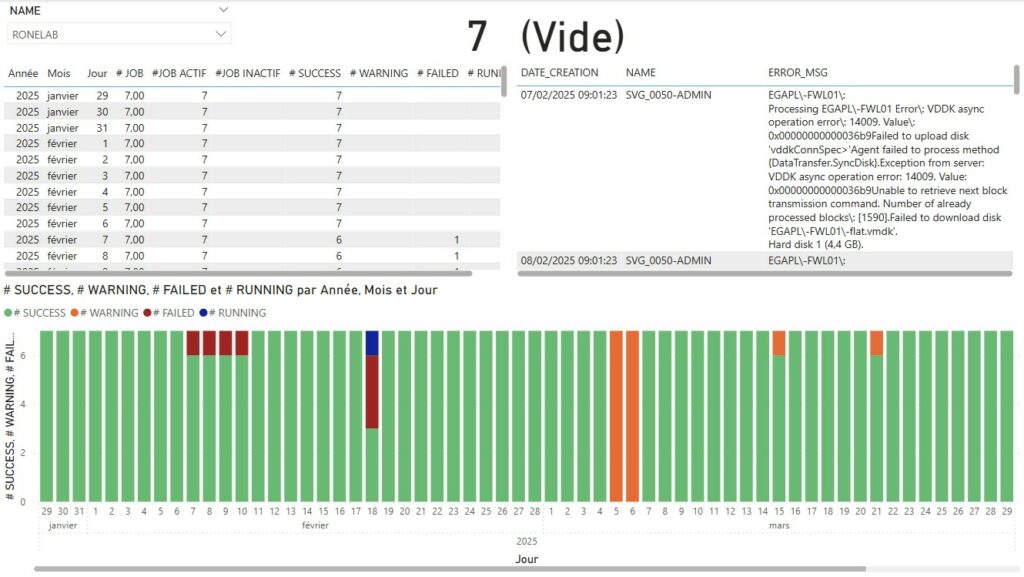 Current Year
Current Year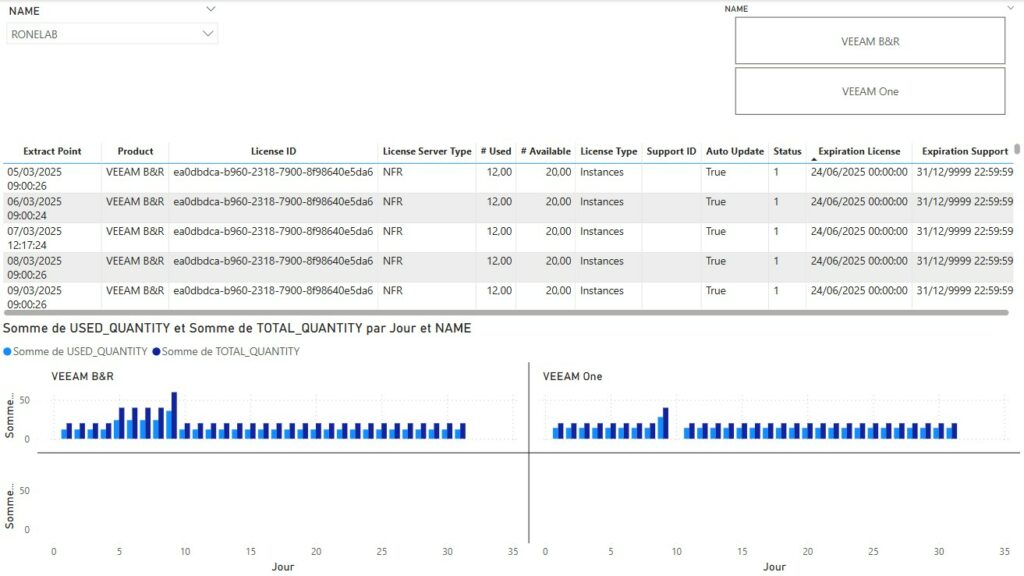 License Inventory
License Inventory
Si nous revenons à la problématique initiale, l’ensemble des points ont été traité. Au delà de l’aspect graphique qui permet rapidement d’avoir une visibilité de la compliance ou non des jobs de protection sur une période donnée, il sera nécessaire de jouer avec les filtres sur les pages afin de choisir :
- Le nom de l’organisation
- Le job ou l’ensemble des jobs concernés
Les graphiques ou charts pour nos amis anglophones c’est un fait. Mais je préfère cette vue.
Nous avons ainsi une visibilité mensuelle pour l’ensemble des jobs de protection pour une organisation. Comme évoqué précédemment, il est possible de jouer avec les filtres pour définir une organisation ou un job spécifique.
J’ai volontairement ajouté en parallèle les messages pour les états or Success facilitant ainsi le reporting ainsi que les actions à engager.
Concrètement, mon SI à la maison est loin des 98% de disponibilités que je me suis fixé. (Dois je envisager de former et d’embaucher mes enfants à réaliser le MCO de l’infra maison ? Une tablette de chocolat Lindt 85% /semaine exonérée de taxe ça devrait le faire 🙂 )
Dans la partie 3, je vais simplement résumer en une vidéo, la partie installation ainsi que la partie exploitation. Toutefois, je pense que cette dernière partie arrivera plus tard.
Pour le coup, il me faut un break, il me faut un kit kat. J’ai pas mal charbonné pour ne pas dire souffert pour accoucher de cet article. J’ai surestimé mes capacités et d’une fièvre créative, j’ai mené deux projets de grosse envergure qui m’ont bien fatigué. A ce moment précis, il se passe un mois et demi entre la version béta et la rédaction du billet. Mais voyez vous, je crois que je tiens quelque chose qui pourrait plaire à beaucoup de SysAdmin et je serai heureux de faire vivre cette petite application…
Sources
| Partie 1 : Théorie <— | PROJET – Green Ray | Partie 3 : Démonstration —> |
- MO : Mode Opératoire ↩︎
- TLS : Transport Layer Security ↩︎
- ODBC : Open Database Connectivity ↩︎
- DB : Database ↩︎
- VSPC : VEEAM Service Provider Console ↩︎
- API : Application Programming Interface ↩︎
- SMTP : Simple Mail Transport Protocol ↩︎
- URL : Uniform Resource Locator ↩︎
- LD : Liste Distribuée ↩︎
- BAL : Boite aux lettres ↩︎
- FQDN : Fully Qualified Domain Name ↩︎
- gMSA : Group Managed Service Accounts ↩︎
- CLI : Command Line ↩︎
- ISE : Integrated Scripting Environnement ↩︎
- MLD : Modèle Logique des Données ↩︎